

Prediction Intervals via Conformal Inference
This AI Accelerator demonstrates various ways for generating prediction intervals for any DataRobot model. The methods presented here are rooted in the area of conformal inference (also known as conformal prediction).
Request a DemoThese types of approaches have become increasingly popular for uncertainty quantification because they do not require strict distributional assumptions to be met in order to achieve proper coverage (i.e., they only require that the testing data is exchangeable with the training data). While conformal inference can be applied across a wide array of prediction problems, the focus in this notebook will be prediction interval generation on regression targets. This notebook is formatted as follows:
- Importing libraries
- Notebook parameters and helper functions
- Loading the example dataset
- Modeling building and making predictions
- Method 1: Absolute conformal
- Method 2: Signed conformal
- Method 3: Locally-weighted conformal
- Method 4: Conformalized quantile regression
- Comparing methods
- Conclusion
Note: the particulars for each method have been simplified (e.g., authors use an “adjusted” quantile level rather than the traditional quantile calculation implemented here). For a full treatment of each approach and specific algorithm details, see the cited reference papers below.
1. Importing libraries
Read about different options for connecting to DataRobot from the client. Load the remaining libraries below in the usual way.
In [1]:
# Establish connection
import datarobot as dr
print(f"DataRobot version: {dr.__version__}")
dr.Client()DataRobot version: 3.2.0
Out [1]:
<datarobot.rest.RESTClientObject at 0x10c74f970>
In [2]:
# Imports
import datarobot as dr
from datarobot.models.modeljob import wait_for_async_model_creation
import numpy as np
import pandas as pd2. Notebook parameters and helper functions
Below, you’ll have two parameters for this notebook:
- COVERAGE_LEVEL: fraction of prediction intervals that should contain the target
- TEST_DATA_FRACTION: fraction of data to holdout out and use as a testing dataset to evaluate each method
In addition, a couple functions are provided to make the following analysis easier. One of which computes the two metrics that will be used for comparison:
- Coverage: fraction of computed prediction intervals that contain the target across all rows
- Average Width: the average width of the prediction intervals across all rows
A desirable method should achieve the proper coverage at the smallest width possible.
In [3]:
# Coverage level
COVERAGE_LEVEL = 0.9
# Fraction of data to use to evaluate each method
TEST_DATA_FRACTION = 0.2In [4]:
# Courtesy of https://github.com/yromano/cqr/blob/master/cqr/helper.py
def compute_coverage(
y_test: np.array,
y_lower: np.array,
y_upper: np.array,
significance: float,
name: str = "",
) -> (float, float):
"""
Computes coverage and average width
Parameters
----------
y_test: true labels (n)
y_lower: estimated lower bound for the labels (n)
y_upper: estimated upper bound for the labels (n)
significance: desired significance level
name: optional output string (e.g. the method name)
Returns
-------
coverage : average coverage
avg_width : average width
"""
# Compute coverage
in_the_range = np.sum((y_test >= y_lower) & (y_test <= y_upper))
coverage = in_the_range / len(y_test) * 100
print(
"%s: Percentage in the range (expecting %.2f): %f"
% (name, 100 - significance * 100, coverage)
)
# Compute average width
avg_width = np.mean(abs(y_upper - y_lower))
print("%s: Average width: %f" % (name, avg_width))
return coverage, avg_width
def compute_training_predictions(model: dr.Model) -> pd.DataFrame:
"""
Computes (or gathers) the out-of-sample training predictions from a model
Parameters
----------
model: DataRobot model
Returns
-------
DataFrame of training predictions
"""
# Get project to unlock holdout
project = dr.Project.get(model.project_id)
project.unlock_holdout()
# Request or gather predictions
try:
training_predict_job = model.request_training_predictions(
dr.enums.DATA_SUBSET.ALL
)
training_predictions = training_predict_job.get_result_when_complete()
except dr.errors.ClientError:
training_predictions = [
tp
for tp in dr.TrainingPredictions.list(project.id)
if tp.model_id == model.id and tp.data_subset == "all"
][0]
return training_predictions.get_all_as_dataframe()
def quantile_rearrangement(
test_preds: pd.DataFrame,
quantile_low: float,
quantile_high: float,
) -> pd.DataFrame:
"""
Produces monotonic quantiles
Based on: https://github.com/yromano/cqr/blob/master/cqr/torch_models.py#L66-#L94
Parameters
----------
test_preds: dataframe of quantile predictions to rearrange, sorted from lowest quantile to highest
quantile_low: desired low quantile in the range (0,1)
quantile_high: desired high quantile in the range (0,1)
Returns
-------
Dataframe of rearranged quantile predictions
References
----------
.. [1] Chernozhukov, Victor, Iván Fernández‐Val, and Alfred Galichon.
