

Overfitting: What to Do When Your Model Is Synced Too Closely to Your Training Data
The main objective for many data scientists is to build machine learning models that predict the outcomes on unseen data that weren’t used in the development process. The performance of a model on unseen data is referred to as its ability to generalize and is ultimately how it will be judged. If generalization does not meet expectations, the result will be poor outcomes and possibly a reduction of stakeholder confidence in machine learning. There are a number of reasons that a model may fail to generalize, but one common culprit is something called overfitting, which will be the focus of this blog post.
The DataRobot AI Wiki defines overfitting as a model that is “too attuned to the data on which it was trained and therefore loses its applicability to any other dataset.” However, upon first read, this definition may not be clear enough, so I’ll use a scenario from everyday life to provide some intuition. Consider a student who has an upcoming exam and her teacher was kind enough to provide some study materials, including practice questions with answers. Our student pores over what the teacher has provided, memorizing each detail. When it came time to take the exam, the student copied the provided answers down faithfully and was shocked when she received a bad score. This is overfitting.
How Does Overfitting Occur?
In the example above, a poor test grade was the outcome of overfitting, but with a real-world machine learning problem, such as predicting if a loan will default, there could be very costly consequences. Therefore, it is crucial to take steps that reduce the risk of overfitting. However, before we dive into methods to control overfitting, it is important to understand how it happens in the first place.
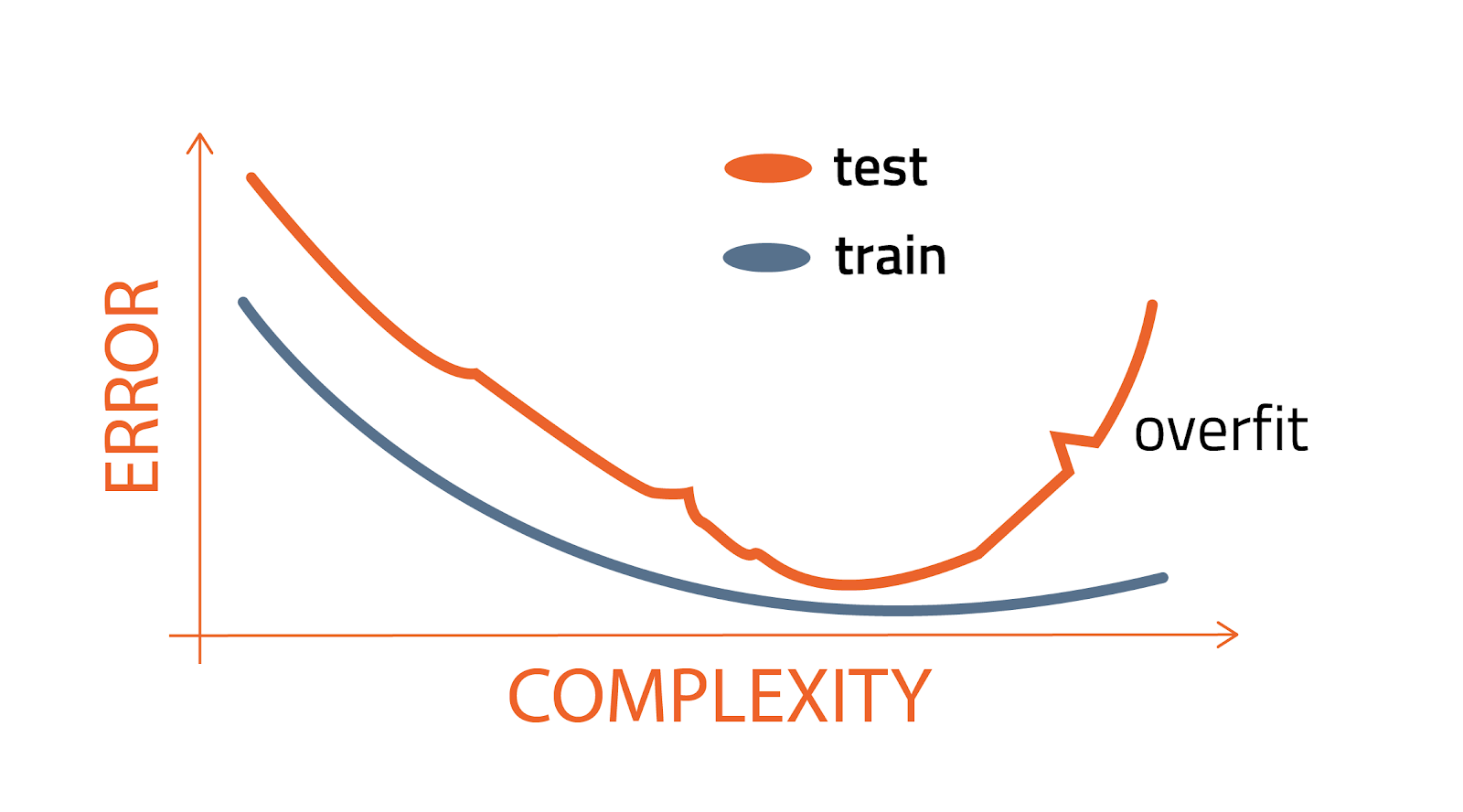
What causes overfitting?
Overfitting occurs when a model’s parameters and hyperparameters are optimized to get the best possible performance on the training data. By optimizing for error on the training data and ignoring how a model will perform outside of that sample, a machine learning model will have excellent performance on the training data and poor performance on new data. For example, a decision tree can achieve perfect training performance by allowing an infinite number of splits (a hyperparameter). However, this decision tree would perform poorly when supplied with new, unseen data.
How to control for overfitting
Use a validation dataset

