


Can You Estimate How Long It Will Take McLaren Formula 1 Team to Complete a Race Through ML and Human Intelligence?
Are you new to Formula 1? Want to learn how AI/ML can be so effective in this space? 3. . . 2. . .1. . . Let’s begin! F1 is one of the most popular sports in the world and is also the highest class of international racing for open-wheeled single-seater formula racing cars. Made up of 20 cars from 10 teams, the sport has only become more popular after all the recent documentaries on drivers, team dynamics, car innovations, and the general celebrity level status that most races and drivers receive across the world! Additionally, F1 has a long tradition of pushing the limits of racing and continuous innovation and is one of the most competitive sports on the planet – which is why I like it even more!
So how can AI/ML help McLaren Formula 1 Team, one of the sports oldest and most successful teams, in this space? And what are the stakes? Each race, there are a myriad of critical decisions made which impacts performance— for example, with McLaren, how many pit stops should Lando Norris or Daniel Ricciardo take, when to take them, and what tyre type to select. AI/ML can help transform millions of data points that are being collected over time from cars, events, and other sources into actionable insights that can significantly help optimize operations, strategy, and performance! (Learn more about how McLaren is using data and AI to gain a competitive advantage here.)
As an avid F1 racing viewer, data enthusiast, and curious person that I am, I thought – what if we could leverage machine learning to predict how long a race will take to finish as the first hypothesis?
- Based on some strategic decisions can I reliably and accurately estimate how long will it take for Lando Norris or Daniel Ricciardo to complete a race in Miami?
- Can machine learning really help generate some insightful patterns?
- Can it help me make reliable estimates and race time decisions?
- What else can I do if I did this?
What I am going to share with you is how I went from using publicly available data to building and testing various cutting edge machine learning techniques to gaining critical insights around reliably predicting race completion time in less than a week! Yes – less than a week!

The How – Data, Modeling, and Predictions!
Racing Data Summary
I started by using some simple race level data that I pulled through the FastF1 API! Quick overview on the data — it includes details on race times, results, and tyre setting for each lap taken per driver, and if any yellow or red flags occurred during the race (a.k.a. any uncertain situations like crashes or obstacles on course). From there, I also added in weather data to see how the model learns from external conditions and whether it enables me to make a better race time estimate. Lastly, for modeling purposes, I leveraged about 1140 races across 2019-2021.
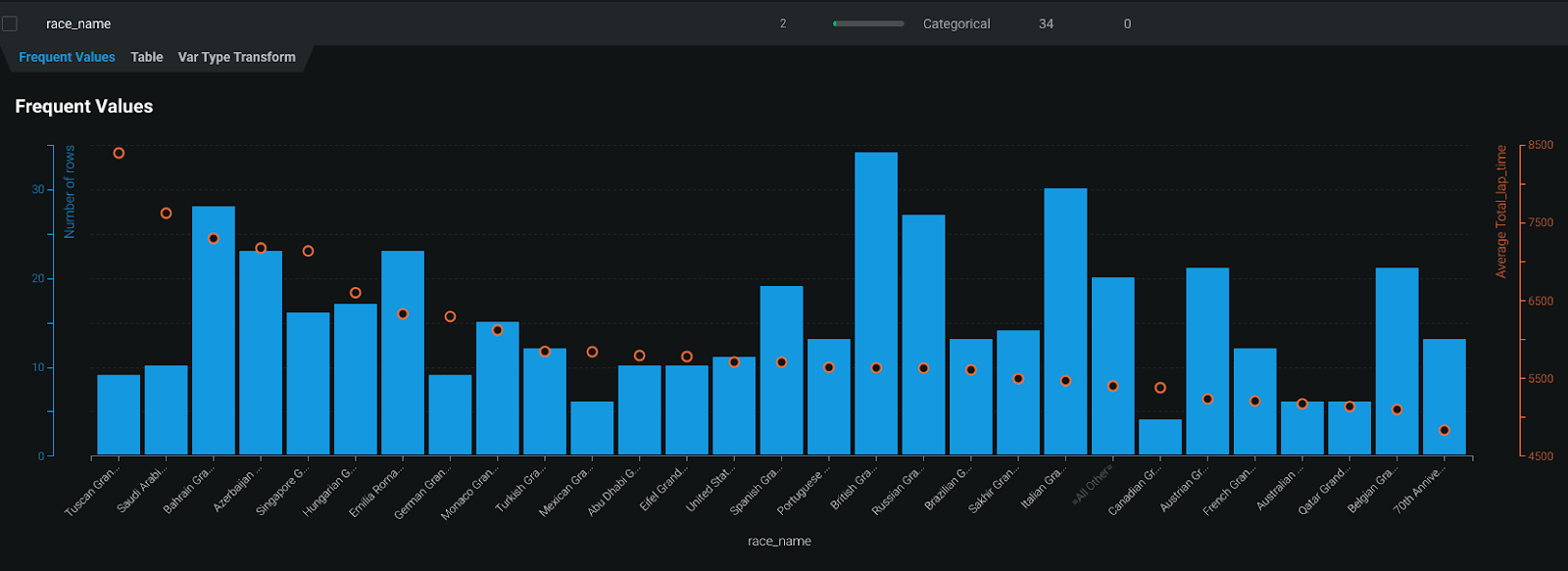
Visualizing the distribution of completion time across different circuits — Seems like the Emilia Romagna GP takes the longest, while the Belgian GP is typically shorter in race time (despite being the longest track on the calendar).
