

Four Keys to Avoiding Bias in AI
We heard in the news that “Amazon built an AI tool to hire people but had to shut it down because it was discriminating against women.” This isn’t the first time this type of problem was reported, and it won’t be the last since biased systems are a common trap companies can easily fall into.
“It’s important that we be transparent about the training data that we are using, and are looking for hidden biases in it, otherwise we are building biased systems. If someone is trying to sell you a black box system for medical decision support, and you don’t know how it works or what data was used to train it, then I wouldn’t trust it.” John Giannandrea, Google
What is Bias?
There is no generally accepted definition of bias, other than it is the opposite of fairness. A video tutorial released on YouTube early this year lists 21 different definitions for fairness in an algorithm. While there is no standard definition, there are a couple of key ways to think about it:
1) Unfair and Illegal Discrimination: Treating People Differently (When You Shouldn’t)
There are many types of illegal discrimination — the most well-known being gender and race. Yet I have seen data scientists build models that use these features when training AIs to make decisions. I recommend dropping these features as inputs.
A subtle way for discrimination to sneak into a model is when you use features that are strongly correlated with the discriminatory feature. For example, in the United States a person’s race is strongly correlated with their residential address. That is why American banks are not allowed to use zip codes when making lending decisions. This is a trap that many employers have fallen for, not realizing that the text in a resume may contain words that only a female would use.
Don’t just check for AI behavior that is illegal. Consider features that are unethical or which could cause reputation risk. Features are unethical if they unreasonably take advantage of the vulnerable. For example, I have seen price elasticity models predicting that elderly customers had lower price sensitivity (maybe because they don’t have the ability to access the internet to do price comparisons) and the business then charged them considerably higher prices. In that situation, it wasn’t illegal to charge these people more, but many would consider it unethical to take advantage of a vulnerable grandmother. Some features could cause reputation risk if your use of them became public. For example, imagine the media headlines if you built an AI that used supply and demand data to decide that customers should pay higher prices for flags during the week leading up to Independence Day!
2) Entrenching Historical Disadvantage
An AI only knows what it is taught. Just like sending a child to school, an AI must be trained. It learns by example from historical data. If you train an AI on biased data, then it will learn to make biased decisions. Data scientists, the people who build and train AIs, have similar skills to teachers and lecturers. Just as we don’t use textbooks from a hundred years ago, we shouldn’t train AIs on data that contains unfair outcomes. If the historical data contains examples of poor outcomes for disadvantaged groups, then it will learn to replicate decisions that lead to those poor outcomes.
When an AI learns to repeat human mistakes, it entrenches that behavior for the future. For example, if an AI is trained on data collected during a period during which women were less likely to be successful when applying for a job (possibly due to human bias or traditional gender roles that have become less common in recent times), then the AI will learn to prioritize men for recruitment.
Just because something happened in the past, doesn’t mean that it will happen in the future or that you ’ll want it to continue to happen into the future.
“The real safety question, if you want to call it that, is that if we give these systems biased data, they will be biased” John Giannandrea, Google
Case Study – Avoiding Bias in Your AI
A business, let’s call it Techcorp, wants to build an algorithm to sort through the large amounts of resumes they get every time they place a job advertisement. They have decided to train a machine learning algorithm on the results of their previous hiring. They track variables like age, gender, education, and other details around each applicant’s profile.
They train an algorithm on their historical data and are very satisfied when it can predict which individual applicant will get the job with high accuracy. It should save their human resources team half of the time they spend reading applications!
But that isn’t the end of the project. Elle Smith, Techcorp’s new Head of Human Resources, doesn’t trust the black box. She asks which factors the AI is using to make its decisions. The report she receives from the AI team shows her the feature impact, a measure of how important each input is when the AI is making its decisions.
