

The Solution to Insurance Price Wars Isn’t Price!
- Insurers continually look to enhance price segmentation to achieve profitable growth
- Regulatory constraints have prevented insurers from implementing the most segmented models
- Recent technological advances turn this constraint into an opportunity to boost profits
 Over the past two decades, there has been a virtual arms race for more sophisticated pricing models among insurers as they seek ever more granular risk segmentation. We’ve all seen the byproduct of this one-upmanship in the flood of television ads promising to save us money on our car insurance. By telling us what cavemen can do, suggesting how best to spend the next 15 minutes of our lives, or even offering to give us competitor rates as well as their own (brilliant strategy, by the way), insurers have been battling to grow profitably for years through the use of more segmented pricing plans. These days, however, sophisticated pricing is no longer seen as much as a competitive advantage as it is a necessity to simply survive. Insurers are once again looking for a new competitive advantage to boost their profitability, and a new set of tools known as automated machine learning is poised to deliver this advantage.
Over the past two decades, there has been a virtual arms race for more sophisticated pricing models among insurers as they seek ever more granular risk segmentation. We’ve all seen the byproduct of this one-upmanship in the flood of television ads promising to save us money on our car insurance. By telling us what cavemen can do, suggesting how best to spend the next 15 minutes of our lives, or even offering to give us competitor rates as well as their own (brilliant strategy, by the way), insurers have been battling to grow profitably for years through the use of more segmented pricing plans. These days, however, sophisticated pricing is no longer seen as much as a competitive advantage as it is a necessity to simply survive. Insurers are once again looking for a new competitive advantage to boost their profitability, and a new set of tools known as automated machine learning is poised to deliver this advantage.
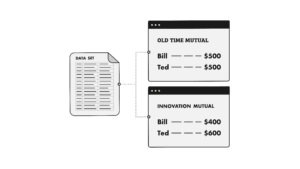 Let’s briefly revisit an age-old problem. Consider two policyholders, Bill and Ted. They’ve never met, but they have a lot in common. Both are 43-year-old married males who drive motorcycles. They each get motorcycle insurance quotes from two insurers, Old Time Mutual and Innovation Mutual. Bill and Ted are indistinguishable to Old Time’s pricing model and thus they both receive quotes of $500. Meanwhile, Innovation Mutual uses additional information that Old Time does not, resulting in a rating plan that more accurately reflects the costs Bill and Ted are expected to generate. Innovation quotes Bill $400 and Ted $600. If Innovation Mutual didn’t exist, Bill and Ted would have each bought policies from Old Time for $500. Ted and his underpriced policy would have been subsidized by Bill. But now, since Bill goes with Innovation, Old Time is in trouble as they only get the underpriced risk. This simple example illustrates why insurers are always looking to improve the segmentation of their rating plans.
Let’s briefly revisit an age-old problem. Consider two policyholders, Bill and Ted. They’ve never met, but they have a lot in common. Both are 43-year-old married males who drive motorcycles. They each get motorcycle insurance quotes from two insurers, Old Time Mutual and Innovation Mutual. Bill and Ted are indistinguishable to Old Time’s pricing model and thus they both receive quotes of $500. Meanwhile, Innovation Mutual uses additional information that Old Time does not, resulting in a rating plan that more accurately reflects the costs Bill and Ted are expected to generate. Innovation quotes Bill $400 and Ted $600. If Innovation Mutual didn’t exist, Bill and Ted would have each bought policies from Old Time for $500. Ted and his underpriced policy would have been subsidized by Bill. But now, since Bill goes with Innovation, Old Time is in trouble as they only get the underpriced risk. This simple example illustrates why insurers are always looking to improve the segmentation of their rating plans.
That aforementioned arms race of the past 20 years began (in the US) in the 1990’s when a single insurer introduced a rating plan into the US market that was more complex than anything anyone else was using. They weren’t using risk characteristics that other insurers didn’t have, just a new algorithm. As a result, this company took in monster profits for years and changed the industry. The takeaway here: two insurers using the exact same rating information can achieve vastly different pricing segmentation simply by using different modeling algorithms.
The insurance pricing landscape today is dominated by a class of models known as “GLMs” and “GAMs”, even though there are numerous other viable approaches. We have seen an explosion of algorithms over the past few years: XGBoost, Support Vector Machines, Random Forests, Neural Networks, to name a few. One of these could, and likely would yield a more segmented pricing plan than a GLM would produce. But the expectation in the industry is that no regulator is likely to approve a rating plan that relies on such a model, at least for the foreseeable future. Models need to be interpretable to the business, regulators, and consumers, and many of the algorithms I just listed have a reputation for being black boxes. These models are interpretable, but that’s another article for another day (stay tuned). So how do we even know if one of these alternative algorithms will produce a more segmented pricing model? And how can we use such a model if regulators won’t approve it for pricing? Let’s address each of these questions.
First, how can we know if some machine learning algorithm will outperform the regulator-approved GLM? Although sometimes the GLM will be the best model, the only way to answer this question is to simply try a wide variety of approaches. In the past, this would have been a non-starter, but with the development of automated machine learning, insurers can now do this with the push of a button. More on this in a moment. Let’s first put a GLM head to head against other algorithms using real insurance data (for this example, I used the ‘Motorcycle Insurance’ dataset from the R package ‘InsuranceData’). Let’s assume Old Time Mutual uses a GLM for their pricing model. Innovation Mutual uses Automated Machine Learning to build dozens of machine learning models (including GLMs) in a fraction of the time it used to take them to manually build a single GLM. What they discovered was that a modeling algorithm known as a “Gradient Boosting Machine” or “GBM” outperformed all the other approaches – using the exact same rating characteristics. While the diagnostics for the GLM and the GBM individually look reasonable and somewhat similar, the comparative diagnostics reveal significant differences between the models and significant opportunity for Innovation Mutual.
