

Maximize Conversion Rates for Online Email Promotions
Overview
Business Problem
The competition among businesses to acquire customer attention has never been higher. In 2019, marketers around the world spent over $132 billion on digital advertising, and that number is projected to grow upwards of $160 billion by 2022. The growth in advertising is fueled by the increasing difficulty of acquiring new customers, particularly in an online environment that is becoming more fragmented as new players constantly enter the market. When it comes to email promotions, marketers increasingly struggle with making sure each promotion they send stands out amid all the emails customers receive on a daily basis. Emails that are irrelevant to the customers’ desires will end up in spam, along with all future emails sent by the same business. The traditional marketing play is to deploy randomized or rules-based logic to assign promotional offers; however, the competitive edge has shifted to businesses deploying targeted promotions rooted in data-driven decision making.
Intelligent Solution
As customers become more overwhelmed with the advertisements they receive from various channels, AI helps marketers improve the response rates of their email promotions through greater personalization. Specifically, AI enables marketers to predict which email promotions customers will respond to based on each customer’s unique attributes and purchase history. The components of a promotion (i.e., product category) can also be simulated to identify which promotion will lead to the highest uplift in response. Additionally, AI informs marketers of the top drivers behind each prediction, allowing them to have a granular understanding of why customers are likely or unlikely to respond.
By leveraging the AI-provided insights into each customer’s unique needs, marketers can increase their response rates, pay-per-clicks, and revenue. As a byproduct of effective targeted promotions, marketers can also realize higher customer retention rates and drive positive externalities to other aspects of their business.
Technical Implementation
About the Data
For illustrative purposes, we have created a synthetic dataset which we will use in this guide. The dataset includes features on past offers.
Problem Framing
To develop the propensity model, the target variable (the outcome we’d like to predict) is whether or not the customer will click on a promotional email (i.e., the customer provides a response).
A recommended solution is a combination of propensity and uplift modeling to determine the optimal offer for each customer. Here’s what each modeling framework can answer:
- Propensity Modeling: What is the likelihood that a customer will click this promotion?
- Uplifting Modeling: What is the best promotion we can offer to maximize the response rate against a baseline?
When used in combination, these two modeling frameworks allow companies to determine the optimal promotion tailored to customer-level attributes. At a high-level, we’ll train a single model to predict response rates then simulate various promotional offers to calculate uplift.
Ideally, in building likelihood of response (propensity) and uplift models, data is collected properly through randomized A/B testing. If A/B testing is not implemented during the data collection phase, model assumptions can fail and lead to suboptimal predictions.
The key failure point will be inappropriately assigning a baseline click-through rate, which is difficult to measure without a true control group from randomized testing, thereby making uplift modeling ineffective. However, in practice, many customers still find successful uplift in redemption even without A/B testing.
The dataset collected from A/B testing should follow a schema similar to the dataset below, where the business has collected information—on a customer level—around the product category displayed, control vs test group, the actual promotion offered, and if the customer responded (i.e., clicked).
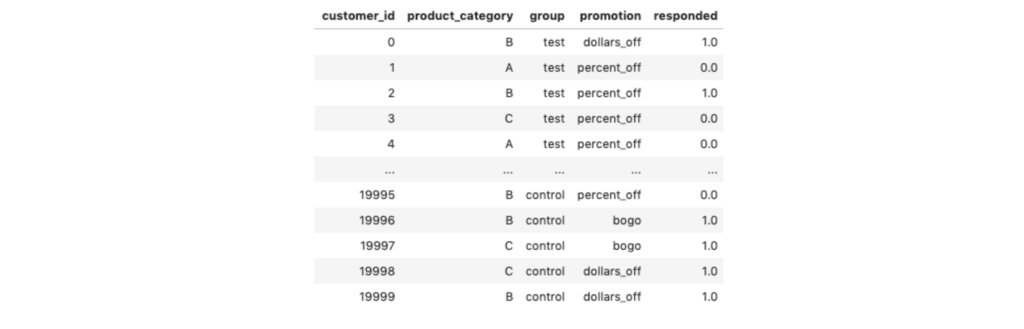
Additional features at the customer level include parts of the RFM framework (recency, frequency, monetary). It’s also recommended to pull in demographic-related data (e.g., zip code, gender, age, etc.) as these features often add predictive power.
