

All Data Drift is Not Created Equal…
Predictive models learn patterns in training data and use that information to predict target values for new data. There are two data sets at play in this process, the training data and the scoring or inference data. The model will work well in production (i.e., produce accurate predictions in line with expectations) when the new inference data is similar to the training data. When these two data sets are different, however, the model can become less accurate and produce unexpected results. Luckily, this is something that usually happens over time, so you have a chance to catch these issues if you are paying attention.
When the training data and the production data change over time such that the model loses predictive power, the data surrounding the model is said to be drifting. Data drift can happen for a variety of reasons, including data quality issues, changes in feature composition, and even changes in the context of the target variable. When you believe that your data drift is impacting model accuracy, you will need to take action to retrain or rebuild the model. These actions are expensive for most teams because they require data scientists to put aside the projects they are working on to retrain and test the production model. This process is distracting for the data scientists and uses computational resources that could work on other problems.
Monitoring for machine learning is a balancing act. When you alert your operations and data science teams, they need to take appropriate action. If, however, you bombard your teams with alerts that are not meaningful or worse, are based on false positives, then they will quickly start to ignore these warnings, which will lead to an issue when something truly critical comes up. So, you need to make sure that you don’t only detect issues, you also identify the problems that matter.
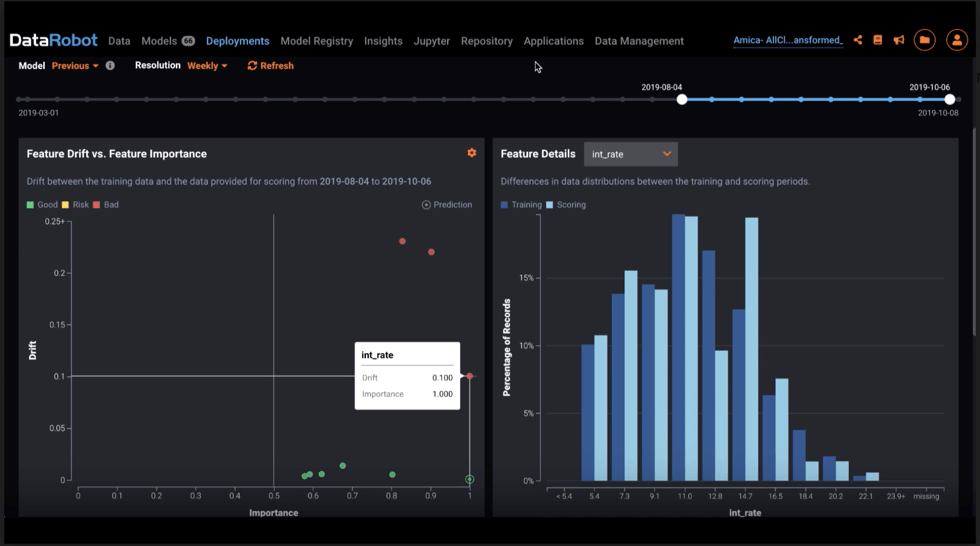
Figure 1: Feature level drift chart. Note the differences between training and scoring data.
Data drift detection will tell you that one or more of your model’s features or the target have changed in a significant way between training and inference. Before you take action, however, you want to know if the feature in question is essential to your model’s accuracy.
Feature importance tells you which features in your model are the most important in making the prediction. You may have hundreds of features, but only a few will have a significant impact on your results. A variety of methods exist to determine which features are essential to your model. These techniques will typically run through an iterative process to determine the relationships between features and the relationship of each feature to the target variable and the likely contribution of each feature to the model’s predictions. While computationally intensive, this process clearly shows how each feature impacts the overall accuracy of the model.
Figure 2: Feature Drift vs. Feature Importance
Feature importance matters when you are thinking of data drift. Your data science resources are expensive in terms of people and compute time. You want to engage your data science team when their efforts improve production model performance.
DataRobot MLOps allows organizations to deploy, monitor, manage and govern production models built using a variety of leading programming languages and frameworks such as Python, R, Java, Go, and Scala. For each of these models, DataRobot MLOps provides robust monitoring for data drift and computes the feature importance using proven techniques. To access this robust set of capabilities, all the user has to do is drag and drop or import training data into the system. There is no coding or specific knowledge of any of the calculations or techniques required. With both data drift and feature importance together, your operations team can quickly see production data drift for a feature that will likely impact the accuracy of predictions.
