


How MLOps Helps You Dodge The Wrecking Ball of Underspecification
“A wrecking-ball of a paper” — this was Brandon Rohrer’s takeaway on a new paper, Underspecification Presents Challenges for Credibility in Modern Machine Learning by D’Amour, et al. Using a set of actual use cases, the paper articulates how machine learning often fails in the real world. But then the paper stops.
My customers have asked me what they should do to address this. This post shares strategies to help them deal with underspecification — strategies that are grounded in best practices in machine learning and should be useful to everyone.

The Problem
Let’s dig into the wrecking ball. Underspecification refers to machine learning models that do not contain enough information to perform well on new unseen data. For example, these models might be missing a useful feature or haven’t properly characterized the distribution of the target (i.e., normal or Poisson distribution). Underspecified models give us the illusion of good predictive accuracy when we evaluate them on their training data. However, when given new unseen data, they fail to generalize and their accuracy drops.
As an example of underspecification, consider a computer vision model trained on ImageNet, but then tested on ImageNet-C. ImageNet-C is a variation of ImageNet with synthetic, but realistic, corruptions to the data. In the figure, you can see how the image was pixelated in ImageNet-C.

After training models on ImageNet, they often have trouble generalizing to the ImageNet-C examples. D’Amour trained many models on ImageNet. The only difference in these models was the random seed. This seemingly insignificant detail results in a strong variation when testing the models on ImageNet-C as shown in Figure 1. For D’Amour, this suggests that our current ImageNet models are underspecified. The high variance indicates there is some knowledge that can make ImageNet models generalize better to ImageNet-C. Spoiler alert, I don’t have any evidence to show the random seed of 42 is that knowledge.
While D’Amour might be able to make a theoretical point, from a practitioner’s perspective, the poor performance on ImageNet-C feels more like data drift. Data drift is the shift between the training data and new unseen data. The shift between the types of images in ImageNet and ImageNet-C is responsible for the poor performance. By retraining the models using the new ImageNet-C data, the model accuracy would improve.
