

How to Understand a DataRobot Model: Drilling Down into Model Accuracy [Part 3]
The first time I took my driving test, I failed. The driving examiner said that I had very good car control, but that I failed because I didn’t use my handbrake during a hill start. Even though my hill start went well, the instructor didn’t trust that it would always go so well unless I always used the handbrake.
The same applies to AI – a good overall performance may not be enough. Even if your AI has high accuracy scores, maybe it has a weakness that is important to you. You also want to know when the AI is unsure about what to do. In such situations, you want the AI to triage the decision to a human, who can investigate and apply general knowledge and common sense.
“We should be as cautious of AI explanations as we are of each other’s—no matter how clever a machine seems. If it can’t do better than us at explaining what it’s doing … then don’t trust it.” MIT Technology Review
In the first blog of this series, we introduced the cheat sheet for how to understand a DataRobot model. In the second blog, we looked at how to compare the accuracy of different models. 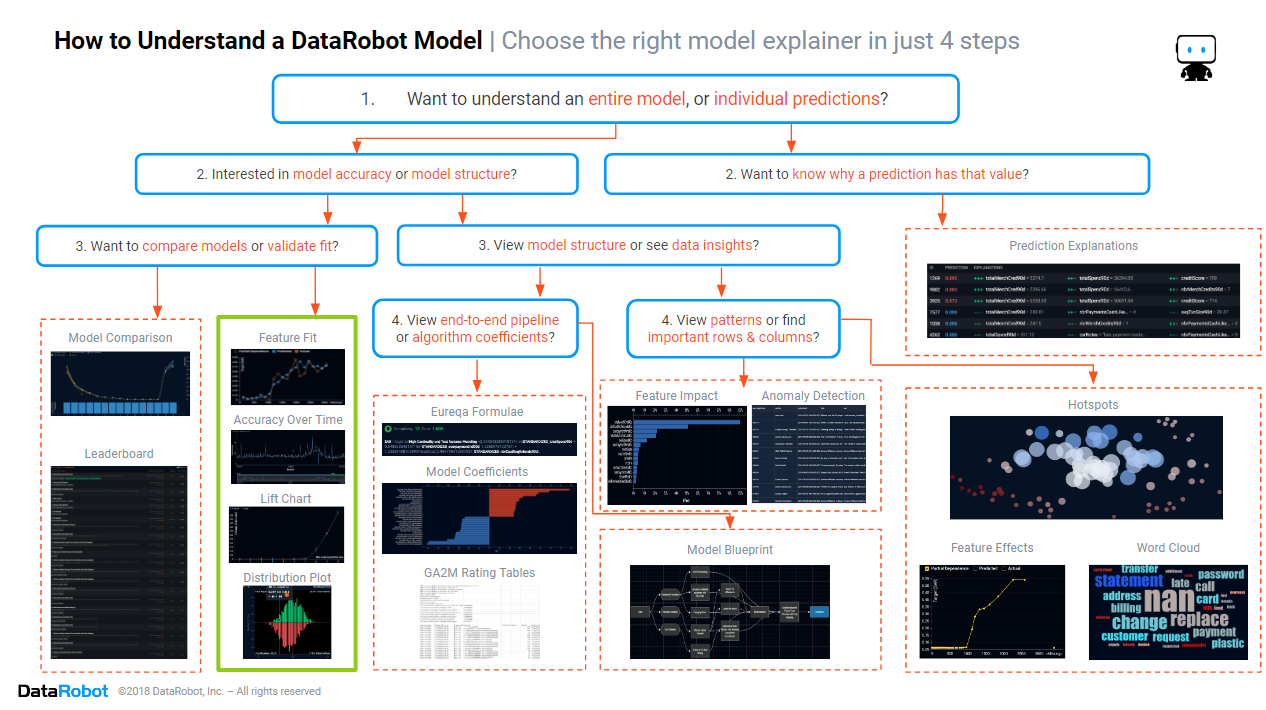
In this blog, we will focus on the section of the cheat sheet marked in green above. The focus will be on determining the circumstances for when an AI is accurate, and when it is unsure or not so accurate.