"Quantile and probability curves without crossing."
Econometrica 78.3 (2010): 1093-1125.
"""
# Based on the code in the referenced function, "all_quantiles" is defined as the following:
# See https://github.com/yromano/cqr/blob/master/cqr/helper.py#L423
all_quantiles = np.linspace(0.01, 0.99, 99)
# This part remains remains the same
scaling = all_quantiles[-1] - all_quantiles[0]
low_val = (quantile_low - all_quantiles[0]) / scaling
high_val = (quantile_high - all_quantiles[0]) / scaling
# Get new values
q_fixed = np.quantile(
test_preds.values, (low_val, high_val), method="linear", axis=1
)
return pd.DataFrame(q_fixed.T, columns=test_preds.columns)3. Loading the example dataset
The dataset you’ll use comes from this DataRobot blog post. Each row represents a player in the National Basketball Association (NBA) and the columns signify different NBA statistics from various repositories, fantasy basketball news sources, and betting information. The target, game_score, is a single statistic that attempts to quantify player performance and productivity.
Additionally, you’ll partition the data into a training and testing sets. The training set will be used for modeling building / evaluation while the testing set will be used to compare each method.
In [5]:
# Load data
df = pd.read_csv(
"https://s3.amazonaws.com/datarobot_public_datasets/DR_Demo_NBA_2017-2018.csv"
)
df.head()Out [5]:
| 0 | 1 | 2 | 3 | 4 | |
| roto_fpts_per_min | NaN | NaN | NaN | NaN | NaN |
| roto_minutes | NaN | NaN | NaN | NaN | NaN |
| roto_fpts | NaN | NaN | NaN | NaN | NaN |
| roto_value | NaN | NaN | NaN | NaN | NaN |
| free_throws_lag30_mean | NaN | 0 | 1.5 | 2 | 2.5 |
| field_goals_decay1_mean | NaN | 6 | 8 | 6.285714 | 7.2 |
| game_score_lag30_mean | NaN | 8.1 | 13.35 | 10.7 | 12.15 |
| minutes_played_decay1_mean | NaN | 27.066667 | 35.511111 | 33.380952 | 30.955556 |
| PF_lastseason | 3.1 | 3.1 | 3.1 | 3.1 | 3.1 |
| free_throws_attempted_lag30_mean | NaN | 0 | 2.5 | 3 | 3.25 |
| … | … | … | … | … | … |
| team | PHO | PHO | PHO | PHO | PHO |
| opponent | POR | LAL | LAC | SAC | UTA |
| over_under | NaN | NaN | NaN | NaN | NaN |
| eff_field_goal_percent_lastseason | 0.475 | 0.475 | 0.475 | 0.475 | 0.475 |
| spread_decay1_mean | NaN | -48 | -17.333333 | -31.428571 | -13.6 |
| position | SG | SG | SG | SG | SG |
| OWS_lastseason | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| free_throws_percent_decay1 | NaN | NaN | 0.6 | 0.692308 | 0.862069 |
| text_yesterday_and_today | NaN | NaN | NaN | NaN | NaN |
| game_score | 8.1 | 18.6 | 5.4 | 16.5 | 8.4 |
In [6]:
# Distribution of target
target_column = "game_score"
df[target_column].hist()Out [6]:
<Axes: >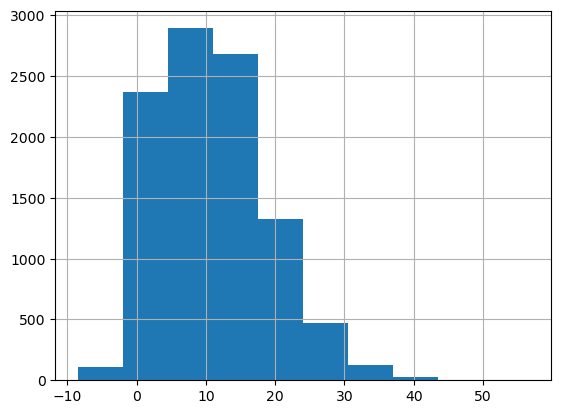
In [7]:
# Split data
df_train = df.sample(frac=1 - TEST_DATA_FRACTION, replace=False, random_state=10)
df_test = df.loc[~df.index.isin(df_train.index)]
df_train = df_train.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
print(df_train.shape)
print(df_test.shape)(7999, 52)
(2000, 52)
4. Modeling building and making predictions
To create a DataRobot project and start building models, you can use the convenient Project.start function, which chains together project creation, file upload, and target selection. Once models are finished training, you’ll retrieve the one DataRobot recommends for deployment and request predictions for both the training and testing sets. Note that the predictions made on the training dataset are not in-sample, but rather out-of-sample (i.e., also referred to as stacked predictions). These out-of-sample training predictions are a key component to each prediction interval method discussed in this notebook.