The validation dataset is an additional partition created that can be used to help make modeling decisions like setting hyperparameters. Imagine that the figure above represents all of your data split into three sections; the blue section is used for training, the red section is your holdout (which isn’t touched until all modeling decisions are made), and the green section is the validation set. The validation dataset can be used to evaluate a model’s performance with a given set of hyperparameters. If performance is poor on the validation set, it’s worth evaluating the model and making changes before retesting.
Cross-Validation
Cross-validation is useful for selecting hyperparameters and is done by splitting the training data into N different partitions, called folds, for training and evaluation. For example, for fivefold cross-validation, split the data into five partitions, train on four, and test on the remaining single partition. Do this five times with a different partition selected for testing each time. This process will result in five scores for one round of fivefold cross-validation. The scores can be averaged to give an overall idea of performance. Do this process for each set of hyperparameters and select the best combination for testing on the validation dataset.
Ensemble Models
Ensemble models combine many models together, typically simple models called weak learners, and aggregate the output predictions to create one final prediction. Ensemble models work well when the sub-models are diverse – their outputs have low correlation. Ensemble models can be very robust to overfitting and tend to generalize well.
Regularization
For linear models, very large coefficients can be a sign of overfitting. Regularization is a technique that penalizes the output of linear models that have large coefficients. Popular techniques include ridge and lasso regression.
Domain Knowledge
There is no substitute for domain knowledge when building machine learning models. Identifying target leakage often requires deep knowledge of the data being used, so understanding the data and what it represents is crucial to avoiding overfitting.
Conclusion
Overfitting is something to be careful of when building predictive models and is a mistake that is commonly made by both inexperienced and experienced data scientists. In this blog post, I’ve outlined a few techniques that can help you reduce the risk of overfitting. The DataRobot automated machine learning platform takes advantage of the best practices for reducing overfitting. Additionally, transparency tools like Feature Impact will aid in the identification of target leakage and provide the information needed to have full confidence in the models being implemented.

Andy works closely with customers to accelerate their use of machine learning to drive value for their business. Andy has a background in driving machine learning solutions for financial institutions and biomedical engineering.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