Whether we use the concept of underspecification or data drift, this problem occurs in everyday machine learning systems. What can be done about this? That’s where MLOps comes into play. MLOps refers to the monitoring, managing, retraining, and governing of your models after you’ve developed them.
Let’s explore some practical solutions for dealing with underspecification.
Explainability
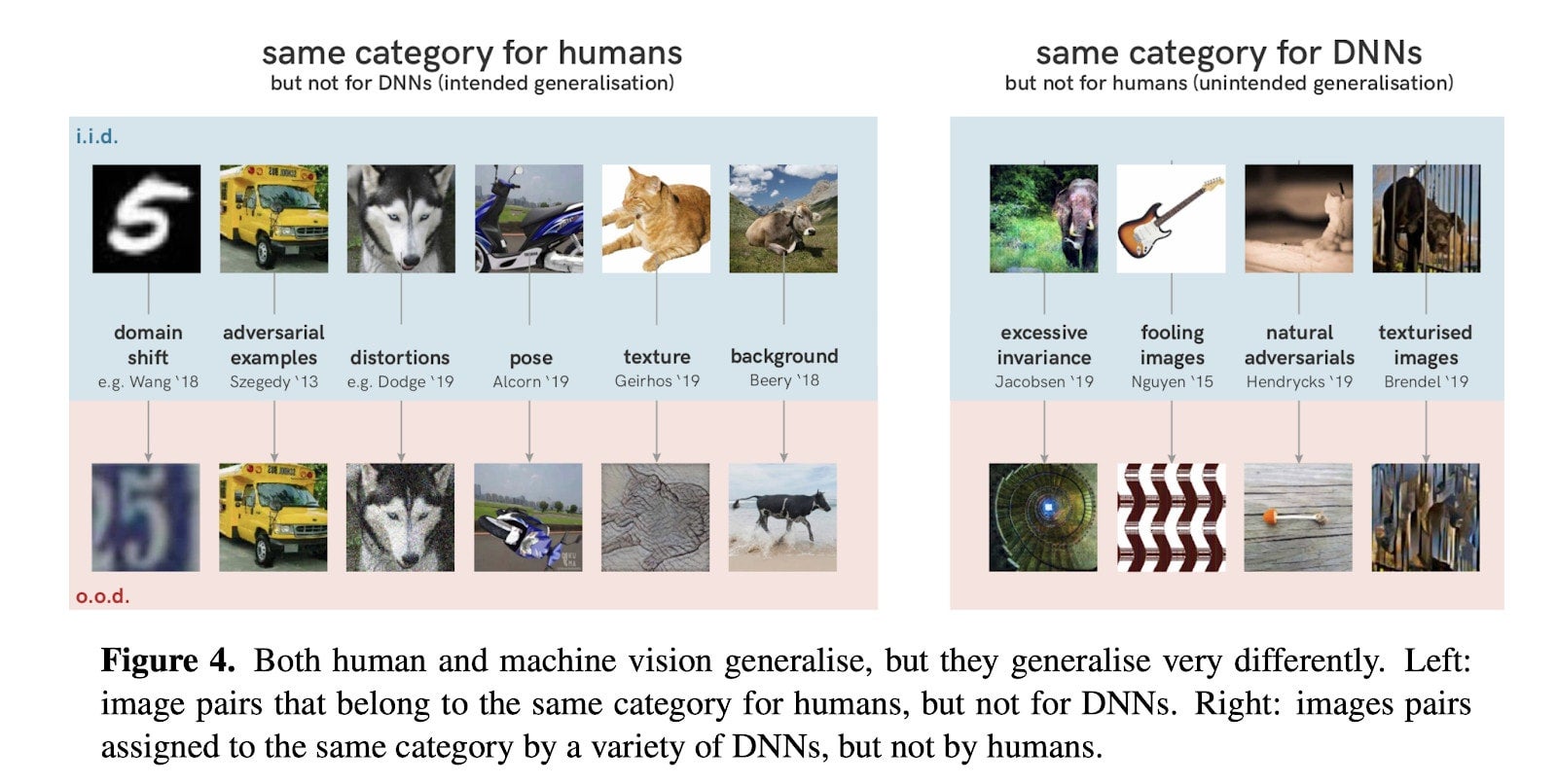
One way to identify underspecification is by leveraging explainability. Very often, models make mistakes or take shortcuts that we’re totally unaware of. The Shortcut Learning in Deep Neural Networks paper highlights some common failings of models. Models can generalize very differently than humans do. Figure 2 illustrates this.
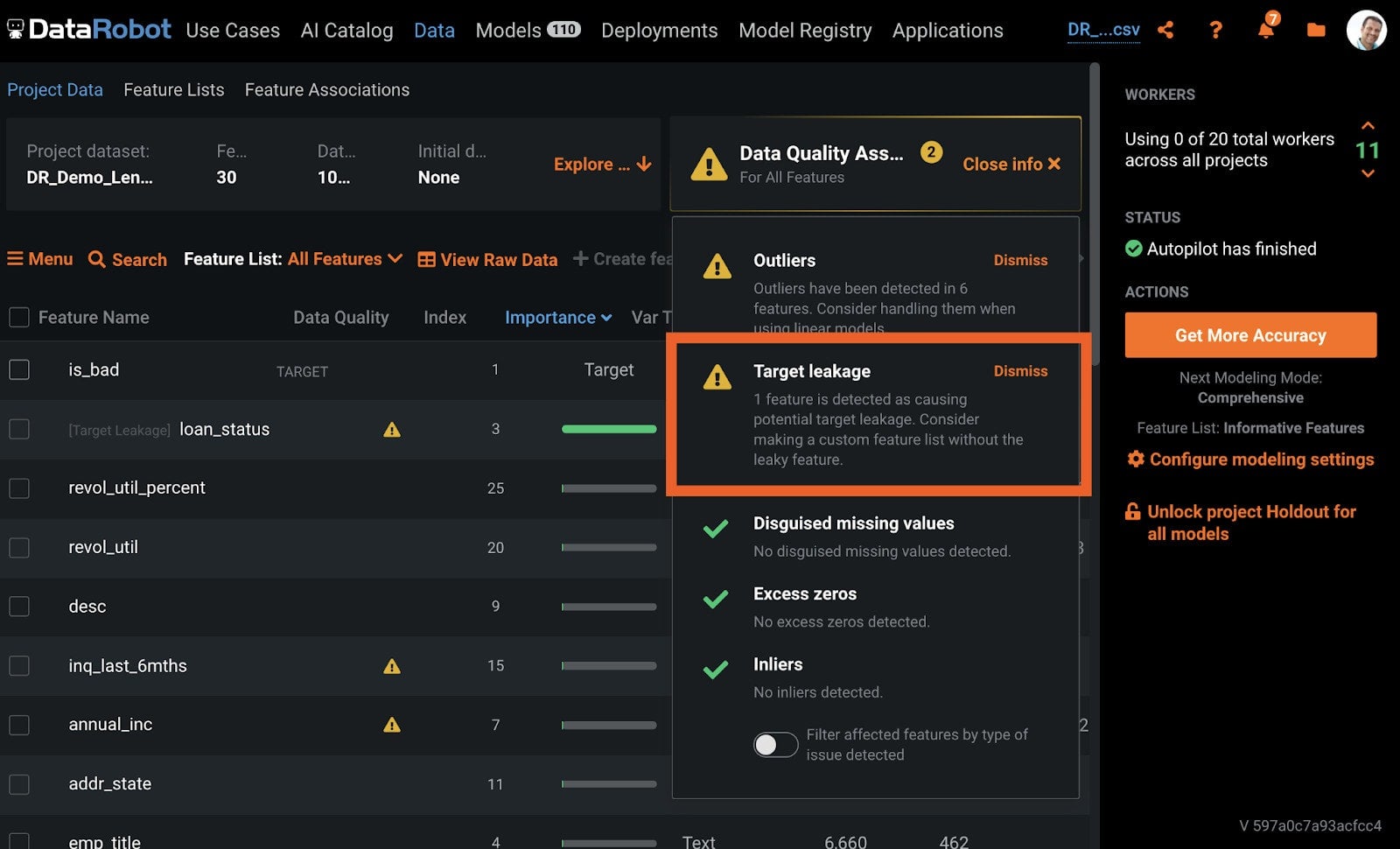
To understand how your models are working, you will want to take advantage of DataRobot’s explainability tools. DataRobot offers tools like feature impact and prediction explanations for explaining a model. There are also options for interpretable linear algorithms, generalized additive models, and even getting formulas with Eureqa. Finally, there are guardrails to help prevent common issues that may result in poor models. Figure 3 shows an example where target leakage has been automatically detected. In this case, loan_status has been recognized as causing potential target leakage.
When working with images, you can use tools like activation maps to understand how well the model is doing. In the images below (Figure 4), even after the ball is removed, the image is classified as a basketball because of the presence of a basketball player. The color from the activation map indicates the model has focused on the player when predicting basketball, rather than the ball. This type of explainability is important for understanding how a model is working and its limitations.

Monitoring and Retraining
A second solution for underspecification is to rely on continual monitoring and retraining. Monitoring is an essential part of MLOps and helps you understand how your underlying data or target is changing over time. Monitoring can identify when your data distribution has shifted far from your training data. It’s vital to monitor data drift, because there can be long lags before you can measure ground truth on your new data.