In practice, you will have additional features that you collect on your customer. As you will see, DataRobot can help you quickly differentiate which features are important or unimportant; therefore, you should add them to begin with if you think they may be relevant to predicting customer response.
Sample Feature List
The modeling data is configured to capture whether someone responded to an offer based on customer level attributes and product category. There are a number of advantages to training a model based on this framework:
- Single model in production
- Flexible to new target variables
- Can extend to new offer categories and product categories (with retraining)

Data Preparation
We use the DataRobot AI Catalog to store the modeling dataset. In addition to providing a centralized place to manage connections, AI Catalog allows us to maintain a versioned history of the dataset for easy project creation, a high-level summary of all the features, and the ability to quickly share with colleagues.
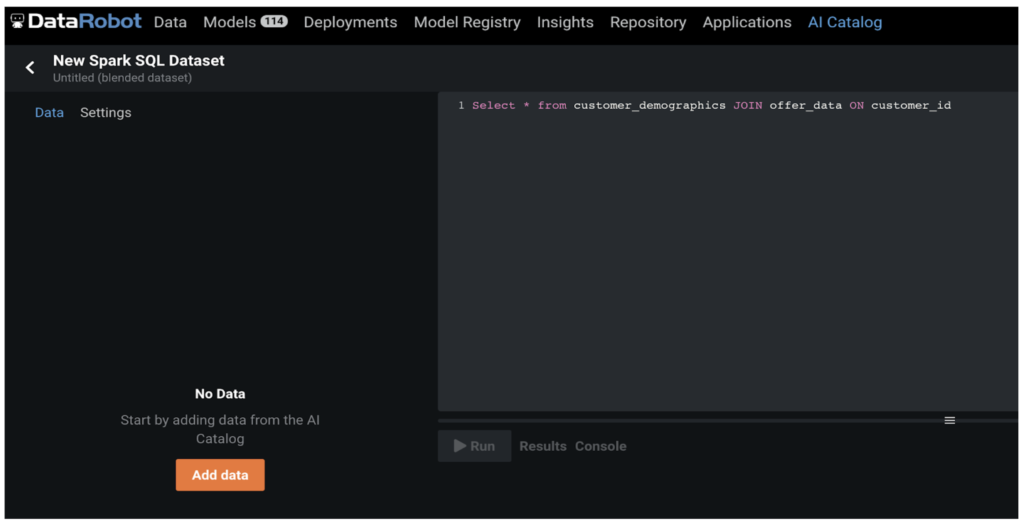
We join our datasets on past offers and customer demographics using the feature, customer_id.
Model Training
DataRobot Automated Machine Learning automates many parts of the modeling pipeline. Instead of hand-coding and manually testing dozens of models to find the one that best fits your needs, DataRobot automatically runs dozens of models and finds the most accurate one for you.
Take a look here to see how to use DataRobot from start to finish and how to understand the data science methodologies embedded in its automation.
Several points to highlight for this use case are:
- The modeling process for this use case follows a two-step process:
- Build a propensity model to assess the likelihood of customer response based on the promotion.
- Simulate promotions and calculate uplift to determine the optimal promotion for a product category. This step is done after the modeling process has finished.
