

Using Feature Importance Rank Ensembling (FIRE) for Advanced Feature Selection
At the heart of machine learning is the identification of features or variables that are useful for a prediction. Without the right features, your model lacks the information required to make good predictions. Including redundant or extraneous features can lead to overly complex models that have less predictive power. Striking the right balance is known as feature selection. In this post, we share a method for feature selection that’s based on ensembling the feature importance scores from several different models, which leads to a more robust and powerful result.
During feature selection, data scientists try to keep the three Rs in mind:
- Relevant. To reduce generalization risk, the features should be relevant to the business problem at hand.
- Redundant. Avoid the use of redundant features. They weaken the interpretability of the model and its predictions.
- Reduce. Fewer features mean less complexity, which translates to less time for your model training or inference. By using fewer features, you can decrease the risk of overfitting and even boost the performance of the model.
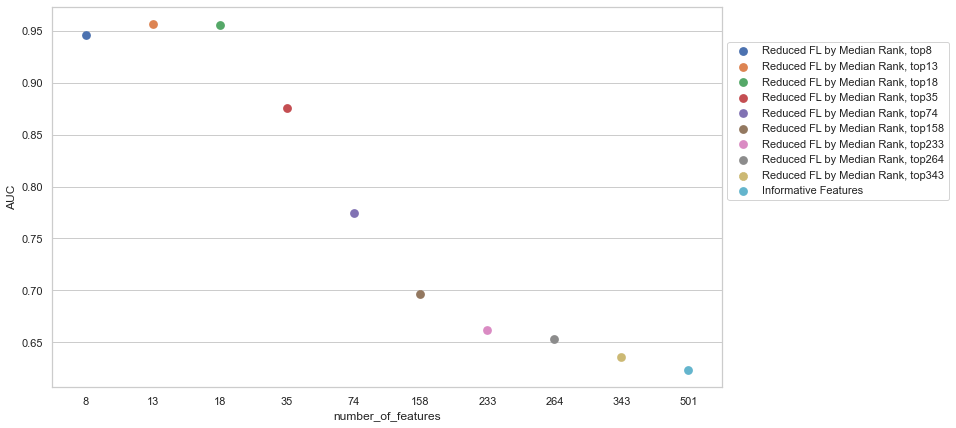
Figure 1 shows an example of how feature selection is used to improve a model’s performance. As the number of features are reduced from 501 to 13, the model’s performance improves, as indicated by a higher area under the curve (AUC). This visualization is known as a feature selection curve.
In this blog post, we discuss how feature importance rank ensembling (FIRE) can be used to reduce features while maintaining predictive performance.
Feature Selection Approaches
There are three approaches to feature selection.
Filter methods select features on the basis of statistical tests. DataRobot users often do this by filtering a dataset from 10,000 features to 1,000 using the Feature Importance score. This score is based on the alternating conditional expectations (ACE) algorithm and conceptually shows the correlation between the target and the feature. The features are ranked and the top features are retained. One limitation of the DataRobot Feature Importance score is that it only accounts for the relationship between that feature in isolation and the target.
Embedded methods are algorithms that incorporate their own feature selection process. In DataRobot you see embedded methods in approaches that include Elastic net and our genetic algorithm, Eureqa.
Wrapper methods are model-agnostic and typically include modeling on a subset of features to help identify the best ones. Wrapper methods are widely used and include classics like forward selection, backward elimination, recursive feature elimination, and more sophisticated stochastic techniques, such as random hill climbing and simulated annealing.
The wrapper methods tend to provide a more optimal feature list than filter or embedded methods, but they are more time-consuming, especially on datasets with hundreds of features.
The recursive feature elimination wrapper method is widely used in machine learning. This approach starts with many features and reduces the feature list. A common criteria for removing the features is based on feature importance calculated by using permutation importance. This process removes the features with the worst scores and a new model is built. The recursive feature selection approach was used to build the feature selection curve in Figure 1.
Feature Importance Rank Ensembling
Building on the recursive feature elimination approach, we propose combining the feature importance of multiple diverse models. For DataRobot users, this approach is based on aggregating ranks of features using Feature Impact from several blueprints from the leaderboard. DataRobot has used this successfully with our customers for many years. This post provides an overview of this approach.
You can extend model ensembling, which provides improved accuracy and robustness, to feature selection. This method is called feature importance rank ensembling (FIRE). There are many ways to aggregate the results, but the following steps in the feature selection process work best;
- Calculate the feature importance for the top N best models in the leaderboard against the selected metric. You can calculate feature importance by measures such as permutation or shap impact.
