

Avoiding Human Error When Building Artificial Intelligence
Can You Trust That Your AI Was Built Correctly?
It has been more than three years since the last time I competed in a data science competition, and yet there’s one memory about that competition that remains vivid in my mind. I had spent a busy week at my computer coding up a cool-looking solution, and I was ready to submit my first entry to the competition. Given my results in previous competitions, I felt confident that I would earn a high ranking. So, I clicked submit and waited for my competition leaderboard ranking – and discovered that I had placed second to last!
After the initial shock and disappointment, I reviewed my work. Way back on my first day of coding for the competition, I had made a silly coding mistake and used the wrong column name. The model was worthless. An entire week of work had been wasted. It was embarrassing, but thank goodness my model was built just for fun and not a mission-critical business application that could cost millions of dollars in losses or a healthcare application that could affect life-or-death decisions.
Most modern artificial intelligence (AI) applications are powered by machine learning algorithms and until recently, most machine learning algorithms were built manually. Like all manual tasks, coding and model design are prone to human error, more so when building a completely new and complex solution. What is needed are development tools with guardrails to warn and prevent data scientists from making dangerous mistakes.
As enterprises evolve to democratize data science, the risk of human error increases. Modern software tools have empowered citizen data scientists to build predictive models more easily. However, despite the unprecedented ease and speed of getting started with machine learning, the danger is that there are still many best practices that users need to apply to get reliable results. But most machine learning solutions require the user to have the knowledge and experience to manually apply best practices. They do not contain best practices or safeguards to protect novice talent from themselves.
Data Science Guardrails
What do data science guardrails look like and how can they help? I’m going to use personal data published by Lending Club as a case study. Lending Club is the world’s largest peer-to-peer lending platform. Lending Club provides historical data to investors, allowing those investors to develop credit scoring models in order to better select and underwrite their loan investments. If those credit risk models are faulty, investors can lose money on bad loans.
Some input features don’t belong in a credit risk model, because you won’t know their values at the time you are assessing the loan application or because they are just proxies for the value you are trying to predict. Data scientists call this target leakage.
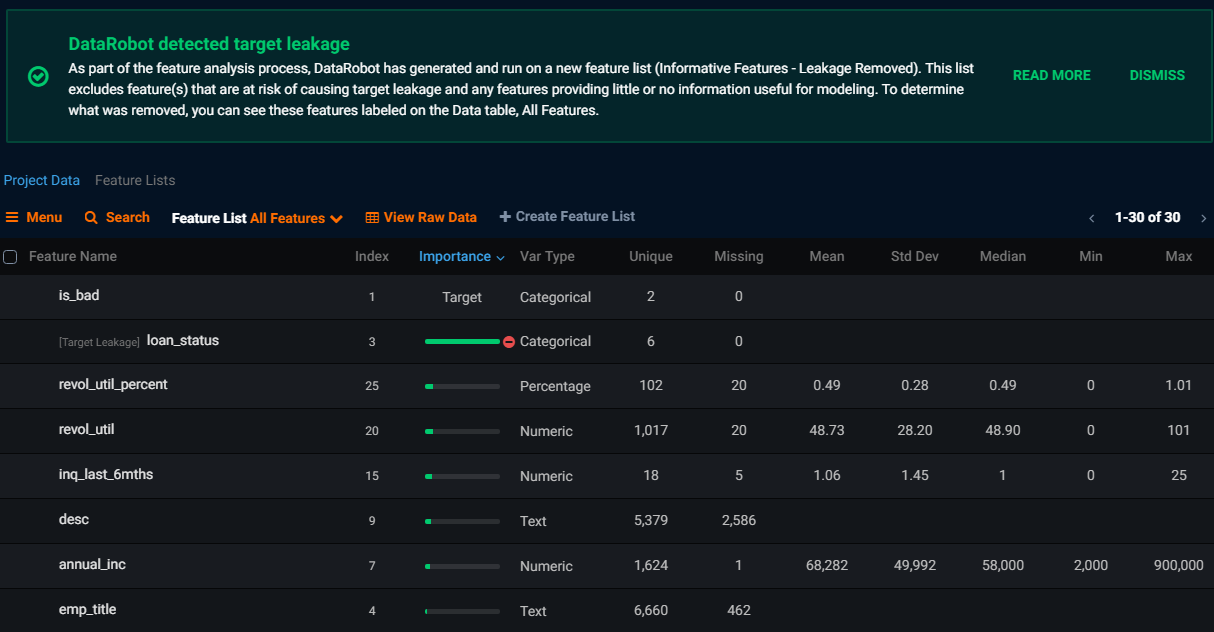
Look for a machine learning tool with guardrails that automatically detect target leakage. In the screenshot above, the final loan status has been flagged for causing target leakage. Final loan status is not known until the loan period is finalized and is just a proxy for whether the loan went bad. A model that has learned to predict bad loans using final loan status has no value.