Race Time Estimation Modeling
Key Questions – What algorithms do I start with? A lot of data is not easily available— for example, if there was a disqualification, or crash, or telemetry issue, sometimes the data is not captured. What about converting the raw data into a format that will be easily consumed by the learning algorithms I am typically familiar with? Will this work in the real world? These are some of the key questions I started thinking about before approaching what comes next. One of the first questions is, what is Machine Learning Doing Here? Machine learning is learning patterns from historical data (what tyre settings were used for a given race that led to faster completion time, how did drivers perform during different seasons, how did variations in pit stop strategy lead to different outcomes, and more) to predict how long a future race will take to complete.
Process – Typically, this process can take weeks of coding and iterations — processing data, imputing missing values, training and testing various algorithms, and evaluating results. Sometimes even after coming up with a good model — I only realize later that the data was never a good fit for the predictions or had some target leakage. Target Leakage happens when you train your algorithm on a dataset that includes information that would not be available at the time of prediction when you apply that model to data you collect in the future. For example, I want to predict whether someone will buy a pair of jeans online, and my model recommends it to them only because they are going through the checkout process — well that is too late because they are already buying the jeans — a.k.a. lots of leakage.
My approach – To save time on iterations, I can also leverage automation, guardrails, and Trusted AI tools to quickly iterate on the entire process and tasks previously listed and get reliable and generalizable race time estimates.
Start – Me clicking the start button to train and test hundreds of different automated data processing, feature engineering, and algorithmic tasks on racing data. DataRobot is also alerting me on issues with data and missing values in this case. However, for today we will go ahead with the inbuilt expertise on handling such variations and data issues.
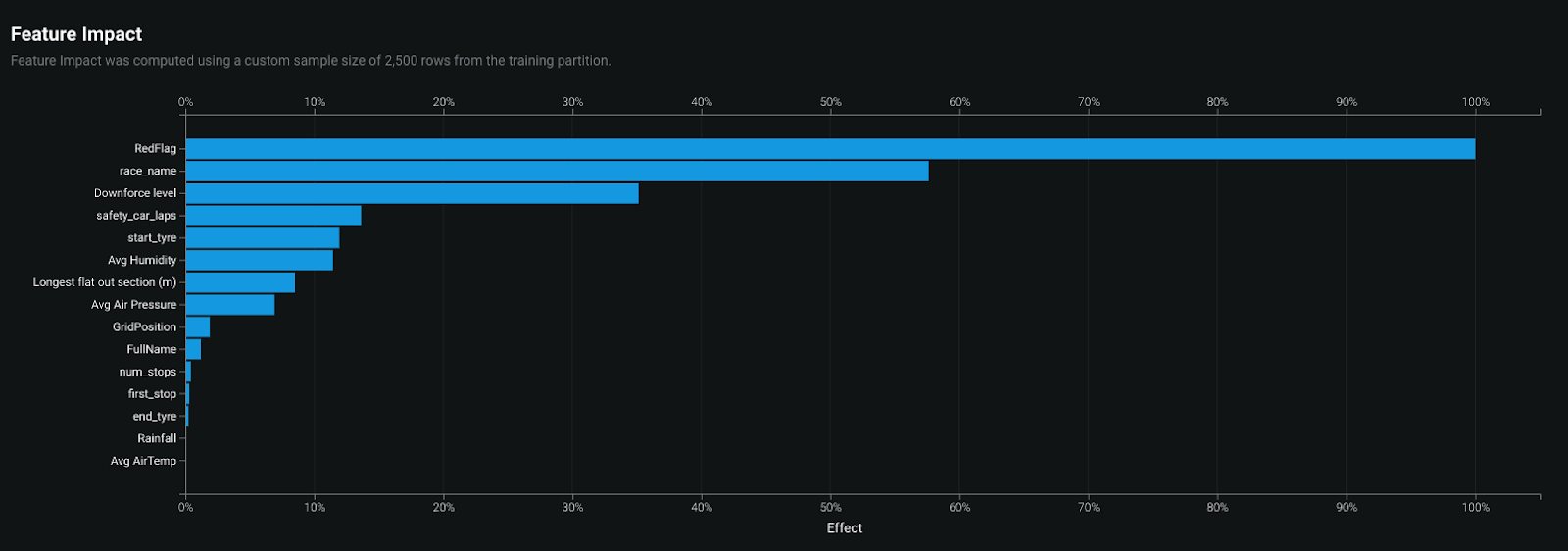
Insights – Of the hundreds of experiments automatically tested, let’s review at a high level what are the key factors in racing that have the most impact on predicting total race time — I am not McLaren Formula 1 Team driver (yet), but I can see that having a red flag, or safety car alert does impact overall performance/completion time.