While everyone agrees models should be monitored, very few models are actually monitored.
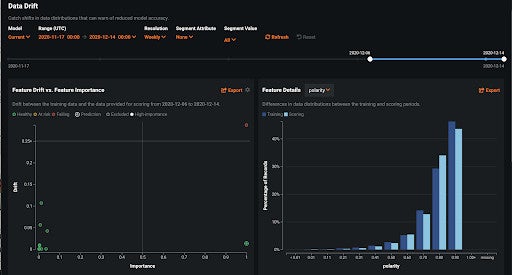
This is unfortunate, and it is why DataRobot has made model monitoring a priority. An example of how we monitor feature drift is shown in Figure 5. We started monitoring the models we built with our AutoML, but have extended monitoring to any machine learning model, even those sitting outside of the DataRobot environment. Our remote agents can help ensure that any of your machine learning models are monitored. The end goal is to make sure all our customers can incorporate a comprehensive model monitoring strategy that is model – and platform-agnostic.
The best way to ensure accurate models is by retraining them regularly. Just in Time networks (JITNet) is an example of a new line of research that demonstrates the value of continual retraining. This research shows that using recent data provides better accuracy than using a model trained on a larger set of historical data but less often. As MLOps research grows, I believe we will see more approaches towards continual monitoring and retraining.
At DataRobot, we already see our customers moving towards continual retraining and away from a “more data is better” approach. Our AutoML is a critical enabler for continual retraining. AutoML makes it faster and cheaper to build models and provides more accurate models than those that are built manually.
Moving to continual retraining provides your models with an edge over competitors who use stale models. One of our customers in a manufacturing environment uses continual retraining every 20 minutes. I prefer to keep a human in the retraining loop and use explainability tools as part of the retraining process. A large number of our customers agree and refresh their models at least every month.
Challenger Models
The third solution for dealing with underspecification is to have multiple challenger models for any deployment. This gives you the ability to compare how different models are doing and to switch to a better-performing model. The use of challengers as a response to underspecification was suggested by Yannic Kilcher. If you don’t know what the best model is, why not keep 50 models with different random seeds and then use what works best on the new data? This idea might seem excessive, but it’s happening.
