


Simple Feature Engineering to Predict No-Show Appointments. A Use Case of Interest to Healthcare Providers
Introduction
If you’re a healthcare provider, appointment no-show is a major challenge. It is a root cause of operational inefficiency because patients who do not keep their appointments prevent the doctor or specialist from using the time to help other patients. In addition, each appointment no-show costs a practice approximately $200, and since no-shows make up around 15% of all appointments, the larger opportunity costs are huge. AI can help healthcare providers tackle this problem. If they were to use a machine learning model that predicts the chance of no-show for each individual appointment, healthcare offices could look at other options, including sending automated reminders, making phone calls, and even offering transportation assistance. If we have two patients who are at high risk for no-shows, we may also consider double-booking them to ensure we utilize the providers’ time. This allows the healthcare provider to become more efficient, provide better healthcare services, and ultimately boosts its revenue.
At DataRobot, we have extensive experience helping our healthcare customers build no-show prediction models. One of the challenges of building machine learning models is the lack of historical data to train the model. This is especially true for healthcare providers, because many of them either just upgraded their data warehousing technology or are still using legacy systems. For this reason, it’s possible that many attributes for an appointment have not been recorded in the core database.
In this blog post, I’ll show you how, through some simple feature engineering, you can still achieve reasonable prediction accuracy using a dataset with limited attributes.
An Example from a Regional Hospital Consortium
The dataset I am using in this post is from a regional health consortium. Here is a snippet of the dataset. Most of the data is masked with asterisks (*) for confidentiality. Each row represents an appointment. The columns represent attributes (features) of the appointment, including time, location, provider name, NPI (National Provider Identifier), patient ID (referred to here as the MRN or Medical Record Number), and appointment duration. The last column, no_show, is our target variable. A 1 in this column indicates that the patient did not show up for the appointment.

As you can see, the dataset is quite simple—perhaps a little too simple. It doesn’t contain patient demographic information, such as age, gender, or insurance and it doesn’t contain information to describe the purpose of the appointment, such as symptoms or the type of disease. These features might be useful in predicting a no-show. For example, the type of insurance a patient has is often predictive of no-shows. Patients with high deductible plans or high co-pays may be more likely to miss appointments due to financial concerns. Patients who are experiencing severe symptoms should be more likely to show up than those who are experiencing light symptoms. Ideally, to build the most informed model, we would have these features in our dataset, but for various reasons, they aren’t in the customer’s core database. This is definitely not the end of the world. We often tell our customers that it is better to be liberal with your data. Why not spend 30 minutes in DataRobot building some models with the existing dataset to see how it performs rather than days or weeks collecting additional data?
Feature Engineering
The most important step to salvage the current dataset is to perform some simple but critical feature engineering. Because the core idea is that a patient who hasn’t shown up for an appointment in the past is intuitively more likely not to show up for the current appointment, I created these two features:
- historical_no_show_rate: The patient’s overall no-show rate before the current appointment.
- historical_provider_no_show_rate: The patient’s historical no-show rate against the provider of the current appointment.
Here is the Python script I used to create these two features. I included comments to make it easier to follow along.