In [8]:
# Starting main project
project = dr.Project.start(
sourcedata=df_train,
project_name="Conformal Inference AIA - NBA",
target=target_column,
worker_count=-1,
)
# Wait
project.wait_for_autopilot(check_interval=120)In progress: 8, queued: 0 (waited: 0s)
In progress: 8, queued: 0 (waited: 1s)
In progress: 8, queued: 0 (waited: 1s)
In progress: 8, queued: 0 (waited: 2s)
In progress: 8, queued: 0 (waited: 4s)
In progress: 8, queued: 0 (waited: 6s)
In progress: 8, queued: 0 (waited: 10s)
In progress: 8, queued: 0 (waited: 17s)
In progress: 8, queued: 0 (waited: 30s)
In progress: 7, queued: 0 (waited: 56s)
In progress: 1, queued: 0 (waited: 108s)
In progress: 4, queued: 0 (waited: 211s)
In progress: 1, queued: 0 (waited: 332s)
In progress: 0, queued: 0 (waited: 453s)
In progress: 0, queued: 0 (waited: 574s)In [9]:
# Get recommended model
best_model = dr.ModelRecommendation.get(project.id).get_model()
best_modelOut [9]:
Model('RandomForest Regressor')
In [10]:
# Compute training predictions (necessary for each method)
training_preds = compute_training_predictions(model=best_model)
training_preds.head()Out [10]:
| row_id | partition_id | prediction | |
|---|---|---|---|
| 0 | 0 | 0.0 | 0.899231 |
| 1 | 1 | Holdout | 9.240274 |
| 2 | 2 | 0.0 | 15.043815 |
| 3 | 3 | 4.0 | 8.626567 |
| 4 | 4 | 2.0 | 15.435130 |
In [11]:
# Request predictions on testing data
pred_dataset = project.upload_dataset(sourcedata=df_test, max_wait=60 * 60 * 24)
predict_job = best_model.request_predictions(dataset_id=pred_dataset.id)
testing_preds = predict_job.get_result_when_complete(max_wait=60 * 60 * 24)
testing_preds.head()Out [11]:
| row_id | prediction | |
|---|---|---|
| 0 | 0 | 14.275717 |
| 1 | 1 | 13.238045 |
| 2 | 2 | 12.827469 |
| 3 | 3 | 14.141054 |
| 4 | 4 | 7.113611 |
In [12]:
# Join predictions training and testing datasets
df_train = df_train.join(training_preds.set_index("row_id"))
df_test = df_test.join(testing_preds.set_index("row_id"))
display(df_train[[target_column, "prediction"]])
display(df_test[[target_column, "prediction"]])| game_score | prediction | |
|---|---|---|
| 0 | 0.0 | 0.899231 |
| 1 | 0.0 | 9.240274 |
| 2 | 21.6 | 15.043815 |
| 3 | 4.4 | 8.626567 |
| 4 | 26.7 | 15.435130 |
| … | … | … |
| 7994 | 18.4 | 19.801230 |
| 7995 | 12.9 | 10.349299 |
| 7996 | 19.3 | 14.453104 |
| 7997 | 9.8 | 23.360390 |
| 7998 | 8.1 | 9.220965 |
| game_score | prediction | |
|---|---|---|
| 0 | 5.4 | 14.275717 |
| 1 | 16.5 | 13.238045 |
| 2 | 7.2 | 12.827469 |
| 3 | 23.8 | 14.141054 |
| 4 | 0.0 | 7.113611 |
| … | … | … |
| 1995 | 17.0 | 10.358305 |
| 1996 | 25.0 | 16.455246 |
| 1997 | -1.2 | 4.356278 |
| 1998 | 15.7 | 14.503841 |
| 1999 | 14.3 | 10.568885 |
In [13]:
# Compute the residuals on the training data
df_train["residuals"] = df_train[target_column] - df_train["prediction"]
df_train["residuals"].hist()
Out[13]:
<Axes: >
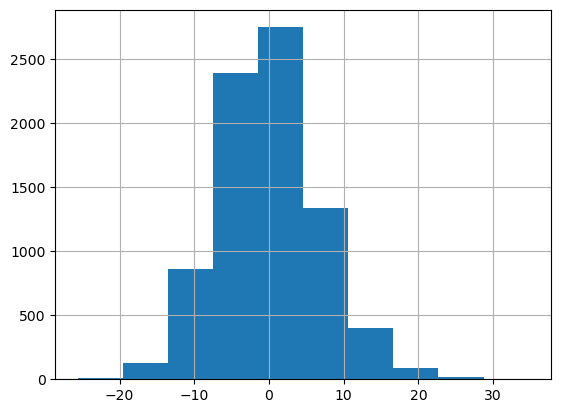
5. Method: Absolute conformal
The first method you’ll implement, regarded here as “absolute conformal”, is as follows:
- Take the absolute value of the out-of-sample residuals (these will be the conformity scores)
- Compute the quantile associated with the specified COVERAGE_LEVEL on the conformity scores
- Add and subtract this quantile value to the prediction
The resulting prediction intervals are guaranteed to be symmetric and the same width (since you’re simply applying a scalar value across all rows). For more information regarding this approach, see Section 2.3.
