


Smart Factories: Artificial Intelligence and Automation for Reduced OPEX in Manufacturing
DataRobot and Snowflake Jointly Unleash Human and Machine Intelligence Across the Industrial Enterprise Landscape
The “Fourth Industrial Revolution” was coined by Klaus Schwab of the World Economic Forum in 2016. This “revolution” stems from breakthrough advancements in artificial intelligence, robotics, and the Internet of Things (IoT). As a result of these technological advancements, the manufacturing industry has set its sights on artificial intelligence and automation to enhance services through efficiency gains and lowering operational expenses. This vision is being realized through use cases including:
Real-Time Predictive Maintenance — As manufacturing plants start to inject autonomous machines into their day-to-day operations, there is a growing need to monitor these devices and forecast maintenance requirements before failure and downtime.
Time-Series Forecasting — Over the past two years our supply chain has been in the spotlight. With time-series forecasting, organizations can predict future demand and hit their targeted delivery deadlines. This is currently a widespread strategy across the industry where we are seeing companies move from reactive to predictive inventory management and capacity planning.
Factory Monitoring — Manufacturers are attempting to monitor their facilities in near real-time. By utilizing artificial intelligence, organizations can dissolve production bottlenecks, track and minimize/maximize critical KPIs like scrap rate and production rates, and get ahead of the power curve to accelerate their distribution and delivery channels.
These initiatives utilize interconnected devices and automated machines that create a hyperbolic increase in data volumes. This type of growth has stressed legacy data management systems and makes it nearly impossible to implement a profitable data-centered solution. With Snowflake and DataRobot, organizations can capture this data and rapidly develop artificially intelligent applications that immediately impact the bottom line.
Leveraging Snowflake and DataRobot for Speed and Scale
With Snowflake’s newest feature release, Snowpark, developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional data engineering and machine learning life cycles.
Python is unarguably the most broadly used programming language throughout the data science community. With, now, native Python support delivered through Snowpark for Python, developers can leverage the vibrant collection of open-source data science and machine learning packages that have become household names, even at leading AI/ML enterprises. And of course, this can all be accessed in DataRobot’s multi-tenant managed notebook experience, DataRobot Core.
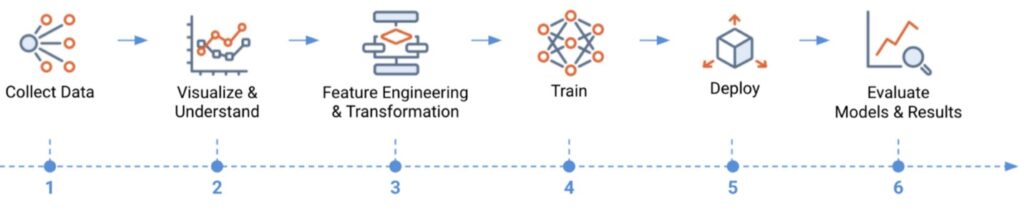
By enabling data scientists to rapidly iterate through model development, validation, and deployment, DataRobot provides the tools to blitz through steps four and five of the machine learning lifecycle with AutoML and Auto Time-Series capabilities. When a team chooses a model they would like to take to production, they can ship that model to Snowflake as a User-Defined Function in a matter of clicks and begin inferencing against high-velocity data leveraging Snowflake for the compute under the hood. As these models make inferences, DataRobot’s MLOps offering allows teams to monitor these models and create downstream triggers or alerts based on the predictions. It is also incredibly easy to schedule batch prediction jobs that write results out to a Snowflake table or hit the deployment from an API endpoint for real-time inferencing.
In this example, I walk through how a manufacturer could build a real-time predictive maintenance pipeline that assigns a probability of failure to IoT devices within the factory. The goal is to react before the point of failure and reduce costly downtime on the assembly line.