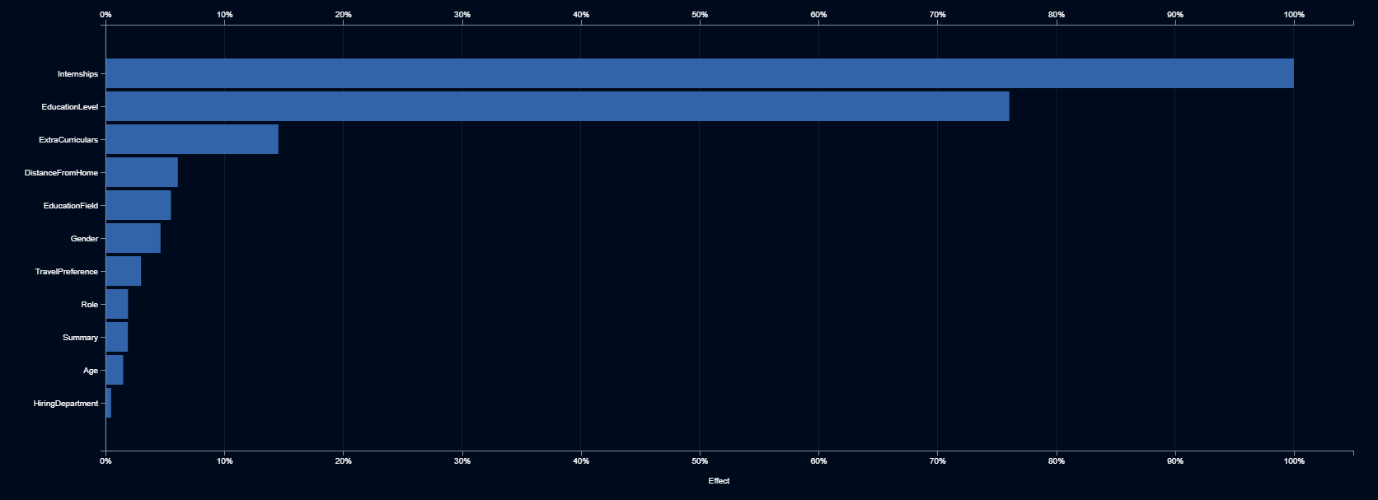
The feature impact shows her that gender is the sixth most important input. So she asks to see what the AI is doing with gender. The report she receives shows her the feature effects, a measure of what the AI does with different values for an input feature.
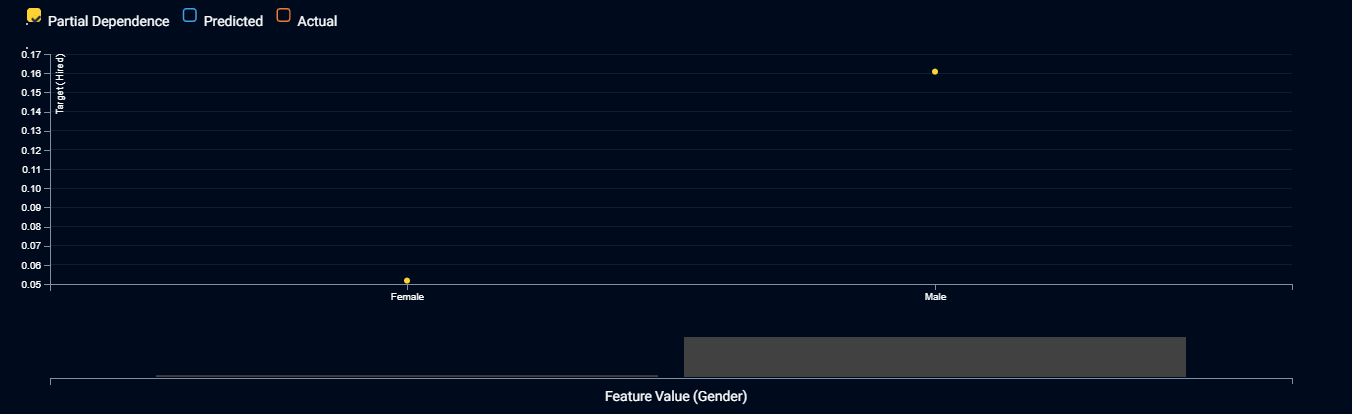
The feature effects plot shows that AI will choose males 3 times more often than females, everything else being equal. Elle declares that this is direct discrimination and is illegal, and she demands that the AI team drop gender from the model. So they build a new AI that doesn’t use gender as an input.
The AI team presents their second generation model and declares that this model is just as accurate as their first model, despite dropping the gender field, but Elle remains suspicious. Once again, she asks to see which inputs are most important, and they show her the feature impact plot.
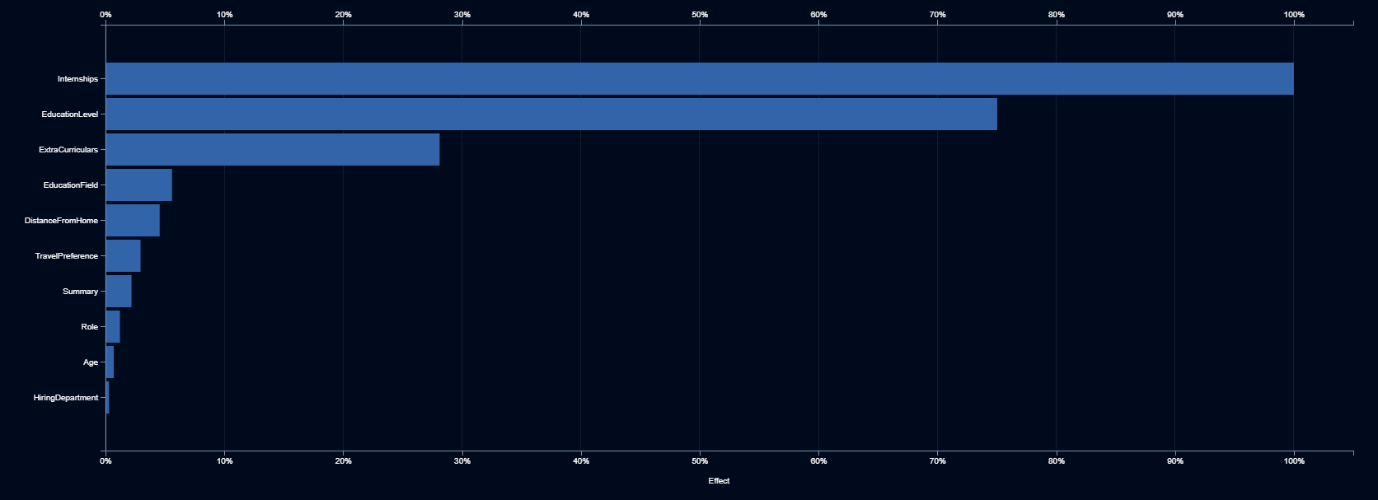
Elle notes that internships, education, and extracurricular activities are the strongest indicators. While these make sense, once again she asks to see what the AI is doing with these features. Internships and education make sense, as the more highly educated and those with more internship experience are more likely to be hired. She looks at a wordcloud for the description of extracurricular activities.