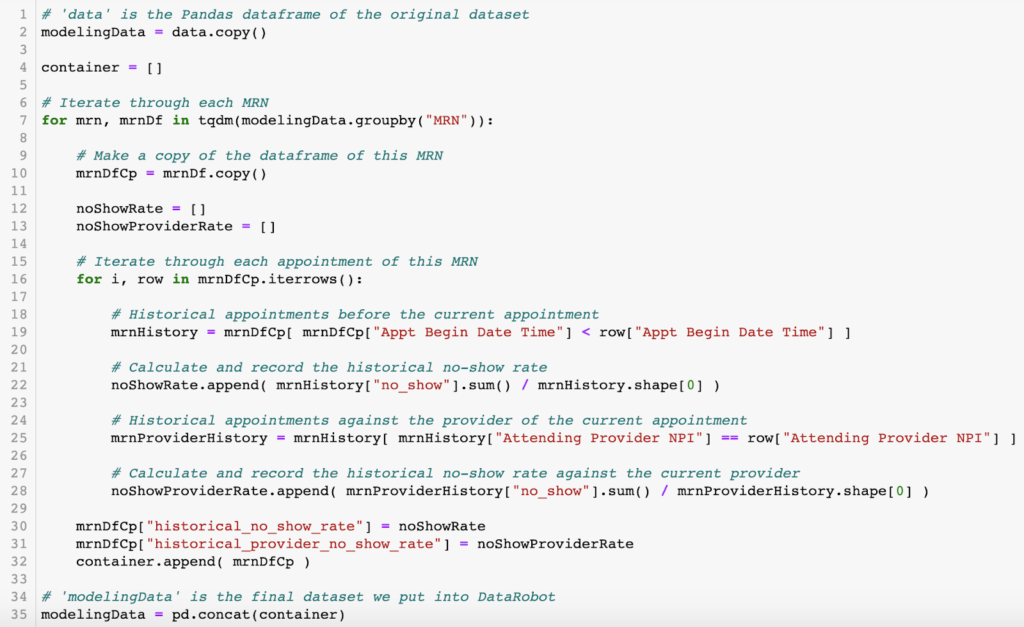
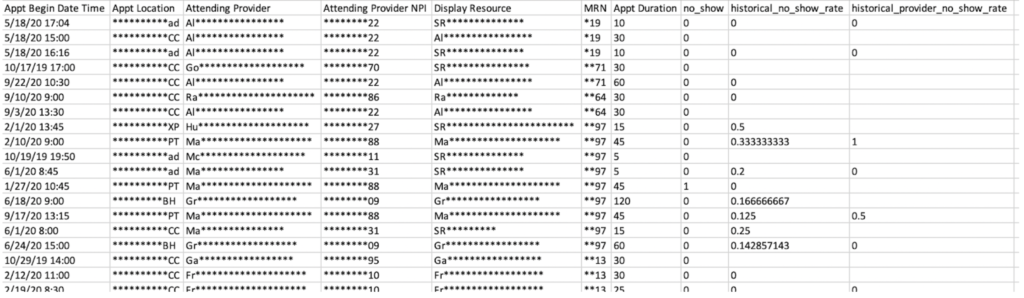
Here is a snippet of the dataset that includes the two features I created. I put this dataset into DataRobot for modeling.
Modeling in DataRobot
DataRobot automates many parts of the modeling pipeline. In this blog post, I am more focused on the use case than the generic parts of the DataRobot modeling process. For more general information about the DataRobot modeling process, including a walkthrough of automated machine learning walkthrough, explanation of model evaluation techniques and a lot more, check out the DataRobot Community page.