Some input features don’t belong in a model because they don’t contain useful information or are duplicates or other columns.
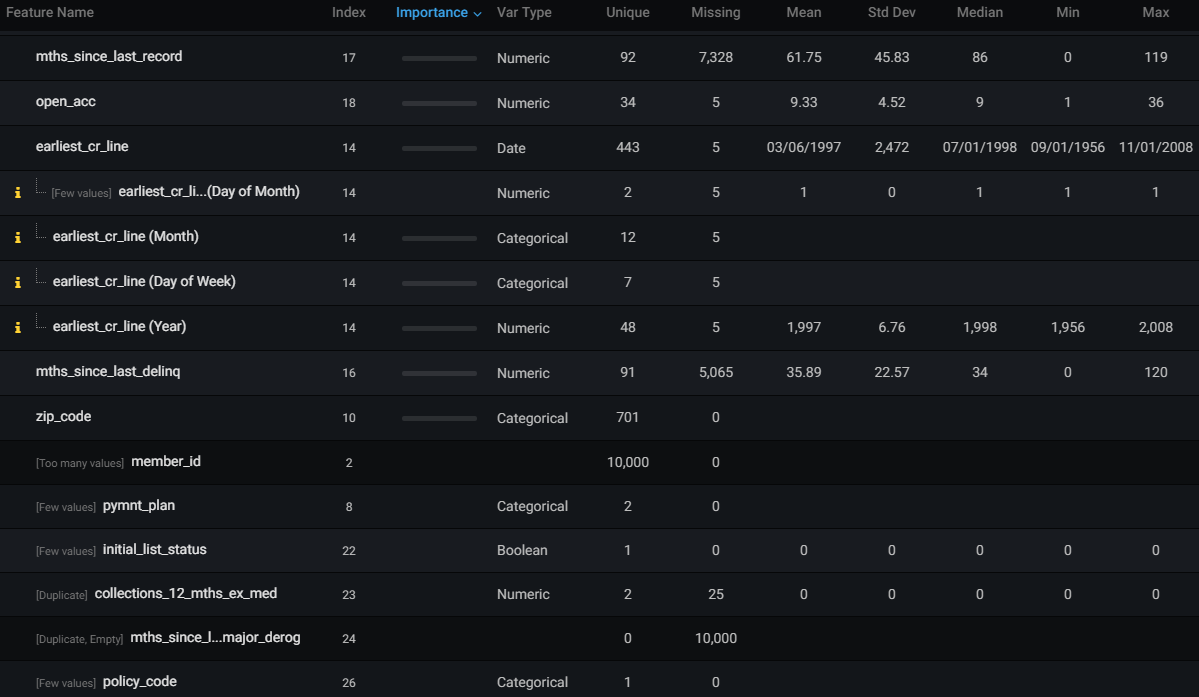
Look for a machine learning tool with guardrails that automatically detect uninformative columns and duplicate columns. In the screenshot above, DataRobot has excluded member ID from the model because it is a database row identifier. Payment plan values have been excluded because only an insignificant number of rows in that column vary from the usual value. Initial list status has been excluded because all of the rows contain the same value. The values for debt collection in the past 12 months are a duplicate of another column, so they have also been excluded. Uninformative and duplicate columns can cause errors in some machine learning algorithms, or worse, they could cause an algorithm to “learn” a pattern in the data that is mere luck.