Historically, the more complex an algorithm, the more inscrutable it was. The more conservative organizations would only deploy simple algorithms that were easy to understand, but this choice was at the cost of accuracy, which sometimes proved to be very expensive. Other more competitive organizations deployed models into production without understanding their strengths and weaknesses, but this choice was at the cost of unexpected behavior, which sometimes damaged their reputation and brand value. But, the days of choosing between inaccuracy or inscrutability are coming to an end. Automated machine learning makes it possible to quickly and easily discover when the AI can be trusted to make a decision, versus when there is a difficult case that needs a friendly helping hand from humans, no matter how simple or complex the algorithm that has been used.
Feature Fit
Even if your overall model accuracy is great, your model may have a blind spot. It may be more accurate for some input values than for others, i.e. it may be more sure about some decisions than others. Some decisions may be more important to you than others e.g. decisions about VIP customers. You will want to prevent your AI from accidentally becoming biased, e.g. treating females and males differently. And if you understand where the model is more uncertain, that may give you ideas about what extra data it needs to make better decisions and improve its accuracy. To achieve these aims, you will want to drill down on the accuracy by input feature value.
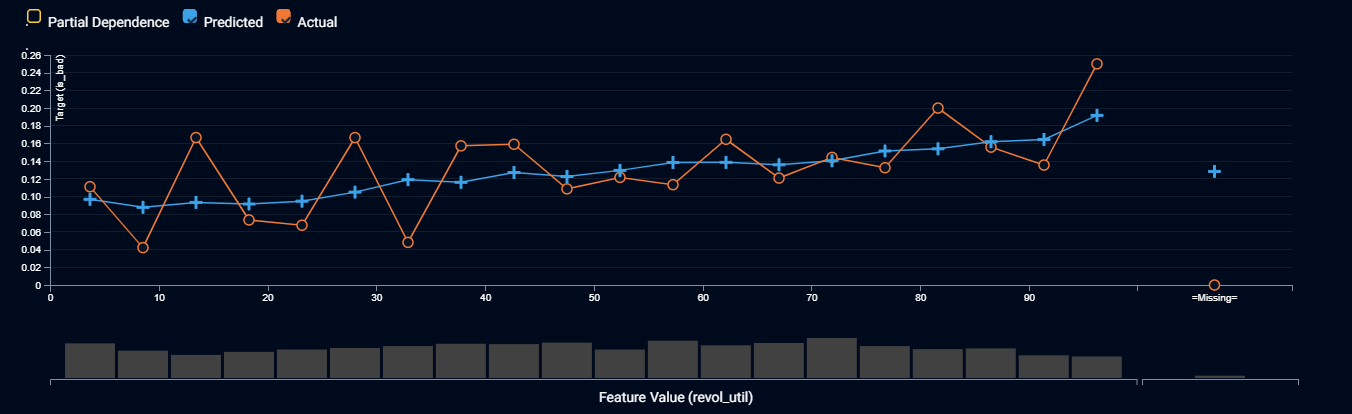
Above is a screenshot of a feature fit for a model that predicts the probability of a personal loan going bad, drilling down by the applicant’s percentage usage of their existing line of credit. The orange line is the average proportion of loans that went bad, across a range of values for line of credit usage. The blue line is the comparable average predicted probability of a loan going bad. A model is more accurate when the orange and blue lines are closer. We also prefer where the orange and blue lines cross each other frequently, and the blue line is smoother, because that means the model is capturing the underlying patterns (or signal) and ignoring mere luck (or noise).
How to Interpret the Feature Fit Chart Above:
-
The orange and blue lines cross over frequently and the blue line is smoother. So we have confidence that the model is removing luck, keeping the underlying pattern, and not generally overestimating or underestimating the outcomes.
-
The gap between the orange and blue lines is larger for lower values of line of credit usage, meaning that the model is less sure about outcomes for loan applicants who haven’t used as much of their line of credit usage than it is for loan applicants who are close to maxing out their line of credit.
Accuracy Over Time
Sometimes the process you are modeling changes over time. For example, people’s behavior is constantly changing, as is the competitive environment within which you operate. The model may be accurate for a while, but then something changes and the model is no longer as accurate. Or maybe the model accuracy is seasonal, for example, the model may be more accurate during the winter than the summer. To check the stability and accuracy of the model over time, you want to plot the accuracy across a time period.