In [14]:
# Compute the conformity
df_train["abs_residuals"] = df_train["residuals"].abs()
abs_residuals_q = df_train["abs_residuals"].quantile(COVERAGE_LEVEL)
abs_residuals_qOut [14]:
11.028431310477108
In [15]:
# Using the conformity score, create the prediction intervals
df_test["method_1_lower"] = df_test["prediction"] - abs_residuals_q
df_test["method_1_upper"] = df_test["prediction"] + abs_residuals_qIn [16]:
# Compute metrics
method_1_coverage = compute_coverage(
y_test=df_test[target_column].values,
y_lower=df_test["method_1_lower"].values,
y_upper=df_test["method_1_upper"].values,
significance=1 - COVERAGE_LEVEL,
name="Absolute Conformal",
)Absolute Conformal: Percentage in the range (expecting 90.00): 89.000000
Absolute Conformal: Average width: 22.0568636. Method: Signed conformal
“Signed conformal” follows a very similar procedure as the previous one:
- Compute lower and upper quantile levels based on the specified COVERAGE_LEVEL
- Apply these quantile levels to the out-of-sample residuals (i.e., conformity scores)
- Add these quantile values to the prediction
The main advantage to this approach over the previous one is that the prediction intervals are not forced to be symmetric, which can lead to better coverage for skewed targets. For more information regarding this approach, see Section 3.2.
In [17]:
# Compute lower and upper quantile levels to use based on the coverage
lower_coverage_q = round((1 - COVERAGE_LEVEL) / 2, 2)
upper_coverage_q = COVERAGE_LEVEL + (1 - COVERAGE_LEVEL) / 2
lower_coverage_q, upper_coverage_qOut [17]:
(0.05, 0.95)
In [18]:
# Compute quantiles on the conformity scores
residuals_q_low = df_train["residuals"].quantile(lower_coverage_q)
residuals_q_high = df_train["residuals"].quantile(upper_coverage_q)
residuals_q_low, residuals_q_highOut [18]:
(-10.573999229291612, 11.617478915155703)
In [19]:
# Using the quantile levels, create the prediction intervals
df_test["method_2_lower"] = df_test["prediction"] + residuals_q_low
df_test["method_2_upper"] = df_test["prediction"] + residuals_q_highIn [20]:
# Compute coverage / width
method_2_coverage = compute_coverage(
y_test=df_test[target_column].values,
y_lower=df_test["method_2_lower"].values,
y_upper=df_test["method_2_upper"].values,
significance=1 - COVERAGE_LEVEL,
name="Signed Conformal",
)Signed Conformal: Percentage in the range (expecting 90.00): 88.900000
Signed Conformal: Average width: 22.191478
7. Method: Locally-weighted conformal
While the primary advantage of the previous two methods is their simplicity, the disadvantage is that each prediction interval ends up being the exact same width. In many cases, it’s desirable to have varying widths that reflect the degree of confidence (i.e., harder to predict rows get a larger prediction interval and vice versa). To this end, you can make them more adaptive by using an auxiliary model to help augment the width on a per-row basis, depending on how much error we’d expect to see in a particular row. The “locally-weighted conformal” method is as follows:
- Take the absolute value of the out-of-sample residuals
- Build a model that regresses against the absolute residuals using the same feature set
- Compute the out-of-sample predictions from the absolute residuals model
- Scale the out-of-sample residuals using the the auxillary model’s predictions to create the conformity scores
- Compute the quantile associated with the specified COVERAGE_LEVEL on the conformity scores
- Multiply this quantile value and the auxillary model’s predictions together (this will result in a locally-weighted offset to apply, specific to each row)
- Add and subtract this multiplied value to each prediction
Although this approach is more involved, it addresses the disadvantage above by making the prediction intervals adaptive to each row while still being symmetric. For more information regarding this approach, see Section 5.2.