At one extreme, we find risks for whom the GLM produces prices well above cost while the GBM remains accurate; at the other extreme, we find risks for whom the GLM produces prices well below cost, again while the GBM remains accurate. In other words, the more segmented model has allowed us to identify the Bills and the Teds. It allowed us to identify the customers being pricing above cost and those being pricing below cost by the GLM! Innovation Mutual will work to get the GBM-based pricing plan approved by regulators, but until that happens they’ve decided to implement the regulator-friendly GLM. Consequently, since this rating plan is comparable to Old Time’s, Bill and Ted each get quotes of $500 from both companies. This is the current state of the insurance industry; everyone is using very similar modeling approaches. Which brings us to the second question above. How can we use these machine learning models if the regulators won’t approve them for pricing?
While both insurers quote the same price for the two risks, Innovation now knows something that Old Time does not. They know that Bill is priced over cost, and Ted is priced under. The takeaway here: The regulators have effectively imposed a constraint by not allowing the more accurate model and in doing so have presented Innovation Mutual with a tremendous opportunity.
To be abundantly clear, Innovation Mutual must comply with market regulations and of course, they must act within the bounds of good business ethics. But they have information that Old Time does not, so it’s up to the good smart people at Innovation Mutual to find an acceptable way to leverage this information so that they write a disproportionate number of Bills while writing fewer Teds. Let’s consider for a moment what would happen if they can pull this off. Let’s assume that 25% of Innovation’s motorcycle book consists of Bills and 25% consists of Teds who are over/underpriced by 15%, respectively. If Innovation could get rid of all the Teds and replace them with Bills, they would improve their loss ratio by more than 4 percentage points! In reality, they likely won’t be able to swap every Ted for a Bill, but if they can even swap 25% of them, then Innovation improves their loss ratio by 1 percentage point. Clearly getting more Bills and fewer Teds is good for business, but how are they going to accomplish that?
 While they might be able to use this information directly in pricing in company/tier placement, the solution is not pricing at all, but rather marketing and non-monetary incentives. Perhaps Innovation can require Ted to pay in full, while Bill can pay in installments. Maybe they only target the Bills of the world in their marketing campaigns. Maybe the web design that displays Bill’s quote is just cooler looking or somehow more appealing than Ted’s. Or maybe they send Bill birthday cards while sending Ted a survey of competitor pricing and benefits (if you invite me to leave I might just do it!). Again, it is imperative that Innovation Mutual understand and comply with all applicable laws and regulations when developing its strategy, but the point here is that the company that uses automated machine learning to identify the Bills and Teds, and then gets creative and figures out how to get a disproportionate number of Bills is poised to take it to the bank.
While they might be able to use this information directly in pricing in company/tier placement, the solution is not pricing at all, but rather marketing and non-monetary incentives. Perhaps Innovation can require Ted to pay in full, while Bill can pay in installments. Maybe they only target the Bills of the world in their marketing campaigns. Maybe the web design that displays Bill’s quote is just cooler looking or somehow more appealing than Ted’s. Or maybe they send Bill birthday cards while sending Ted a survey of competitor pricing and benefits (if you invite me to leave I might just do it!). Again, it is imperative that Innovation Mutual understand and comply with all applicable laws and regulations when developing its strategy, but the point here is that the company that uses automated machine learning to identify the Bills and Teds, and then gets creative and figures out how to get a disproportionate number of Bills is poised to take it to the bank.
This opportunity is very real and it exists today. The example above puts the most popular modeling algorithm in the market against a non-traditional algorithm using real insurance data, and the analysis reveals that the GLM over-prices perhaps half the insureds by as much as several hundred dollars above their cost!!
This isn’t a novel idea, so why hasn’t anyone executed on it? Well, we never know which algorithms or feature transforms are going to result in the best predictive models, so we essentially have to try them all. This is a ton of work; weeks or most likely months. Actuaries and data scientists are in short supply and they are buried in work. With all the projects waiting in their queue, nobody has time for that.
Until now. Automated machine learning insurance tools like DataRobot allow actuaries, data scientists, and even analysts to upload a dataset and run dozens of algorithms along with a variety of preprocessing steps in parallel and have results in a matter of minutes. DataRobot was used in the example above, producing 16 different models in addition to ensembles in under half an hour. All of these models are interpretable and immediately deployable via API.
If all insurers were to use this technology and try to get all the Bills, nobody would gain. But history tells us only a few insurers will seize this opportunity. They’ll collect all the Bills and boost their profits. And what about their competitors, the ones that refuse to see the opportunity or at a minimum fail to acknowledge the threat, what happens to them? Well… all those Teds have to go somewhere.

——————————————————————-
Bill Surrette is a lead data scientist at DataRobot. In his current role, he is working very closely with several insurance clients as they are adopting Machine Learning Automation. Bill has over 15 years of actuarial and analytics experience in the P&C insurance industry working with several Fortune 500 insurance companies. He has held a wide range of roles in predictive modeling, loss reserving, and pricing for both personal and commercial lines. In addition, he also has several years of teaching experience at both the college and high school level. Over his career, Bill has put these passions together and consistently championed the application of data science through all levels of actuarial organizations.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