Job applicants are more likely to be hired (red colored text) if they played football, a male-dominated sport, and less likely to be hired (blue text) if they played netball or softball, female-dominated sports. Furthermore, if the job applicant was on a women’s sporting team of any type they were even less likely to be hired! The text describing extracurricular activities is just a proxy for gender. Using this text is no different from using gender.
Elle asks the AI team to identify any other features that may be a proxy for gender. They do this by building models that predict the probability that a job applicant is a female, based upon any of the other features.
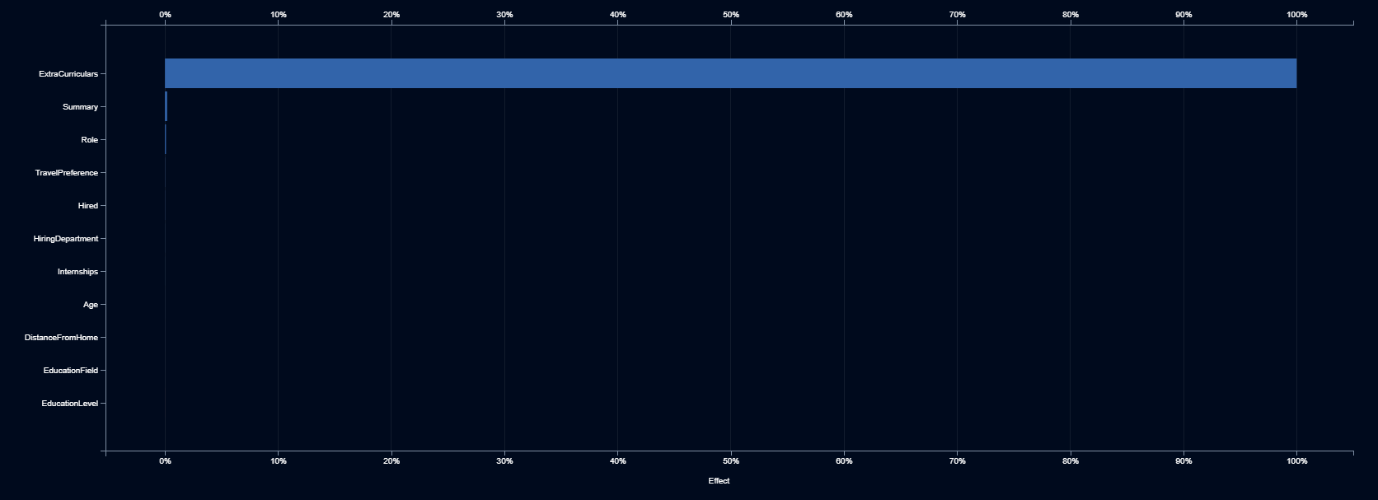
The feature impact plot shows that extracurricular activity was the only significant proxy for gender. Elle tells the AI team to not use the text from extracurricular activities.
Conclusion
It is possible for both AIs and humans to be biased, and demonstrate undesirable behavior. But it’s easier to identify and correct in AIs. Here are the four steps you can take when building your AIs:
-
Don’t trust black box models. Insist that your AI provides human-friendly explanations.
-
Check whether your model directly discriminates by looking at the feature impact, feature effects, and wordclouds.
-
Check whether your model indirectly discriminates by building models that predict the content of sensitive features (e.g. gender) using the other features.
-
Use training data that is representative of the behavior you want your AI to learn. Actively monitor new data and new outcomes and alert when the new data becomes different to the training data.
Automated machine learning makes it easy to build human-interpretable models to ensure ethical and fair AIs. If you’d like to know more or arrange a live demo, click here.

About the Author:
Colin Priest is the Director of Product Marketing for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.

Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