In [21]:
# Starting project to predict absolute residuals
project_abs_residuals = dr.Project.start(
sourcedata=df_train.drop(
columns=[
target_column,
"partition_id",
"prediction",
"residuals",
],
axis=1,
),
project_name=f"Predicting absolute residuals from {project.project_name}",
target="abs_residuals",
worker_count=-1,
)
project_abs_residuals.wait_for_autopilot(check_interval=120)In progress: 8, queued: 0 (waited: 0s)
In progress: 8, queued: 0 (waited: 1s)
In progress: 8, queued: 0 (waited: 1s)
In progress: 8, queued: 0 (waited: 2s)
In progress: 8, queued: 0 (waited: 3s)
In progress: 8, queued: 0 (waited: 5s)
In progress: 8, queued: 0 (waited: 9s)
In progress: 8, queued: 0 (waited: 16s)
In progress: 8, queued: 0 (waited: 29s)
In progress: 7, queued: 0 (waited: 55s)
In progress: 1, queued: 0 (waited: 108s)
In progress: 3, queued: 0 (waited: 211s)
In progress: 1, queued: 0 (waited: 331s)
In progress: 0, queued: 0 (waited: 452s)
In progress: 0, queued: 0 (waited: 572s)In [22]:
# Get recommended model
best_model_abs_residuals = dr.ModelRecommendation.get(
project_abs_residuals.id
).get_model()
best_model_abs_residuals
Out [22]:
Model('RandomForest Regressor')
In [23]:
# Compute training predictions and join
df_train = df_train.join(
compute_training_predictions(model=best_model_abs_residuals)
.rename(columns={"prediction": f"abs_residuals_prediction"})
.set_index("row_id")
.drop(columns=["partition_id"], axis=1)
)
In [24]:
# Now compute prediction on testing data and join
pred_dataset_abs_residuals = project_abs_residuals.upload_dataset(
sourcedata=df_test, max_wait=60 * 60 * 24
)
df_test = df_test.join(
best_model_abs_residuals.request_predictions(
dataset_id=pred_dataset_abs_residuals.id
)
.get_result_when_complete(max_wait=60 * 60 * 24)
.rename(columns={"prediction": f"abs_residuals_prediction"})
.set_index("row_id")
)In [25]:
# Now we need to compute our locally-weighted conformity score and take the quantile
scaled_abs_residuals = df_train["abs_residuals"] / df_train["abs_residuals_prediction"]
scaled_abs_residuals_q = scaled_abs_residuals.quantile(COVERAGE_LEVEL)
scaled_abs_residuals_qOut [25]:
2.0517307447009157
In [26]:
# Using the conformity score and absolute residuals model, create the prediction intervals
df_test["method_3_lower"] = (
df_test["prediction"] - df_test["abs_residuals_prediction"] * scaled_abs_residuals_q
)
df_test["method_3_upper"] = (
df_test["prediction"] + df_test["abs_residuals_prediction"] * scaled_abs_residuals_q
)In [27]:
# Compute coverage / width
method_3_coverage = compute_coverage(
y_test=df_test[target_column].values,
y_lower=df_test["method_3_lower"].values,
y_upper=df_test["method_3_upper"].values,
significance=1 - COVERAGE_LEVEL,
name="Locally-Weighted Conformal",
)Locally-Weighted Conformal: Percentage in the range (expecting 90.00): 89.800000
Locally-Weighted Conformal: Average width: 21.710734
8. Method: Conformalized Quantile Regression
If you consider “locally-weighted conformal” to be a model-based extension of “absolute conformal”, then you could consider “conformalized quantile regression” to be a model-based extension of “signed conformal.” The goal is similar – create more adaptive prediction intervals, but it inherits the quality that the prediction intervals are not forced to be symmetric. The reference paper offers a symmetric and asymmetric formulation for the conformity scores. The former (Theorem 1) “allows coverage errors to be spread arbitrarily over the left and right tails” while the latter (Theorem 2) controls “the left and right tails independently, resulting in a stronger coverage guarantee” at the cost of slightly wider prediction intervals. Here, you’ll use the symmetric version. The full method is as follows:
- Compute lower and upper quantile levels based on the specified COVERAGE_LEVEL
- Train two quantile regression models at the lower and upper quantile levels on the training set
- Compute the out-of-sample predictions for both quantile models
- Compute the conformity scores, E, such that E = max[^qlower – y, y – ^qupper] where у is the target, ^qlower is the lower quantile predictions, and ^qupper is the upper quantile predictions
- Compute the quantile associated with the specified COVERAGE_LEVEL on E
- Add and subtract this quantile value to the quantile predictions
Notably, this approach is completely independent of your main model. That is, it doesn’t use any information about the recommended model defined earlier. This may or may not be desired, depending on the user’s preference or use case requirements. To ensure the main model’s predictions fall within the prediction interval, you’ll simply extend the interval’s boundary to be equal to the prediction itself (if the prediction lies outside of the respective prediction interval). Additionally, when using non-linear quantile regression methods (e.g., tree-based approaches, neural networks), it’s possible to experience quantile crossing (i.e., non-monotonic quantile predictions). To combat this, the referenced paper offers a solution via rearrangement, which is implemented here.
