


Improving Model Management in Uncertain Times
With the continued unfolding of the COVID-19 pandemic, the world’s economies and societies are going through an extended period of uncertainty. This ongoing volatility brings new challenges for organizations and teams managing predictive models.
It’s tricky to maintain a grip on production model management and monitoring under normal circumstances. The current turbulent times highlight this issue even further, with models experiencing decay at an accelerated rate, wreaking havoc on business-critical processes that rely on predictions. Accessing your ability to manage model risk and model monitoring becomes vital for data science and IT teams overseeing these models, as well as business stakeholders who rely on these predictions.
In a recent webinar titled Managing Models in Uncertain Times, we highlight some of the essential practices and tools which cover various stages of model risk and model monitoring management — a concept commonly known as ML Ops. It includes technologies and practices aimed at providing a scalable and governed means to rapidly deploy and manage ML applications in production.
ML Ops focuses on four critical areas of investment for organizations monitoring their production models:
- Deployment: the convergence of data science and IT teams aimed at publishing a machine learning model into an existing production environment
- Monitoring: the process of assessing model performance and quality over time by monitoring for service health, accuracy, data drift, and many other critical metrics about the model
- Machine learning lifecycle: tools and techniques around model retraining, the testing of champion-challenger models, automated replacement and ongoing maintenance to ensure the continuous performance of the existing production models
- Governance: sets the rules and controls for machine learning models running in production, including approval workflows, access control, change and access logs, and traceability of model results.

Making investments in all of these areas allows enterprises and their models to be less susceptible to volatile events, like market crashes, rapid regulatory changes, and other events like the ongoing pandemic. On top of it all, ML Ops improves productivity and happiness of data science teams by allowing them to focus on the actual model ROI, not its behavior in the wild.
ML Ops seeks to centralize and automate a lot of the manual processes involved in deploying and monitoring models. This, in turn, minimizes the potential risks around model deployment and streamlines the manual components of the process.
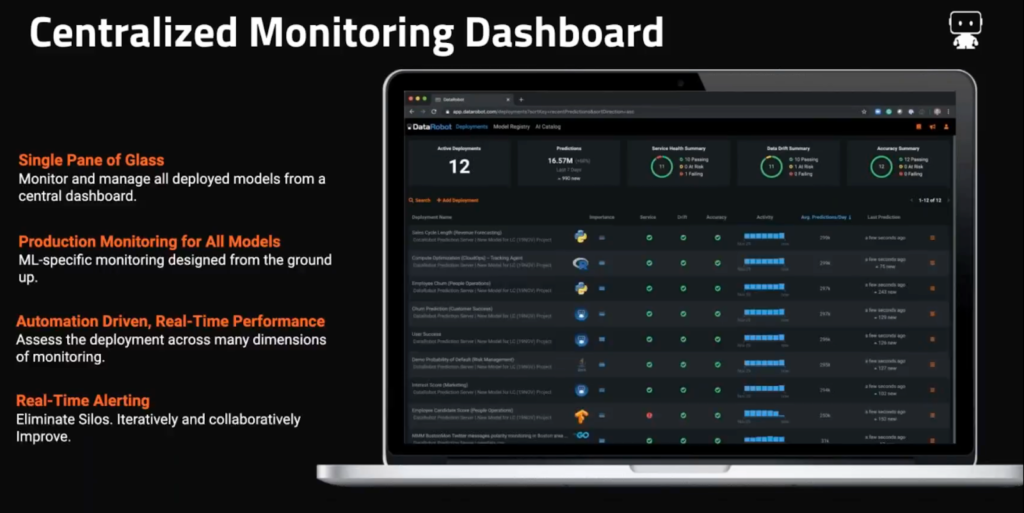
There’s an abundance of issues that a coherent and comprehensive ML Ops framework can solve, such as:
- Data drift occurs when training data and the production data change over time such that the model loses predictive power. But it can also be abrupt or gradual. Therefore, it’s crucial to be able to detect the pattern and correct it, while it hasn’t yet disrupted the production model’s performance.
- Service issues can always disrupt machine learning pipelines, from run-time errors, data error, and system outages to system throughput and cache load issues.
Move Fast, Fix Things
And this is just the tip of the ML Ops iceberg. ML Ops tools have to be able to alert stakeholders about important model behaviors, like potential data drift. In turn, these alerts need to integrate with communication systems, like Slack and email.
Also, many of the ML Ops processes revolve around model assessment and candidate model management, with continuous evaluation and retraining of existing models, as well as ongoing A/B testing of the existing model inventory. All of this should be organized with a human in the loop. That ensures the performance, compliance, and stability of the system.
Learn more about how ML Ops can help lower management and business risks around production models by watching the full on-demand webinar.
After that, you can check out results from some polls we ran during the webinar or followup with us and other community members through this community discussion in the Research Center

As the head of Model Risk Management at DataRobot, Seph Mard is responsible for model risk management, model validation, and model governance product management and strategy, as well as services. Seph is leading the initiative to bring AI-driven solutions into the model risk management industry by leveraging DataRobot’s superior automated machine learning technology and product offering.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