IoT Empowered Assembly Lines: Predictive Maintenance
One of the high-impact use cases prevalent in the manufacturing industry is predictive maintenance. With Snowflake and DataRobot, organizations can build and deploy an end-to-end solution capable of predicting machine failure in a matter of hours—a problem that even five years ago would have taken months, often requiring a team of PhD data scientists, engineers, a Docker and Kubernetes expert, and personnel from IT among others.
The first step in building a model that can predict machine failure and even recommend the next best course of action is to aggregate, clean, and prepare data to train against. This task may require complex joins, aggregations, filtering, window functions, and many other data transformations against extremely large-scale data sets.
Native Python Support for Snowpark
The snippet below highlights how a data scientist, in the context of predicting device failure, could quickly connect to Snowpark and join an IoT device table with a table containing the descriptions of each device.

(https://gist.github.com/nickalonso57/66cc438a8394b822ea4d20e5bc8259c5) – GitHub Gist
Train, Compare, Rank, Validate, and Select Models for Production
After data has been prepared and is ready to model against, users can leverage DataRobot to rapidly build and test models to predict if a machine will fail and require maintenance. This can be done programmatically through an API or in a point-and-click GUI environment. In DataRobot’s GUI, all a user has to do is define what variable they would like to predict and click start. DataRobot will automatically perform a data quality assessment, determine the problem domain to solve for whether that be binary classification, regression, etc., and recommend the best optimization metric to use.
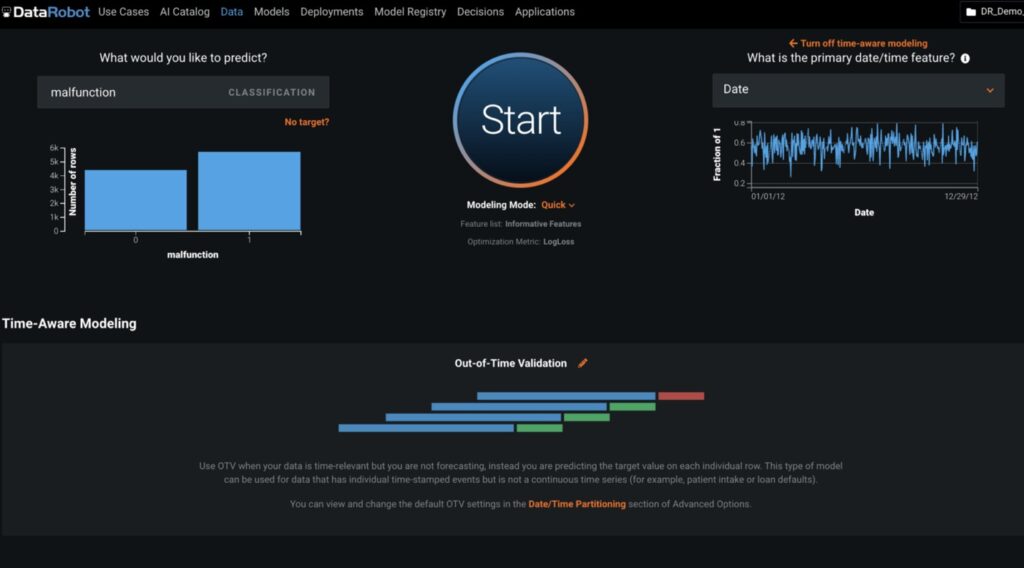
In this example, a user would define the target variable as “malfunction.” DataRobot automatically recognizes that this is a binary classification problem and detects time-series data within the training set. In this case, the user would not be forecasting against a series but rather predicting whether the machine is bound to fail. This is referred to as time-aware modeling which takes into account the date/time feature in the data set and uses out-of-time validation (OTV) to help train the candidate classification models.