There are two ways to run quantile regression models in DataRobot:
- Set the project metric to quantile loss (which is currently a public-preview feature)
- Use certain blueprints with algorithms that support quantile loss as a hyperparameter in your current project. These includes gradient boosted trees from scikit-learn and Keras neural networks.
In this notebook, you’ll use the second approach, since it’s generally available. This involves using DataRobot’s advanced tuning functionality to change the loss function to the desired quantile loss.
In [28]:
# Get a GBT from scikit-learn (using the first one)
models = project.get_models()
gbt_models = [x for x in models if x.model_type.startswith("Gradient Boosted")]
# Check for GBT model. If none, make one.
if gbt_models:
# Get most accurate one on validation set
gbt_model = gbt_models[0]
else:
# Pull models (will usually be at least one blueprint with a scikit-learn GBT)
gbt_bps = [
x
for x in project.get_blueprints()
if x.model_type.startswith("Gradient Boosted")
]
# Get first one
gbt_bp = gbt_bps[0]
# Train it
gbt_model = wait_for_async_model_creation(
project_id=project.id,
model_job_id=project.train(gbt_bp),
max_wait=60 * 60 * 24,
)
gbt_modelOut [28]:
Model('Gradient Boosted Greedy Trees Regressor with Early Stopping (Least-Squares Loss)')
In [29]:
# Train it on all the data
model_job_id = gbt_model.train(
sample_pct=100,
featurelist_id=gbt_model.featurelist_id,
)
gbt_model_100 = wait_for_async_model_creation(
project_id=project.id, model_job_id=model_job_id, max_wait=60 * 60 * 24
)
gbt_model_100
Out [29]:
Model('Gradient Boosted Greedy Trees Regressor with Early Stopping (Least-Squares Loss)')
In [30]:
# Train quantile models
quantile_models = {lower_coverage_q: None, upper_coverage_q: None}
# Tune main keras model
for q in quantile_models.keys():
# Start
tune = gbt_model_100.start_advanced_tuning_session()
# Set loss and level
tune.set_parameter(
task_name=gbt_model_100.model_type, parameter_name="loss", value="quantile"
)
tune.set_parameter(
task_name=gbt_model_100.model_type, parameter_name="alpha", value=q
)
# Save job
quantile_models[q] = tune.run()
# Wait and get resulting models
for q in quantile_models.keys():
quantile_models[q] = quantile_models[q].get_result_when_complete(
max_wait=60 * 60 * 24
)
quantile_models
Out [30]:
{0.05: Model('Gradient Boosted Greedy Trees Regressor with Early Stopping (Quantile Loss)'),
0.95: Model('Gradient Boosted Greedy Trees Regressor with Early Stopping (Quantile Loss)')}In [31]:
# Compute training predictions
for q in quantile_models.keys():
df_train = df_train.join(
compute_training_predictions(model=quantile_models[q])
.rename(columns={"prediction": f"quantile_prediction_{q}"})
.set_index("row_id")
.drop(columns=["partition_id"], axis=1)
)
# Check
df_train[
[
target_column,
f"quantile_prediction_{lower_coverage_q}",
f"quantile_prediction_{upper_coverage_q}",
]
]Out[31]:
| game_score | quantile_prediction_0.05 | quantile_prediction_0.95 | |
|---|---|---|---|
| 0 | 0.0 | -0.661701 | 7.367953 |
| 1 | 0.0 | -0.109510 | 16.625219 |
| 2 | 21.6 | 3.752373 | 24.534147 |
| 3 | 4.4 | 0.521447 | 18.209039 |
| 4 | 26.7 | 1.367213 | 26.972765 |
| … | … | … | … |
| 7994 | 18.4 | 4.882632 | 35.834840 |
| 7995 | 12.9 | 0.879488 | 18.311118 |
| 7996 | 19.3 | 1.235300 | 23.512004 |