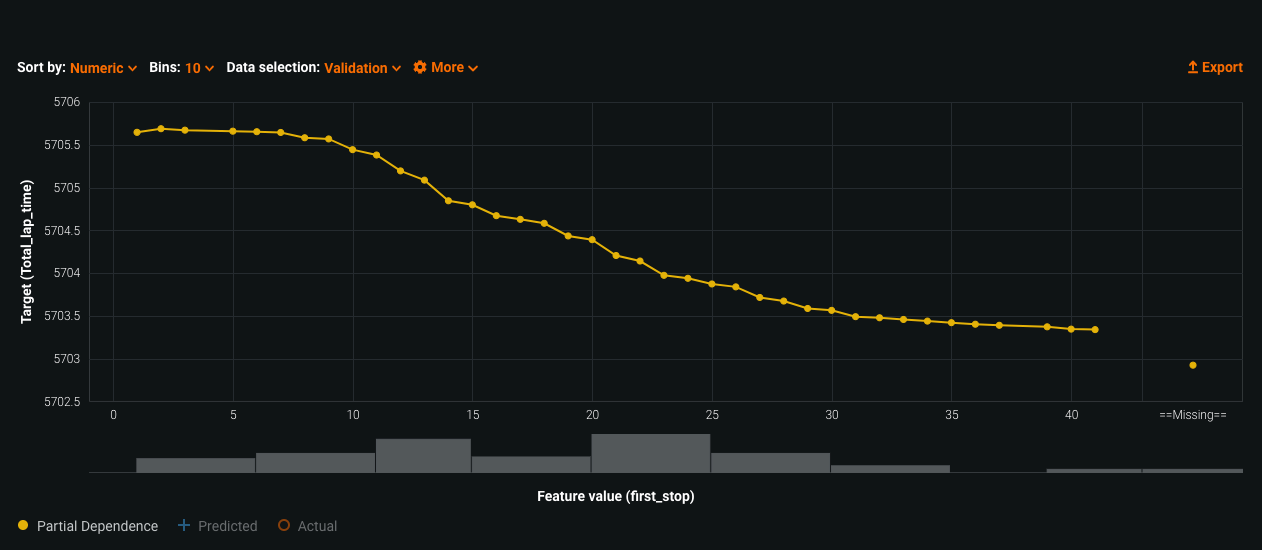
More Insights – On a micro level, we can now see how each factor is individually affecting the total race time. For example, the longer I wait to make my first pit stop (X axis), the better outcomes I will get (shorter total race time). Typically, a lot of drivers stop around the 20-25 mark for their first pit stop.
Evaluation – Is this accurate? Will it work in the real world? In this case, we can quickly leverage the automated testing results that have been generated. The testing is done by selecting 90 races that were not seen by the model during the learning phase and then comparing actual completion time versus predicted completion time. While I always think results can be better, I am pretty happy that the recommended approach is only off by 20 seconds on average. Although in racing 20 seconds sounds like a lot, and that can be the difference between P3 to P9, the scope here is to provide a reasonable estimate on total time with an error rate in seconds vs minutes— which is what the actual estimates can fall across. For example, imagine if I had to guess how long Lando Norris or Daniel Ricciardo will take to complete a race in Miami without much prior context or F1 knowledge? I definitely would say maybe 1 hour 10 minutes or 1 hour 30 minutes, but using data and learned patterns, we can augment decision-making and enable more F1 enthusiasts to make critical race time and strategy decisions.
Can’t wait to use AI models to make intelligent race day decisions – Check out the Datarobot X Mclaren App here! For more details on the use case and data, you can find more information on this post.
What’s Next
For now, I’ve built my model for 2019-2021 races. But the project is really motivating me to revisit more data sources and strategy features within F1. I recently started watching the Netflix series Drive to Survive, and can’t wait to incorporate this year’s data and retrain my race time simulation models. I’ll be continuing to share my F1 and modeling passion. If you have feedback or questions about the data, process, or my favorite F1 Team – feel free to reach out arjun.arora@datarobot.com!
Imagine how easily this can expand to over 100 AI models — what would you do?

Arjun Arora is a customer-facing data scientist at Datarobot, helping lead business transformation at global organizations through application of AI and machine learning solutions. In his prior roles, Arjun led analytics enablement for sales teams across North America and Europe, demonstrated multi million dollar in business value to clients from application of predictive analytics solutions, and enabled 100s of subject matter experts, analysts and data scientists on storytelling best practices around data science.
Arjun loves simplifying complex data science concepts and finding incremental areas for improvement. In his spare time, he loves going on hikes, volunteering for DEI initiatives and helping develop opportunities for career growth for students from his prior universities (Kutztown University and Drexel University).
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