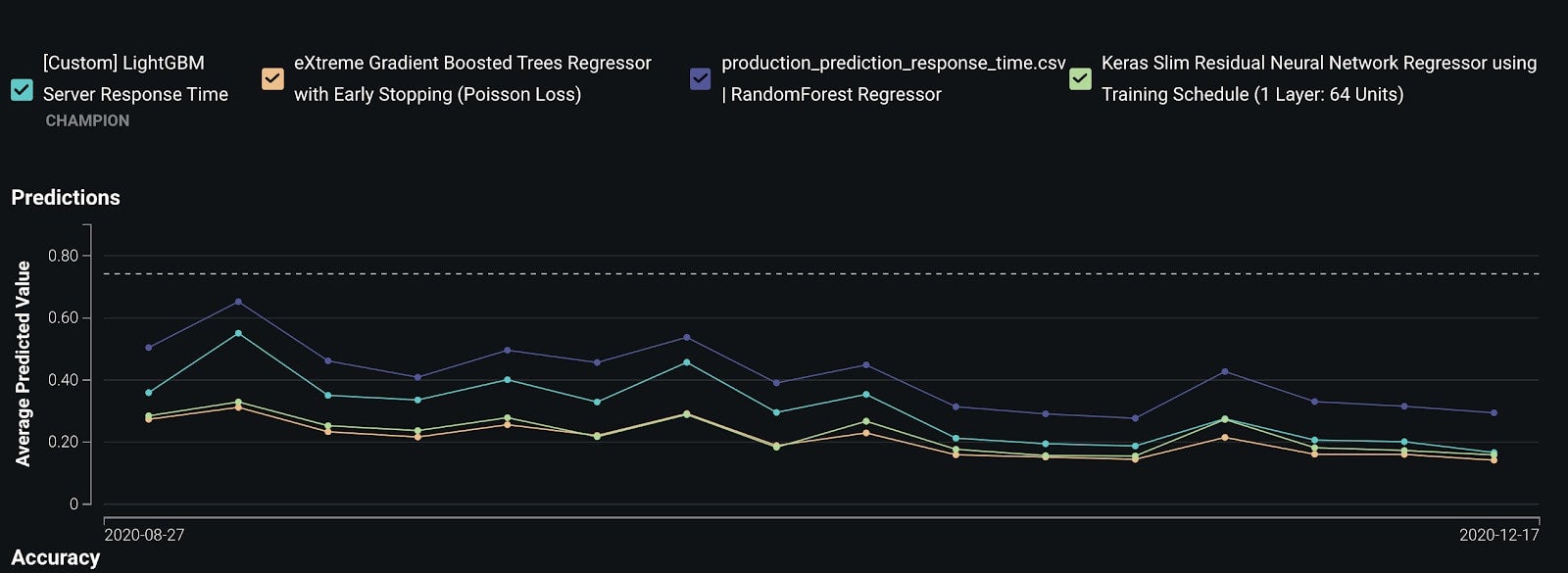
Challenger models let you compare different models in a production setting as shown in Figure 6. If a model starts performing poorly, it can be easily swapped out for one of the challenger models. By using AutoML, it’s possible to have a diverse set of modeling frameworks, architectures, and features as challenger models. This diversity is especially useful in domains where data distribution shifts are likely to happen. We believe so strongly in the value of DataRobot models that we support challenger models built outside of DataRobot with our remote agents.
Regularization and Ensembles
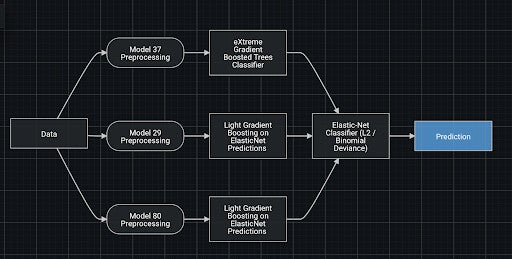
The fourth solution is to build more robust models. Dr. Thomas G. Dietterich (@tdietterich) suggests using regularization and ensembles for dealing with underspecification. Regularization is a traditional machine learning approach for preventing overfitting (and widely available within DataRobot). Ensembles (also called blenders) combine multiple models to build a more robust and accurate model. Both of these strategies are incorporated into DataRobot and you will see them in your models. Figure 7 shows an example blueprint for an ensemble model in DataRobot.
Conclusion
Though underspecification is a real problem, there are several strategies for reducing its impact. The strategies highlighted here are all data science best practices and supported in DataRobot. Techniques like explainability, regularization, and ensembles have a long provenance. The more emerging practice is to increase responsiveness by using continual retraining based on AutoML. With the ability to maintain multiple challenger models, we see organizations gaining flexibility and options when it comes to retraining.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