| 7997 | 9.8 | 5.622114 | 32.164047 |
| 7998 | 8.1 | -0.046493 | 19.430948 |
In [32]:
# Making prediction on test data
quantile_models_test_predict = quantile_models.copy()
for q in quantile_models.keys():
quantile_models_test_predict[q] = quantile_models[q].request_predictions(
dataset_id=pred_dataset.id
)
# Joining the results
for q in quantile_models.keys():
df_test = df_test.join(
quantile_models_test_predict[q]
.get_result_when_complete(max_wait=60 * 60 * 24)
.rename(columns={"prediction": f"quantile_prediction_{q}"})
.set_index("row_id")
)
# Check
df_test[
[
target_column,
f"quantile_prediction_{lower_coverage_q}",
f"quantile_prediction_{upper_coverage_q}",
]
]Out[32]:
| game_score | quantile_prediction_0.05 | quantile_prediction_0.95 | |
|---|---|---|---|
| 0 | 5.4 | 0.918277 | 25.233671 |
| 1 | 16.5 | 1.488291 | 25.160815 |
| 2 | 7.2 | 0.315117 | 24.488930 |
| 3 | 23.8 | 0.864427 | 23.131123 |
| 4 | 0.0 | 0.239838 | 21.055298 |
| … | … | … | … |
| 1995 | 17.0 | -0.113189 | 23.151948 |
| 1996 | 25.0 | 5.386518 | 23.425884 |
| 1997 | -1.2 | -1.631877 | 22.678644 |
| 1998 | 15.7 | 2.107615 | 23.573162 |
| 1999 | 14.3 | 3.644082 | 22.918123 |
In [33]:
# Implement quantile rearrangement
q_crossing_train = (
df_train[f"quantile_prediction_{lower_coverage_q}"]
> df_train[f"quantile_prediction_{upper_coverage_q}"]
).sum()
q_crossing_test = (
df_test[f"quantile_prediction_{lower_coverage_q}"]
> df_test[f"quantile_prediction_{upper_coverage_q}"]
)
print(
f"Number of rows with quantile crossing in training set (before rearrangement): {q_crossing_train}"
)
print(
f"Number of rows with quantile crossing in testing set (before rearrangement): {q_crossing_test}"
)
# Capture quantile columns
quantile_pred_cols = [x for x in df_train.columns if x.startswith("quantile")]
# On training set
df_train = df_train.drop(quantile_pred_cols, axis=1).join(
quantile_rearrangement(
test_preds=df_train[
[
f"quantile_prediction_{lower_coverage_q}",
f"quantile_prediction_{upper_coverage_q}",
]
],
quantile_low=lower_coverage_q,
quantile_high=upper_coverage_q,
)
)
# On testing set
df_test = df_test.drop(quantile_pred_cols, axis=1).join(
quantile_rearrangement(
test_preds=df_test[
[
f"quantile_prediction_{lower_coverage_q}",
f"quantile_prediction_{upper_coverage_q}",
]
],
quantile_low=lower_coverage_q,
quantile_high=upper_coverage_q,
)
)
# Check again
q_crossing_train = (
df_train[f"quantile_prediction_{lower_coverage_q}"]
> df_train[f"quantile_prediction_{upper_coverage_q}"]
).sum()
q_crossing_test = (
df_test[f"quantile_prediction_{lower_coverage_q}"]
> df_test[f"quantile_prediction_{upper_coverage_q}"]
)
print(
f"Number of rows with quantile crossing in training set (after rearrangement): {q_crossing_train}"
)
print(
f"Number of rows with quantile crossing in testing set (after rearrangement): {q_crossing_test}"
)Number of rows with quantile crossing in training set (before rearrangement): 7
Number of rows with quantile crossing in testing set (before rearrangement): 0 False
1 False
2 False
3 False
4 False
...
1995 False
1996 False
1997 False
1998 False
1999 False
Length: 2000, dtype: bool
Number of rows with quantile crossing in training set (after rearrangement): 0
Number of rows with quantile crossing in testing set (after rearrangement):
0 False
1 False
2 False
3 False
4 False
...