To build the no-show prediction model in DataRobot, I simply dragged and dropped the dataset into DataRobot, and then set no_show as the target variable. I chose the Out-of-Time Validation (OTV) mode and set Appt Begin Date Time as the primary date/time feature. Then I started the Quick Autopilot. The whole modeling process was complete in a matter of minutes.
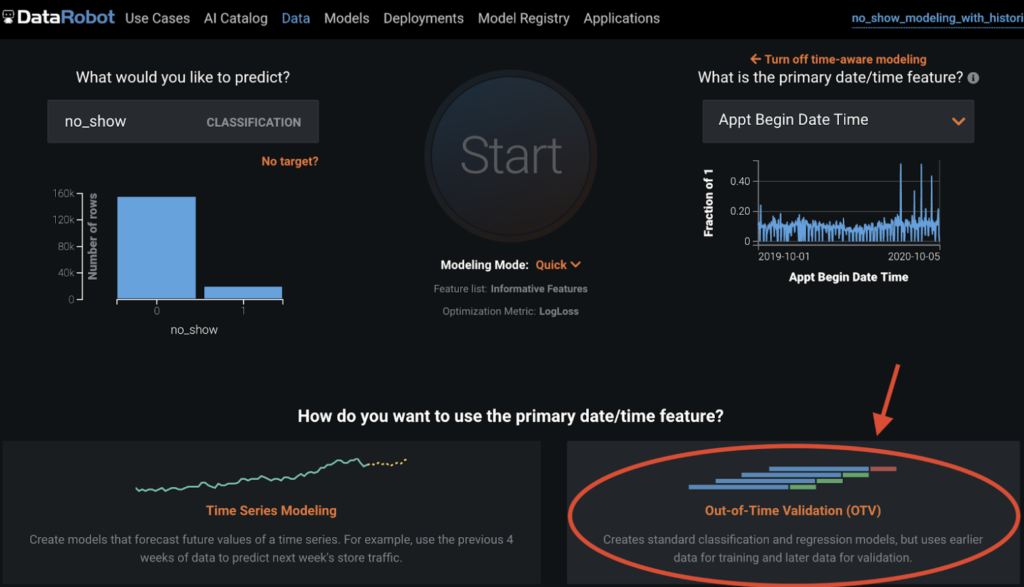
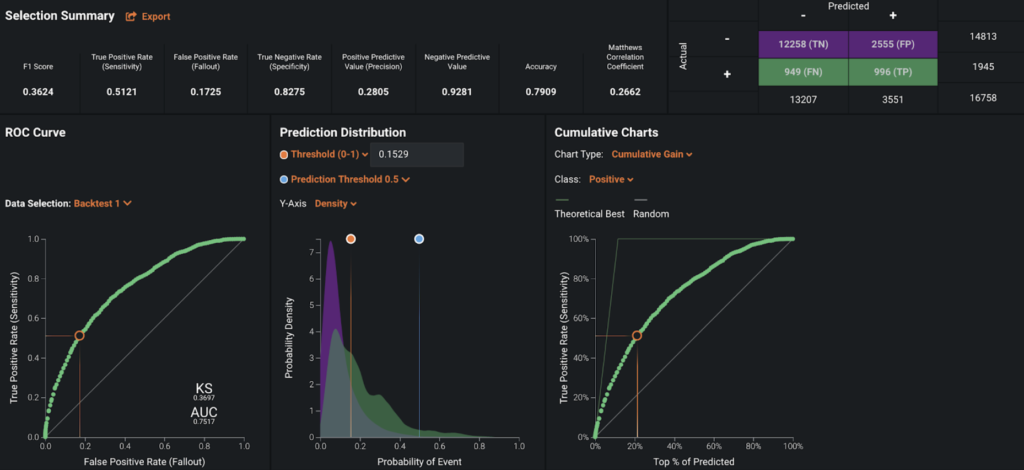
At the top of the model leaderboard is an Average Blender of an XGBoost model and a LightGBM model. Under All Backtests, you’ll see the model achieved an AUC score of 0.7334, which is not bad given the simplicity of our dataset!
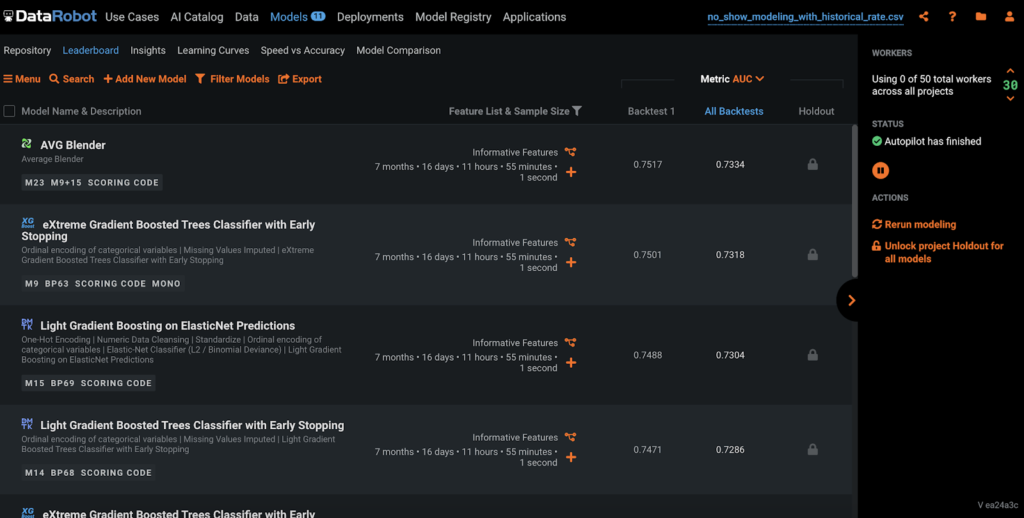
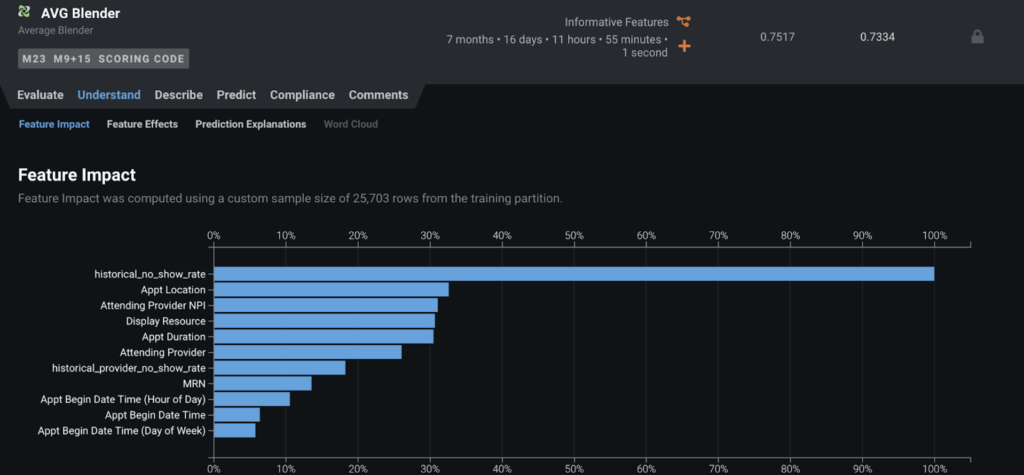