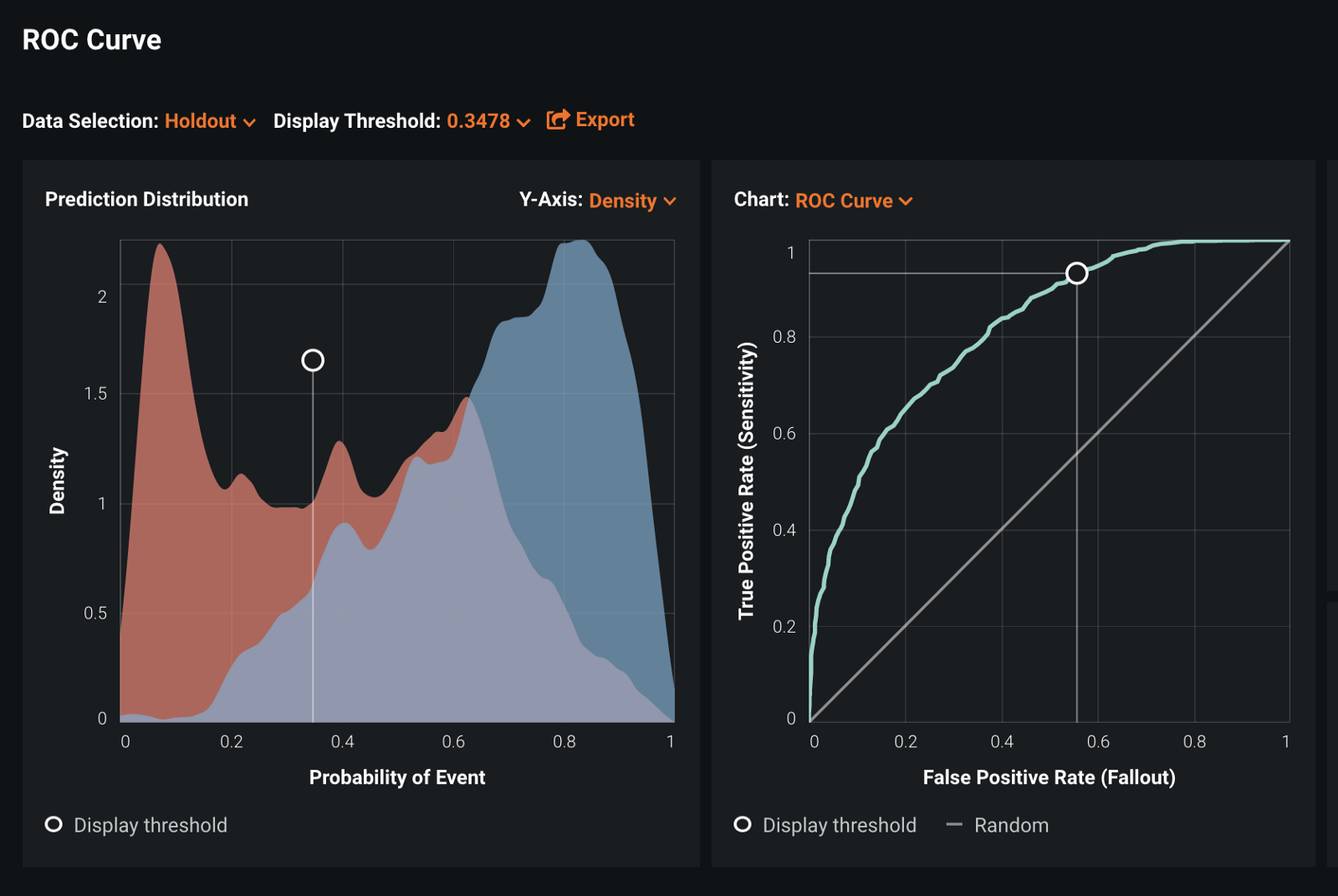
There are also advanced options for defining hyper-parameter tuning, CV partitioning schemes, and bias/fairness guardrails that give flexibility and control of the modeling approach to expert data scientists. Once a user clicks start, DataRobot will begin training a variety of models, pinning them head-to-head and ranking them by performance and accuracy. DataRobot provides intuitive built-in tools to explore and validate each model including feature impact, ROC-Curves, lift charts, prediction explanations, and more.