1995 False
1996 False
1997 False
1998 False
1999 False
Length: 2000, dtype: boolIn [34]:
# Now we compute our conformity score and take the quantile
E_cqr = np.maximum(
df_train[f"quantile_prediction_{lower_coverage_q}"] - df_train[target_column],
df_train[target_column] - df_train[f"quantile_prediction_{upper_coverage_q}"],
)
E_cqr_q = E_cqr.quantile(COVERAGE_LEVEL)
E_cqr_qIn [34]:
1.7189887578306196In [35]:
# Create the prediction intervals
df_test["method_4_lower"] = df_test[f"quantile_prediction_{lower_coverage_q}"] - E_cqr_q
df_test["method_4_upper"] = df_test[f"quantile_prediction_{upper_coverage_q}"] + E_cqr_qIn [36]:
# Extend to make sure the prediction is inside the interval
df_test["method_4_lower"] = df_test[["method_4_lower", "prediction"]].min(axis=1)
df_test["method_4_upper"] = df_test[["method_4_upper", "prediction"]].max(axis=1)In [37]:
# Compute coverage / width
method_4_coverage = compute_coverage(
y_test=df_test[target_column].values,
y_lower=df_test["method_4_lower"].values,
y_upper=df_test["method_4_upper"].values,
significance=1 - COVERAGE_LEVEL,
name="Conformalized Quantile Regression",
)Conformalized Quantile Regression: Percentage in the range (expecting 90.00): 89.700000
Conformalized Quantile Regression: Average width: 21.706370
9. Comparing methods
Below you can see that the more advanced methods (i.e., “locally-weighted conformal” and “conformalized quantile regression”) yield similar coverage rates while producing smaller prediction intervals on average. Notably, this is just one dataset, and it’s suggested to empirically experiment with your own data to find the best method for your use case.
In [38]:
# Organize
summary = pd.DataFrame(
{
"Coverage": [
method_1_coverage[0],
method_2_coverage[0],
method_3_coverage[0],
method_4_coverage[0],
],
"Average Width": [
method_1_coverage[1],
method_2_coverage[1],
method_3_coverage[1],
method_4_coverage[1],
],
"Method": [
"Absolute Conformal",
"Signed Conformal",
"Locally-Weighted Conformal",
"Conformalized Quantile Regression",
],
}
)
summaryOut[38]:
| Coverage | Average Width | Method | |
|---|---|---|---|
| 0 | 89.0 | 22.056863 | Absolute Conformal |
| 1 | 88.9 | 22.191478 | Signed Conformal |
| 2 | 89.8 | 21.710734 | Locally-Weighted Conformal |
| 3 | 89.7 | 21.706370 | Conformalized Quantile Regression |
10. Conclusion
This notebook demonstrates how one could build prediction intervals for any DataRobot model using methods derived from the conformal inference space. Conformal inference is a popular framework to use for generating such prediction intervals because they don’t require strict distributional assumptions to achieve the desired coverage, so long as the testing data is exchangeable with the training data. This characteristic was confirmed in the analysis done here. Because each approach offers different pros and cons, it’s worthwhile to use this AI Accelerator as a starting point for your own experiments to decide which one to implement for your use case. DataRobot offers the ability to easily implement each of these methods, even for the more advanced techniques. For more information on the topic of conformal inference, see the following introductory paper.
Explore more AI Accelerators
-
HorizontalObject Classification on Video with DataRobot Visual AI
This AI Accelerator demonstrates how deep learning model trained and deployed with DataRobot platform can be used for object detection on the video stream (detection if person in front of camera wears glasses).
Learn More -
HorizontalReinforcement Learning in DataRobot
In this notebook, we implement a very simple model based on the Q-learning algorithm. This notebook is intended to show a basic form of RL that doesn't require a deep understanding of neural networks or advanced mathematics and how one might deploy such a model in DataRobot.
Learn More -
HorizontalDimensionality Reduction in DataRobot Using t-SNE
t-SNE (t-Distributed Stochastic Neighbor Embedding) is a powerful technique for dimensionality reduction that can effectively visualize high-dimensional data in a lower-dimensional space.
Learn More -
HorizontalMLFlow + DataRobot API for Tracking Experimentation
As illustrated below, you will use the orchestration notebook to design and run the experiment notebook, with permutations of parameters handled automatically. At the end of the experiments, copies of the experiment notebook will be available, with the outputs for each permutation for collaboration and reference.
Learn More