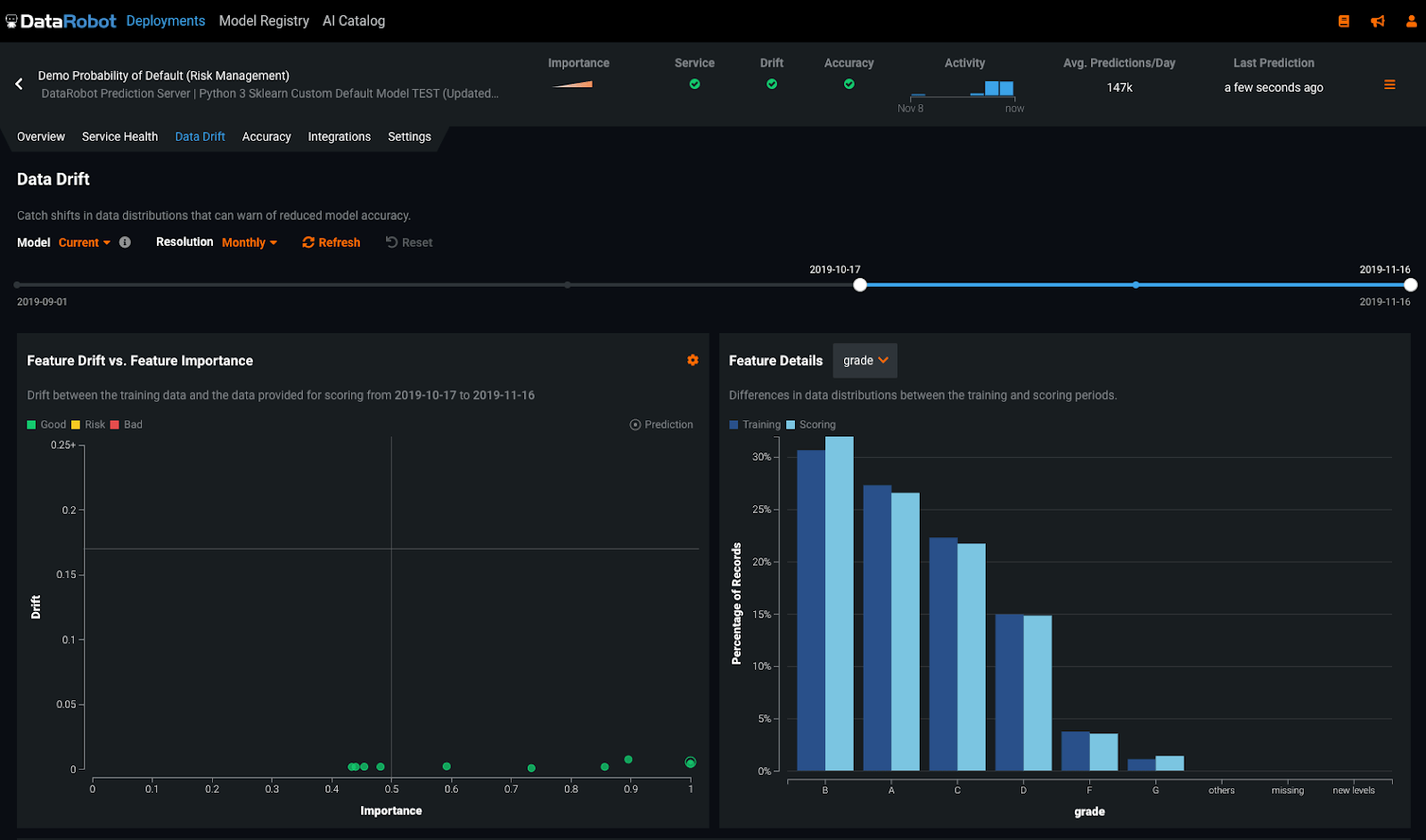
Figure 3: Feature Importance and Drift in DataRobot MLOps
This combination of data drift and feature importance has a couple of advantages. First, your operations team is alerted when there are likely to be real problems, helping you avoid alert fatigue. Second, when your operators ask your data science team to rebuild a model, that work is needed and makes the best use of your valuable resources.
Learn more about DataRobot MLOps here.


Dan has been working in the analytics space for almost 20 years with the last eight years focused on machine learning technology. He holds an MBA from Carnegie Mellon University and a degree in Architectural Engineering from the University of Colorado at Boulder.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