- For each model with computed feature importance, get the ranking of the features.
- Compute the median rank of each feature by aggregating the ranks of the features across all models.
- Sort the aggregated list by the computed median rank.
- Define the threshold number of features to select.
- Create a feature list based on the newly selected features.
To understand the effect of aggregating the features, Figure 2 shows the variation in feature importance across four different models trained on the readmission dataset. The aggregated feature impact is derived from four models:
- LightGBM
- XGBoost
- Elastic net linear model
- Keras deep learning model
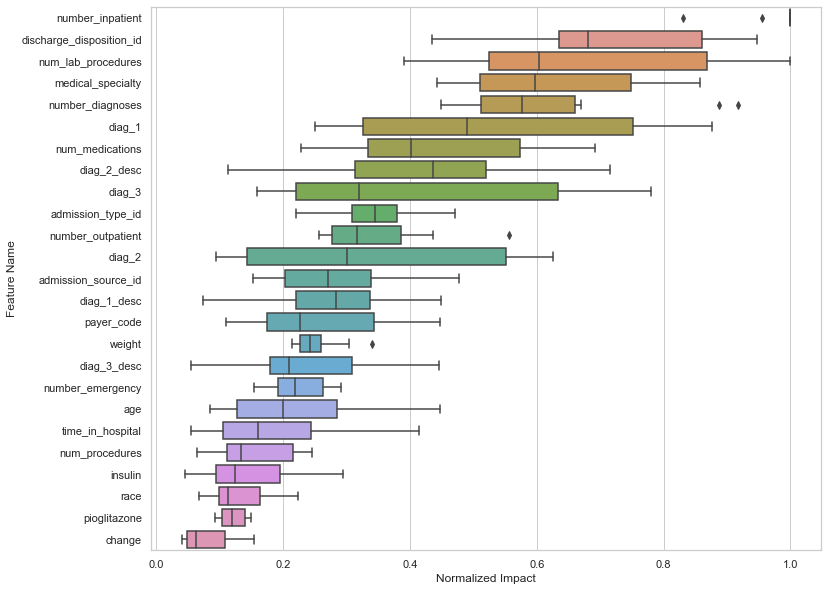
As indicated by their high Normalized Impact score, the features at the top have consistently performed well across many models. The features at the bottom consistently have little signal. They perform poorly across many models. Some features with wide ranges, like num_lab_procedures and diag_x_desc, performed well in some models, but not in others.
Due to multicollinearity and the inherent nature of models, you see variation across models. That is, linear models are good at finding linear relationships. Tree-based models are good at finding nonlinear relationships. By ensembling the feature impact scores, you find which features are most important in the dataset views of each model. By iterating with FIRE, you can continue to reduce the feature list and build a feature selection curve like the one in Figure 1. FIRE works best when you use models that have good performance. That way, the feature importance is useful.
Results
To demonstrate the value of this method, we have included a reproducible example in the DataRobot Community repository on GitHub. The example shows results on several wider datasets, including Madelon and KDD 1998.
Here are the characteristics and performance results of these datasets:
- AE is an internal dataset with 374 features and 25,000 rows.
Prediction: Regression
DataRobot recommended metric: Gamma deviance
- AF is an internal dataset with 203 features and 400,000 rows.
Prediction: Regression
DataRobot recommended metric: RMSE
- G is an internal dataset with 478 features and 2,500 rows.
Prediction: Binary classification
DataRobot recommended metric: LogLoss
- IH is an internal dataset with 283 features and 200,000 rows.
Prediction: Binary classification
DataRobot recommended metric: LogLoss
- KDD 1998 is a publicly available dataset with 477 features and 76,000 rows.
Prediction: Regression
DataRobot recommended metric: Tweedie deviance
- Madelon is a publicly available dataset with 501 features and 2,000 rows.
Prediction: Binary classification
DataRobot recommended metric: LogLoss
We used the DataRobot Autopilot feature to return these results and show the scores of the best-performing model. We selected the metrics based on the type of problem and distribution of the target. Then we used Autopilot to build competing models. Lastly, we used FIRE to develop new feature lists. The results show the performance of the feature list on the best-performing model along with the standard deviation using 10-fold cross-validation.