Under Feature Impact, you’ll see that both engineered features contribute significantly to the model, with historical_no_show_rate, the historical no-show rate of the patient before the current appointment, at the top of the ranking.
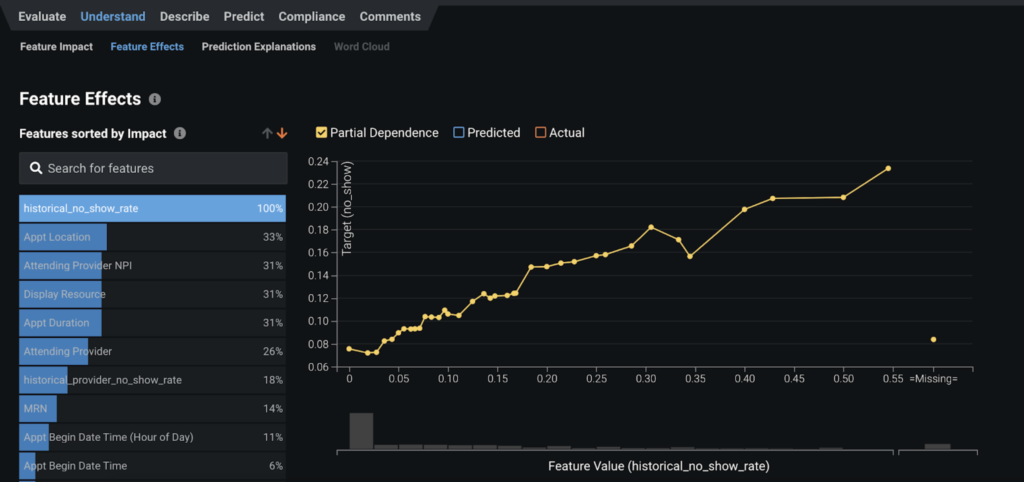
To investigate the marginal effect of a feature on the predicted outcome of the model, you can look at the partial dependence plot, which you’ll find on the Understand tab of the model in Feature Effects. As you can see from this screenshot, the predicted no-show probability monotonically increases with the historical no-show rate of the patient. This confirms our hypothesis. It also proves our engineered features are highly informative.