Many real-life databases contain missing values. Yet many popular algorithms and statistical models do not accept data rows containing missing values. Some libraries drop these data rows with little warning. Without those data rows, a model is likely to make biased predictions. For example, a majority of the rows in the Lending Club data have never had a negative credit action and therefore contain a missing value. A model trained on Lending Club data that excluded data rows with missing values for negative credit action will be overly pessimistic and will not have learned that a missing value for negative credit action is indicative of a good risk. Look for a machine learning tool that automatically identifies data containing missing values and understands how to best impute missing values for each type of algorithm.
Historically, the accuracy of statistical models was measured against the data upon which they were trained. But the true value of predictive models is how well they apply to new data. So the best practice is to measure the accuracy of models against out-of-sample data.
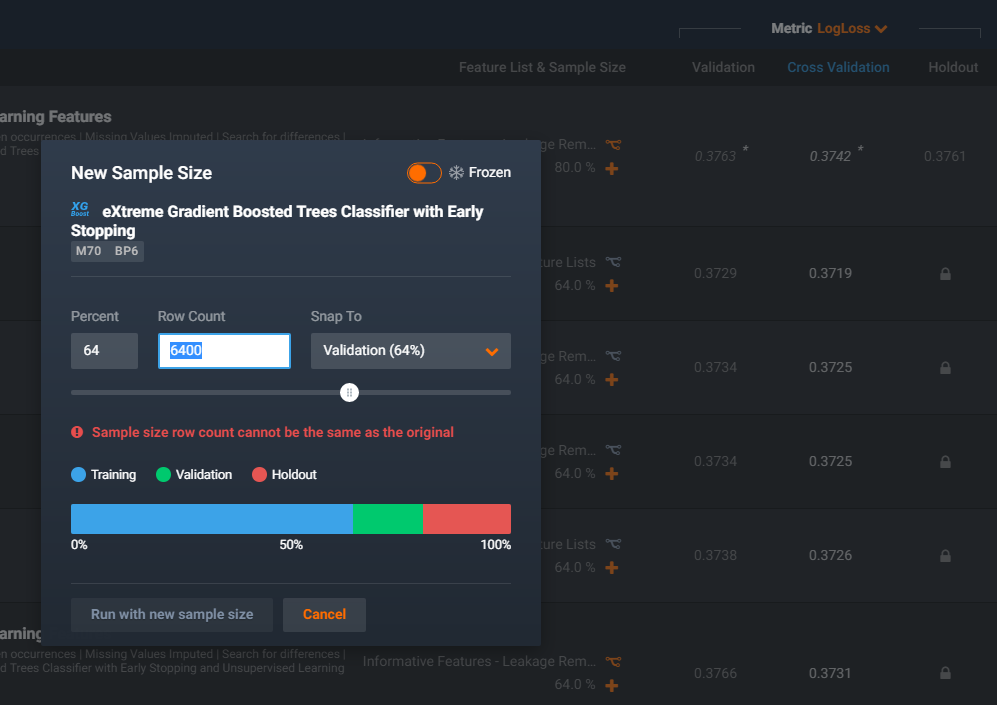
Look for a machine learning tool that automatically partitions the historical data to separate training and validation data. Model accuracy is compared against new data that the model was not trained on. Guardrails should ensure that models are only compared on their validation accuracy, never on training data. In the screenshot above, you can see how DataRobot has applied guardrails to partition the data into training, validation, and holdout, and ranked the models by their cross-validation accuracy. Without these guardrails, your model choice may be biased towards a model that matches history well but has not generalized enough to generate accurate predictions on data.