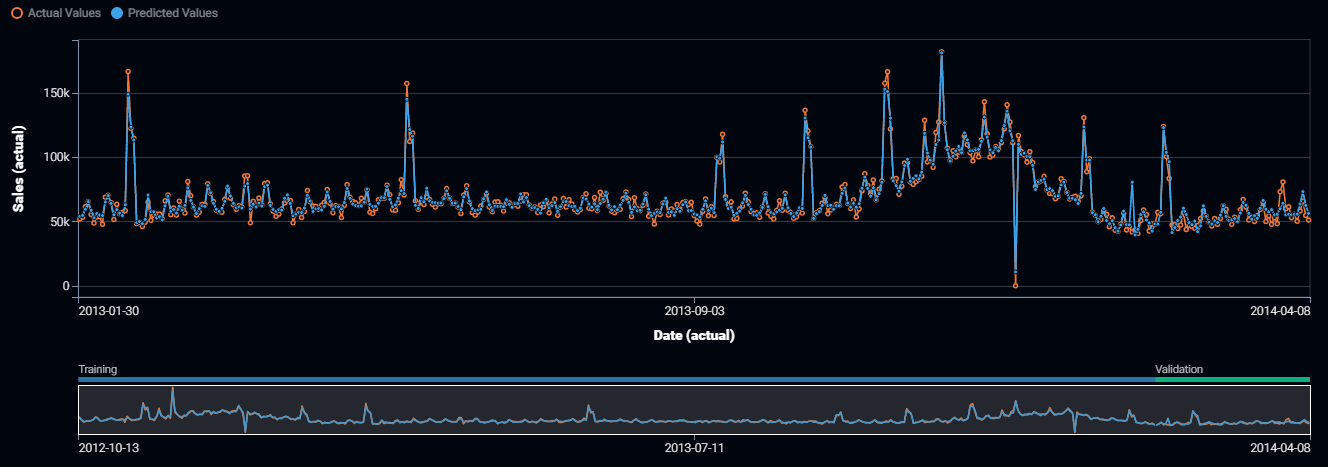
The plot above shows the accuracy over time for daily sales of a retailer. The orange line is the actual sales for each day, while the blue line is the predicted sales. A model is more accurate when the orange and blue lines are closer. We also prefer where the blue lines capture the seasonal effects evident in the data.
How to Interpret the Accuracy Over Time Plot Above:
-
The blue line follows the orange line fairly closely, following the weekly cycle and correctly capturing the highest peaks and troughs in the data. We can be comfortable that the model is correctly capturing seasonal effects and major events (such as the store being closed on Christmas Day 2013).
-
The blue line follows the orange line across the full range of dates. So we can conclude that the model accuracy is stable across time.
-
The blue line has a spike in early February 2014 that doesn’t match the data. We should investigate whether there was a holiday incorrectly specified in our data.
-
The orange line has a spike in late March 2014 that isn’t matched by the blue line. We should investigate whether there was a special event or marketing activities that weren’t included in our usual data sources.
Lift Chart
For a model to be accurate, it must be good at predicting the highs and the lows, not just the average values. Lift charts communicate accuracy by displaying how well a model can separate high values (e.g. finding those customers most likely to purchase your product) from low values (e.g. finding those customers not suited to a product offering). It also shows you how closely the model matches highs and lows in the data.
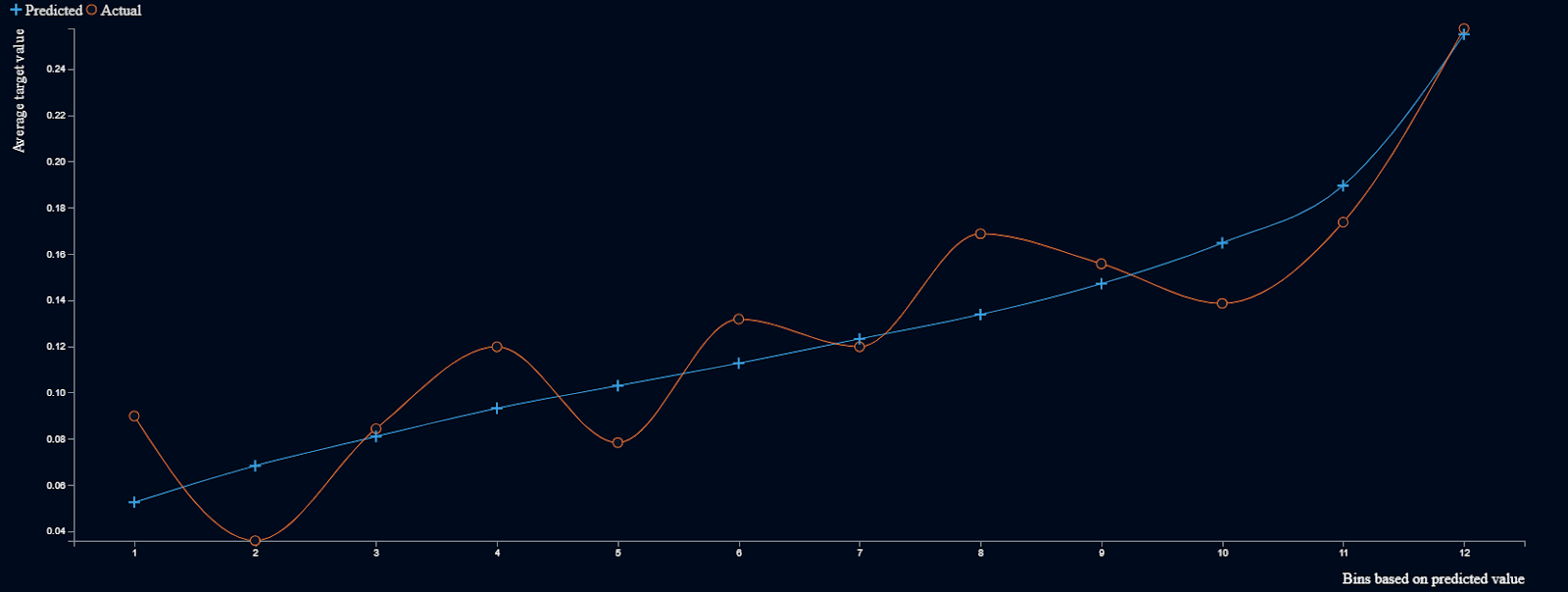
Above is a screenshot of the lift chart for a model that predicts the probability of a personal loan going bad. The orange line is the average proportion of loans that went bad, while the blue line is the comparable average predicted probability of a loan going bad. To the left of the plot are the loans that have the lowest predicted probability of going bad. To the right are the loans with the highest probability of going bad.
A model is more accurate when the orange and blue lines are close to each other. When considering accuracy across the entire range of outcomes, we also prefer where the orange and blue lines cross each other frequently, because that means that the model isn’t consistently overestimating or underestimating. Accurate models show the greatest vertical range in the actual values, the orange line. For yes / no modeling cases (binary classification) only, better models have few values in the middle of the vertical range, because that means that there are relatively few examples where the model is unsure about whether the answer is a yes or a no.