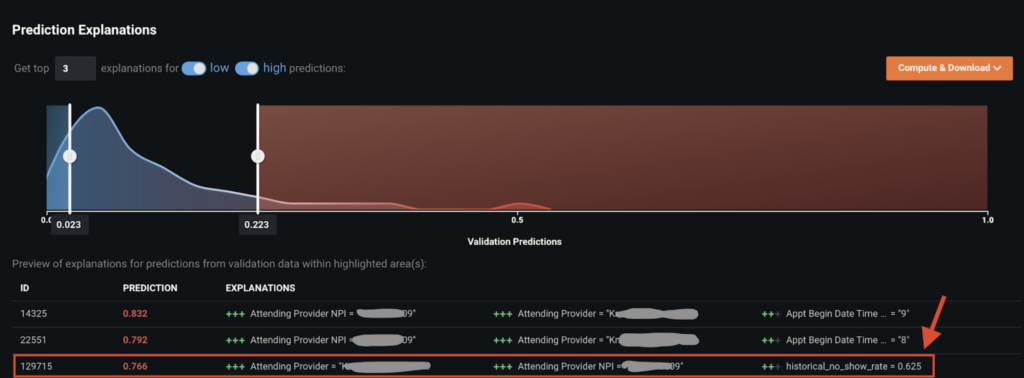
Under Prediction Explanations in the DataRobot GUI, you can see some examples of individual appointments and explanations for the DataRobot prediction. In the appointment highlighted below, DataRobot predicts that the patient has a high probability (0.766) of not showing up for the currently scheduled appointment. The top reasons for this prediction are the provider the patient is seeing and its high historical no-show rate (0.625).
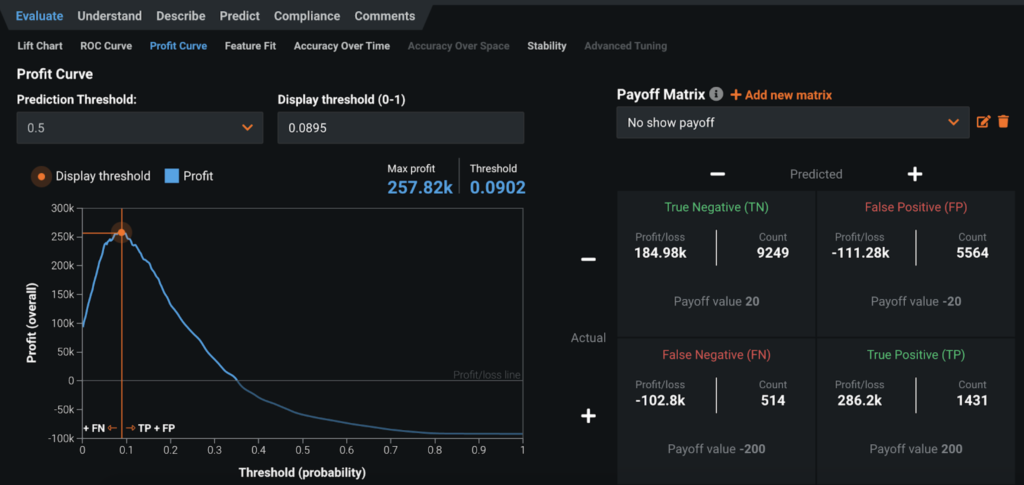
At DataRobot, we believe that model accuracy is context dependent. A smoke detector that is 99% accurate is completely unsuitable, because the cost of missing a fire is so high. On the flip side, a marketing optimization model that’s only 5% accurate may be very suitable, because the cost of outreach to a prospect is so low. DataRobot lets us assess the accuracy of our models in the context that matters. You can use the Profit Curve under the Evaluate tab to understand the business value of the model given its current predictive power, as well as determining the optimal prediction threshold. You can define the payoffs for different scenarios according to the reality at your own organization. In the screenshot, I assume that the payoffs for true positive, true negative, false positive, and false negative are respectively 200, 20, -20 and -200, and DataRobot calculates that the optimal prediction threshold is 0.0902, with 257.82k as the maximum profit.
Next Steps
Now that the model is built, you can use the DataRobot Prediction API to productionize it. You can also build a dashboard (using Tableau, for example) to further visualize the predictions, prediction explanations, and other useful information so that stakeholders and prediction consumers are well informed to make decisions. You can also try to engineer additional features to further improve the model accuracy. One potential feature is time from booking until appointment, or how many days out the appointment is made. This is another highly predictive feature based on our experience.
Conclusion
The key takeaway from building this no-show prediction model is that, even for a simple dataset with features that might not seem informative, some quick and simple feature engineering can help you build reasonably accurate models.
We are currently at a time when businesses have started to aggressively digitize their data assets and build AI capacities to accelerate growth for the next decade. We understand that many businesses still do not have rich digitized datasets, but you might be surprised by what you can achieve with your existing data. The sooner you put a model into production and start consuming the predictions, the sooner you can unlock the value of AI.
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