Deploying a Model and Consuming the Inferences
After a model has been selected for production, most data science teams are faced with the question of “now what?” There typically is not a repeatable and standardized approach for deploying models to production and usually requires a lot of ad-hoc work between the development team, IT, and project stakeholders. The underlying infrastructure usually needs to be provisioned and configured, the model needs to be documented, reviewed, and approved, and ongoing maintenance and monitoring turn into a very manual and tedious effort.
DataRobot provides a push-button deployment framework with automatically generated compliance documentation, data drift and accuracy monitoring, continuous retraining, and challenger analysis. Users can define prediction jobs that write results to Snowflake tables on a scheduled basis. DataRobot will automatically create a table in Snowflake and write the prediction results out to that table as inferences are made.
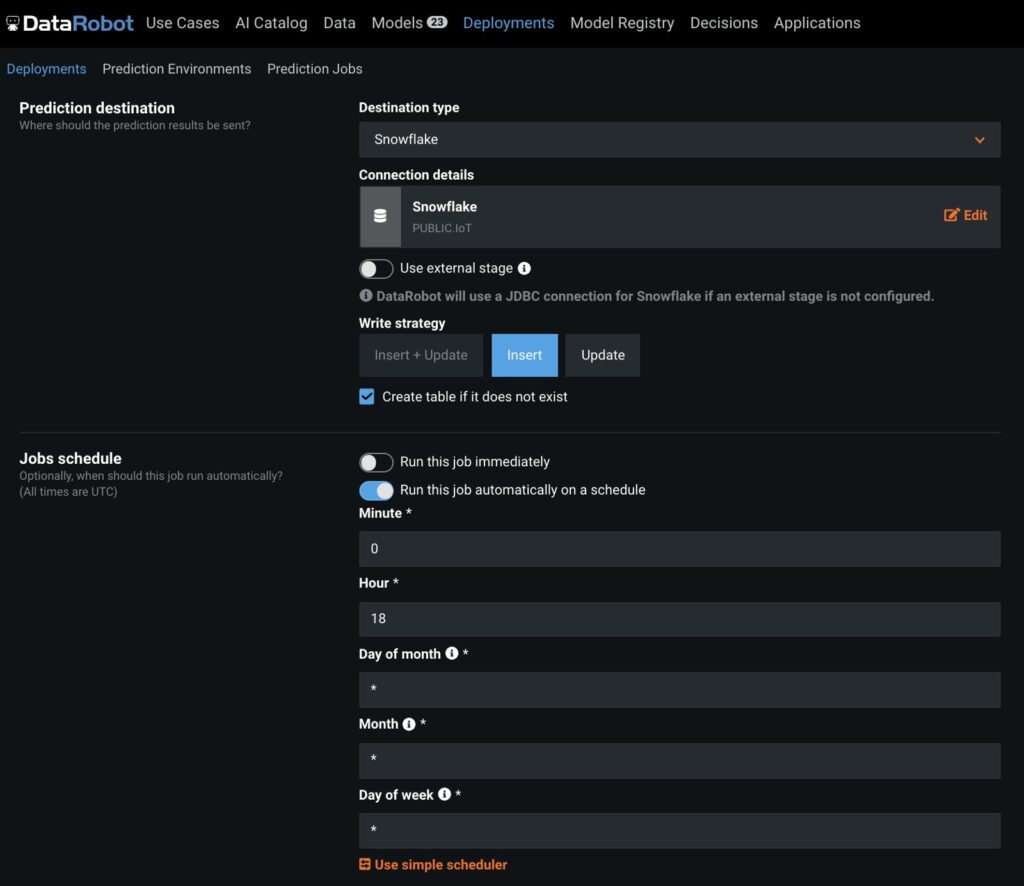
After this job has been defined, the model is ready to start consuming data and making predictions on whether a machine is likely to fail and require maintenance. There are several approaches a team could take in designing the end-to-end architecture that would solve this problem. It really would come down to the desired latency and performance they were looking to achieve. For batch inferencing, these jobs can be run as often as every minute. In some cases, that may not be fast enough and a manufacturer may need near-real-time or real-time decision making.