Informative Features is the full feature list. DR Reduced Features is a one-time reduced feature list using permutation importance that is run in DataRobot automatically. FIRE uses the feature importance with the median rank aggregation approach using an adaptive threshold (the N features that possess 95% of total feature impact).
| Dataset name | Metric* | Informative Features score (number of features) | DR Reduced Features score (number of features) | FIRE score (number of features) |
| AE | Gamma deviance | 0.043 ± 0.004(374) | 0.041 ± 0.005(30) | 0.039 ± 0.005(35) |
| AF | RMSE | 110.7 ± 2.41 (203) | 116.1 ± 2.43 (78) | 111.8 ± 2.67 (94) |
| G | LogLoss | 0.575 ± 0.019(478) | 0.574 ± 0.024(100) | 0.567 ± 0.023 (79) |
| IH | LogLoss | 0.167 ± 0.026 (283) | 0.167 ± 0.023 (63) | 0.166 ± 0.025(79) |
| KDD 1998 | Tweedie deviance | 5.362 ± 0.12 (477) | 5.364 ± 0.122 (72) | 5.328 ± 0.13 (17) |
| Madelon | LogLoss | 0.42 ± 0.015 (501) | 0.44 ± 0.018 (101) | 0.26 ± 0.04(19) |
Table 1. Feature selection results on six wide datasets. The bold formatting is used to indicate the best-performing result in terms of the mean cross-validation score.
* Lower is better.
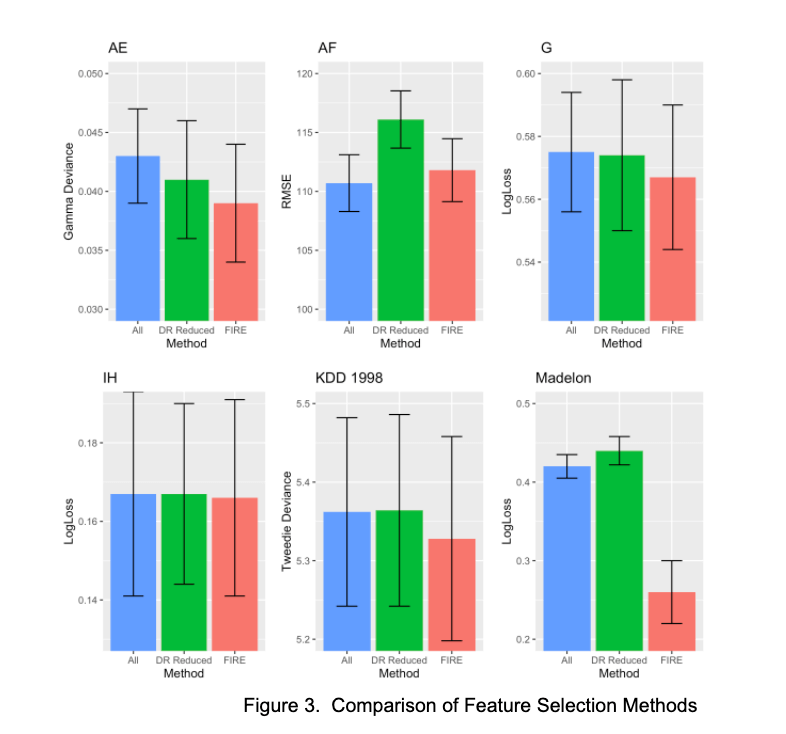
Across all of these datasets, FIRE consistently had similar or better performance than the use of all features. It even outperformed the DR Reduced Features method by reducing the feature set without any loss in accuracy. For the Madelon dataset, you can see how reducing the number of features provides better performance by looking at the feature selection curve in Figure 1. As FIRE parsed down features from 501 to 18, the model’s performance improved.
If you use FIRE, you must build more models during model training so you have feature impact across diverse models for ensembling. The information from these other models is very useful for feature selection.
Conclusion
Improved accuracy and parsimony are possible when you use the FIRE method for feature selection. Just as our post on explanation clustering shared new approaches for the data science community, DataRobot is excited to provide data scientists with another approach to feature selection. There are many variations left to validate: feature importance (shap, permutation), choice of models, perturbing the data or model, and the method for aggregating (median rank, unnormalized importance).
Authors: Vitalii Peretiatko and Rajiv Shah
Thanks to Taylor Larkin and Lukas Innig for their technical review.
Background
- Advanced Feature Selection with R blog post on the DataRobot Community website
- Instructions and logic for advanced feature selection in Python in the DataRobot GitHub repository
- Reproducible example on the Madelon dataset in the DataRobot Community GitHub repository

Vitalii works as Data Scientist at AI Execution team, a professional services division of DataRobot, focusing on developing and executing end-to-end enterprise-grade AI solutions for DataRobot customers across a variety of industries. He enjoys participating in data science competitions and hackathons to be on the cutting edge of data science technologies. He holds an M.Sc. in Software Engineering from Tartu University, Estonia
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