But sometimes you only care about the accuracy across a particular range. For example, if you are predicting the probability that a customer will be interested in purchasing your product, then you may care more about the accuracy for high predicted values than for low predicted values, so you can reject those loan applications. Alternatively, you care more about the accuracy in deciles 5 to 8 because those are the loans that require extra attention before you can fund them. The point is that accuracy means different things depending upon the business context, so you need to drill down into the accuracy to determine whether the model accuracy meets your needs.
How to Interpret the Lift Chart Above:
-
The orange and blue lines cross over many times, indicating that the model does not consistently overestimate or underestimate.
-
The orange and blue lines typically diverge by 0.03, and the orange line sometimes slopes downward, indicating that even though the model is predictive, it is not highly accurate. This may be because so many unexpected events can occur during the several years in which a personal loan is being paid off.
-
Both the blue and orange lines gradually slope upwards, with many values in the middle height range, and a maximum prediction of 0.27. This indicates that there are few clear yes or no predictions in these circumstances. The model may be useful for ranking the credit quality of a loan applicant, but is not as strong at predicting which specific loans will go bad.
Prediction Distribution Plot
For yes / no use cases a model will output probabilities. Sometimes the probability is exactly what you want e.g. an insurer wants to set prices using the probability that you will claim and there is no yes or no. In other cases you want the AI to make a yes or no decision, and in this case you need to turn that predicted probability into a decision. It is up to you to create a business rule that turns each output probability into a yes or a no, and this is typically done by choosing a threshold probability. Every probability above that threshold becomes a yes decision, and the remainder becomes a no decision. For example, if the probability that a customer will purchase your product is 99% then you will say yes to including them in your marketing campaign, whereas if the probability was 0.1% you choose not to include them in the campaign. Somewhere between these two ranges lies a threshold where the probability is high enough that a no decision turns into a yes decision.