In this instance, DataRobot provides the ability to hit the deployment from an API endpoint with sub-second latency for fast decision-making based on these predictions. Other considerations a team may take into account are the sources of their data and how they are moving and monitoring that data in real-time. If a manufacturer was continuously monitoring equipment in their factory and the goal was to continuously make predictions on whether these machines were likely to fail, a powerful message bus like Confluent would be ideal for moving those device readings into Snowflake. As that data lands and predictions are made, we can see the failure probabilities assigned to each device in the first two columns of the resulting table.
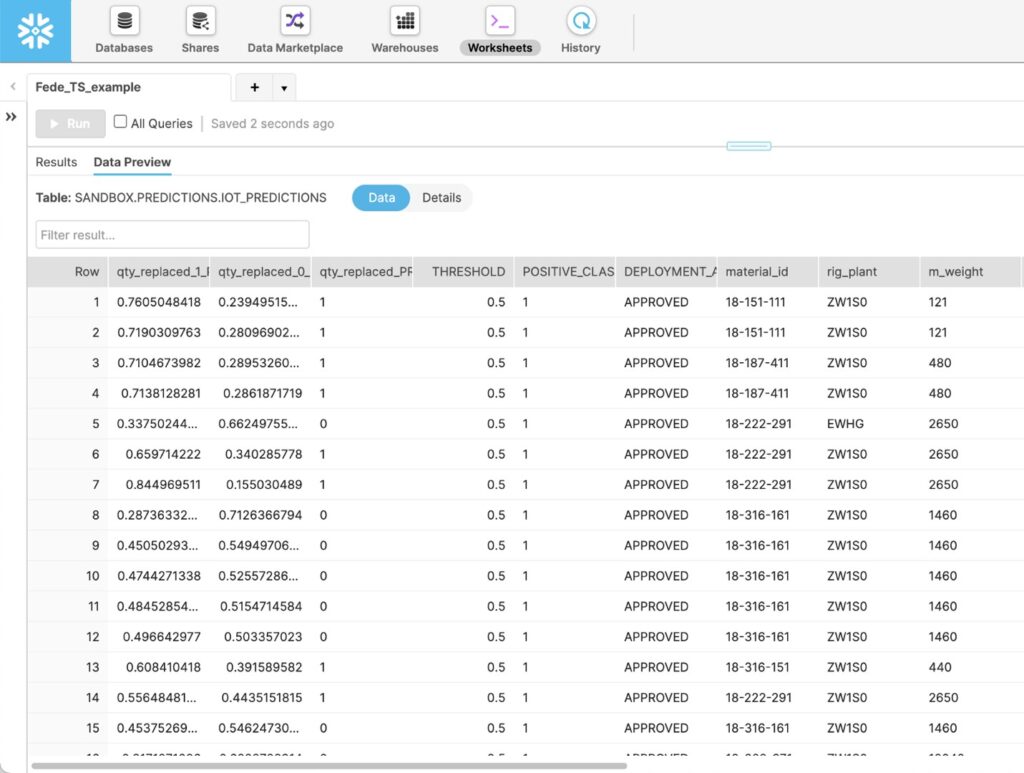
Consuming AI/ML Insights for Faster Decision Making
From here, the goal is to take preventative action. For any devices that have a high probability of failure, a manufacturer would want to prescribe a solution to prevent costly downtime. This is where the results of a machine learning model could be fed into further downstream analytics and automation. For example: in this context, we could extract the devices that had a high probability of failure and make the next best action recommendation. That may be something as simple as automatically adjusting the temperature or pressure of the machine, or it may be an alert to a technician or engineer to respond on-site.
More Information
If you have any questions on getting started or how you could better leverage your existing Snowflake footprint, feel free to reach out to me directly and I’d be happy to brainstorm.
nicholas.alonso@datarobot.com | https://www.linkedin.com/in/nickalonso/
Check out how Snowflake and DataRobot unleash the power of the Data Cloud with AI.

-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
