


4 Key Data Prep Capabilities to Create a Single View of Customer/ Vendor
Whether you are preparing data for analytics or reporting, performing a data migration or consolidation, or creating a unified view of customer, product, or vendor, the organization name attribute is a critical data component. It must be clean and standardized to allow an accurate view of your business operations and to support optimal business decisions, especially after an M&A event.
Most of us have heard about the recent merger or acquisition of well-known brands: CVS and Aetna, T-Mobile and Sprint, BB&T and SunTrust Bank – these are massive companies using a variety of systems and applications to support their customer 360 efforts, churn analysis and prediction, and fraud detection, to name a few use cases where data quality is a critical concern.
In my experience profiling, cleaning, and mapping data, I’ve noticed 4 key capabilities which drive the value in solving the aforementioned use cases:
Visual Data Profiling & Full Discovery
In order to determine the nature and extent of any data anomalies and validate whether the org name attribute is accurate, you must understand the full distribution of values. (Important Note: A sample will leave you with a skewed understanding and may mislead your analysis due to false presumptions.) This visual data quality profile is the key to validating that you have properly and comprehensively finished your standardization work.
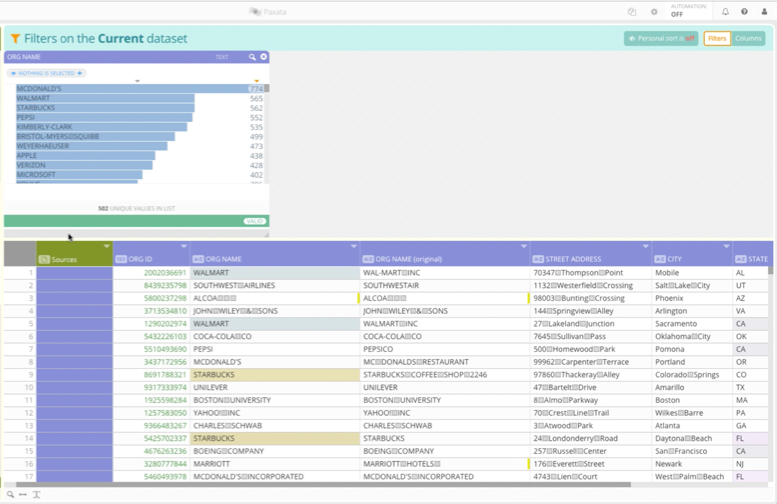
Dynamic Column Transformations
Although it may be difficult to anticipate all the different transformations that may be needed to clean up and reconcile entity / master data, it is highly beneficial to use an agile solution that provides a variety of dynamic transformation options. Then, apply bulk (multi-column) transformations to trim out the whitespace, standardize on case, apply a split (especially when recurring dash marks or parentheses indicate the inclusion of regional or other identifying information that should be parsed into a new column).
Perhaps the most effective approach includes the use of intelligent algorithms on the full dataset in order to detect all the potential duplicates and then to apply the recommended fixes (at scale) for each group, or cluster, of similar org names. Applying this key step almost always reveals a major boost in data accuracy – the number of unique org names decreases and you see the standardization impact immediately.
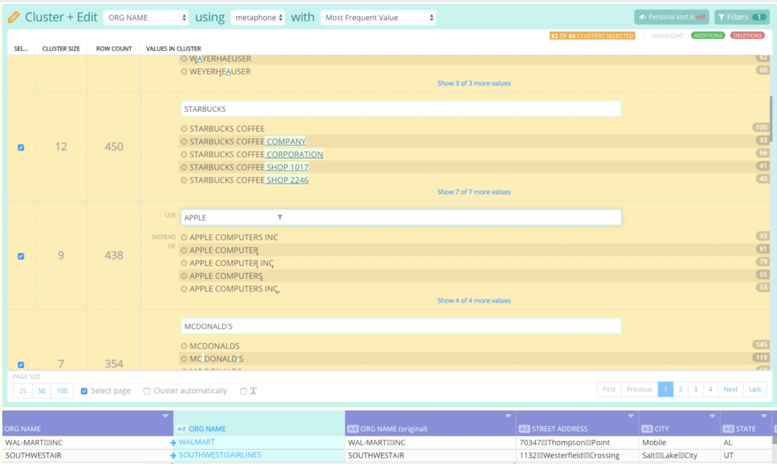
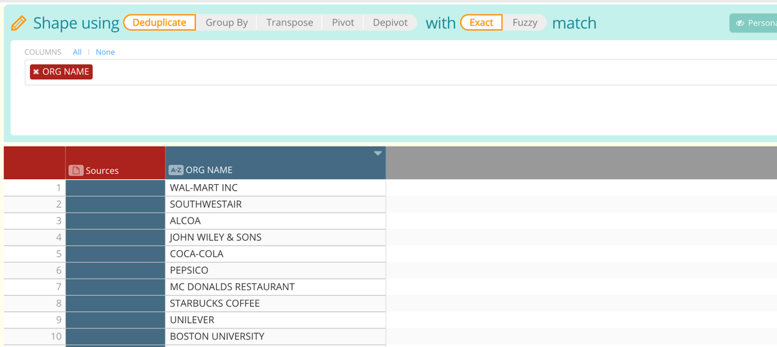
Point-and-Click Deduplication
Deduplicate the entire dataset such that you’re left with only the before and after versions of your Org Name attribute. This allows us to generate a mapping file based on your standardization work which may be useful for lookup purposes!
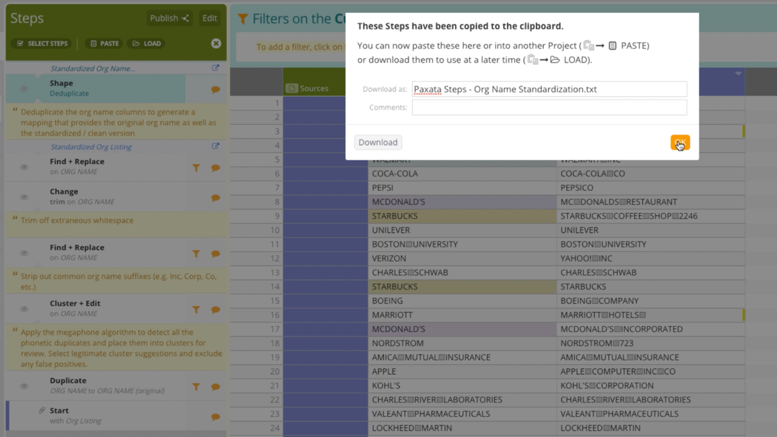
Intuitive Steps Management & Reuse
Collaboration and reuse are popular topics in the self-service data prep space. You should be able to easily share your work, whether it’s the entire data workflow project or just certain steps, so you never have to redo work or reinvent the wheel.
Recall that many of these steps will come in handy for other datasets which contain a company, supplier, or vendor name attribute.
Data Prep offers all of these key capabilities to business analysts, data scientists, and data quality specialists and is designed to tackle the various data quality issues often found (or buried) in customer and vendor/supplier data. To see each of these capabilities in action for this scenario, check out my use case vignette video: Org Name Standardization
Consider the value you can gain today on similar use cases where Data Prep provides a great advantage for profiling, combining, and transforming your raw data. The results can be significant and realized in a fraction of the time compared to the legacy, status-quo process!
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