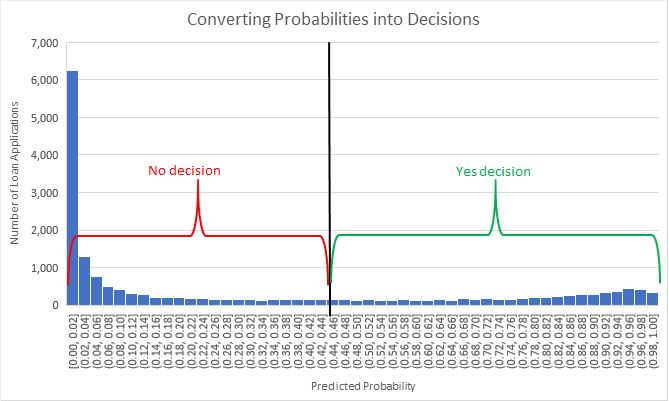
You determine the optimal probability threshold by considering the costs and benefits of each threshold. For example, you may predict the probability that a person has cancer and needs expensive and dangerous surgery:
-
A false positive occurs when you make a yes decision but the patient does not have cancer. The cost of a false positive is the cost of a surgery, plus the risks of the surgery, plus the unnecessary stress you caused to the patient.
-
A false negative occurs when you make a no decision but the patient does have cancer. The cost of a false negative is that the patient’s cancer continues to grow and spread, causing further health complications, possibly even death.
-
A true positive occurs when you correctly make a yes decision. The patient receives the surgery they require. The benefit is the better health and extended life span for the patient, less the cost of surgery.
-
A true negative occurs when you correctly make a no decision. The patient avoids unnecessary surgery and unnecessary worry.
You will choose the probability threshold that gives the optimal balance of benefits versus costs and risks. Moving the threshold higher will reduce the number of false positives (yes decisions that should have been no decisions), but at the cost of increasing the number of false negatives (no decisions that should have been yes decisions).
In most cases, some of the data rows will score a mid-range probability where there is a mix of yes and no outcomes – in such cases we may wish to triage these difficult decisions to a human. Prediction distribution plots enable us to understand the effects of different probability thresholds, and see the proportion of decisions that lie in the uncertain probability range.
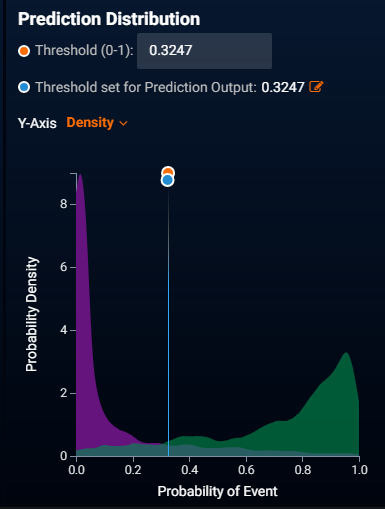
The screenshot above shows the prediction distribution plot for mortgage defaults. The purple region is a histogram of the prediction probabilities for loans that did not default. The green region is a histogram of the prediction probabilities for loans that did default. The blue line is the currently selected probability threshold for choosing yes or no decisions. An accurate model will not have much overlap between the purple and green regions. The region of decision uncertainty is where the purple and green regions overlap and neither region dominates.
How to Interpret the Prediction Distribution Plot Above:
-
Most of the purple and green regions do not overlap. This means that the model can usually clearly separate yes decisions from no decisions.
-
For the probability range of 0.2 to 0.6 neither the purple nor green region dominates. Predicted probabilities in this range will not accurately choose yes or no outcomes – the model is reasonable at ranking the credit scoring for these cases, but not at deciding a clear yes or no decision of whether the loan will go bad. If you need a clear yes or no result, rather than a probability, then you may wish to triage decisions to humans when the predicted probability lies within this range.
Conclusion
The path to trusting an AI includes knowing its strengths and weaknesses, knowing when to let it make automatic decisions, and when to triage the decision to a human. You can determine whether to trust an AI’s accuracy by drilling down to the details to discover whether the decision is more certain and where it is uncertain. Building an AI involves training multiple machine learning algorithms to find the one that best suits your needs, and the only practical way for you to quickly examine the trustworthiness of so many models is to use automated machine learning that gives you human-friendly detailed insights into the accuracy of each and every algorithm. If your AI can’t tell it where it is strong or weak, then it’s time to update to DataRobot for models that you can trust.
Click here to arrange for a demonstration of DataRobot’s human-friendly model accuracy insights.


Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