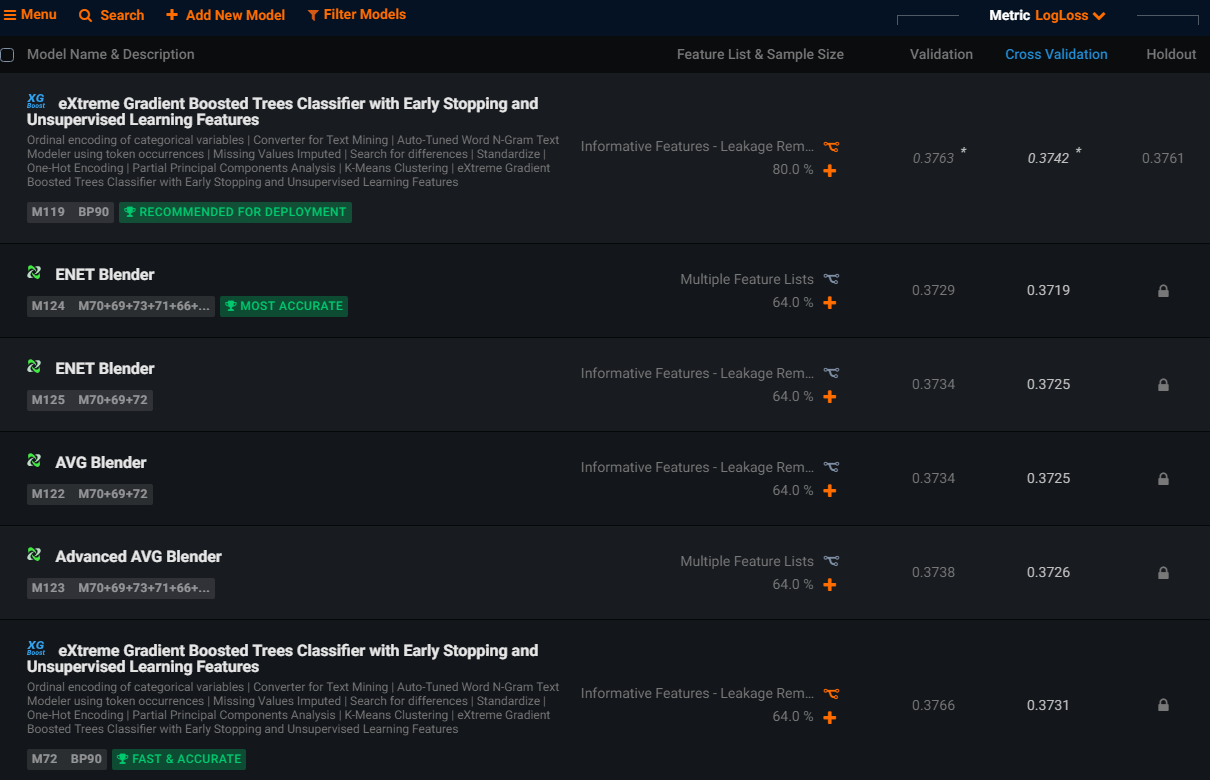
Humans can be biased in choosing algorithms. Some are conservative and always use the same familiar algorithms, while others are influenced by the hype of the latest machine learning library. Look for a machine learning tool with guardrails in order to select only those algorithms that are best suited to the training data and which objectively ranks a diverse range of algorithms in order to find the best performing model.
It’s easy to forget that there’s more to model choice than accuracy. Some artificial intelligence applications are time-critical, so look for a data science tool that gauges the prediction speed of each model and applies guardrails to recommend the model with the optimal balance of speed and accuracy. In the screenshot above, you can see how DataRobot labels models with badges that recommend a model for deployment, and identifies the model with the highest accuracy and one with a strong balance between speed and accuracy.
Conclusion
Manually building modern AI applications is a high-risk process. As they say, no one is perfect, and human error can hamper your success with AI.
EY warns that your AI “can malfunction, be deliberately corrupted, and acquire (and codify) human biases in ways that may or may not be immediately obvious. These failures have profound ramifications for security, decision-making and credibility, and may lead to costly litigation, reputational damage, customer revolt, reduced profitability and regulatory scrutiny.”
Guardrails provide warnings and enforce best practices that prevent costly errors when building your AI applications. DataRobot, the leader in automated machine learning, is the only machine learning tool with guardrails for target leakage, uninformative columns, missing values, data partitioning, out-of-sample accuracy, algorithm selection, and many other best practice safeguards. Click here for more information about DataRobot’s guardrails, or to see a live demonstration of DataRobot’s guardrails in action.


Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
