

Best Practices for Imbalanced Data and Partitioning
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about DataRobot, AI Platform, data science, and more.
In this two-part learning session we discuss best practices around data partitioning and working with imbalanced datasets.
Five-fold cross-validation is often the silver bullet for partitioning your validation dataset, but there are some dangerous caveats you have to be aware of to make sure that you’re building robust models. In part 1 of this learning session, we talk about those pitfalls and outline strategies for handling them.
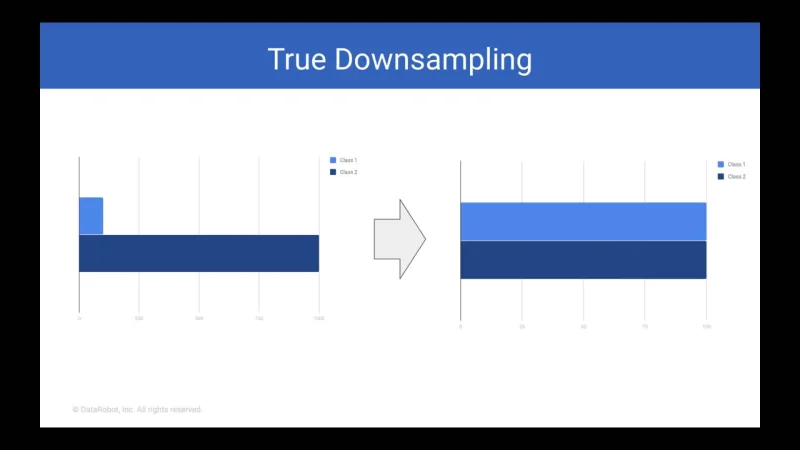
Binary target variables are very common in data science use cases, many of which are severely imbalanced. When you’re building models for infrequent events, such as predicting fraud or identifying product failures, it’s important to watch out for imbalance in your data. In part 2 of this learning session, we discuss strategies for working with imbalanced datasets and provide some rules-of-thumb for these types of use cases.
Hosts
- Matt Marzillo (DataRobot, Customer Facing Data Scientist)
- Mitch Carmen (DataRobot, Customer Facing Data Scientist)
- Jack Jablonski (DataRobot, AI Success Manager)
Now what?
After watching this two-part learning session, you should check out these resources for more information.
DataRobot Platform Documentation:

-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