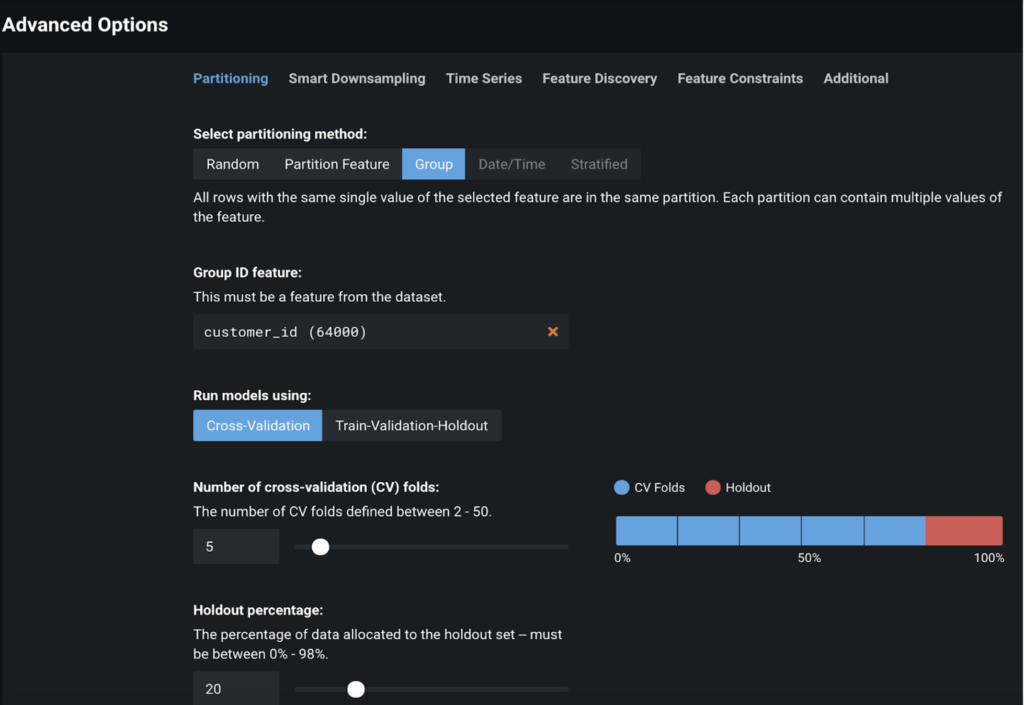
- Before we click Start and ask DataRobot to build models and find the most suitable one, we need to configure some advanced options. Namely, we’ll need to perform Group Partitioning on customer_id. This ensures that a single customer ID is either in the train or test set, but doesn’t occur in both. The group partition ultimately helps prevent overfitting on customers and gives us a more realistic sense of model performance. Additionally, group partition also ensures the model generalizes well to new customers.
Interpret Results
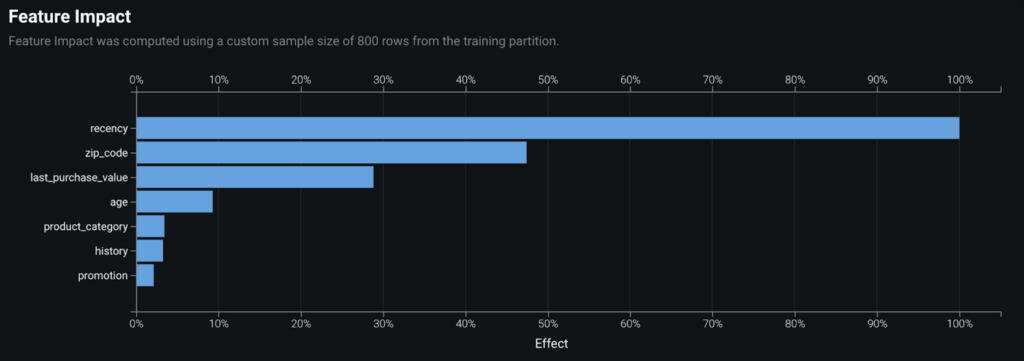
Once we find the best model, we can ask “How can I understand the predictions my model is making?” In the Understand tab, Feature Impact is the best place to start. It’s a clean and easy way to interpret which features are important and can help develop trust in predictions. This visualization answers the question “As a whole, which feature plays the most important role in making my model accurate?” Here we see that recency is the most impactful feature, followed by zip_code and last_purchase_value.
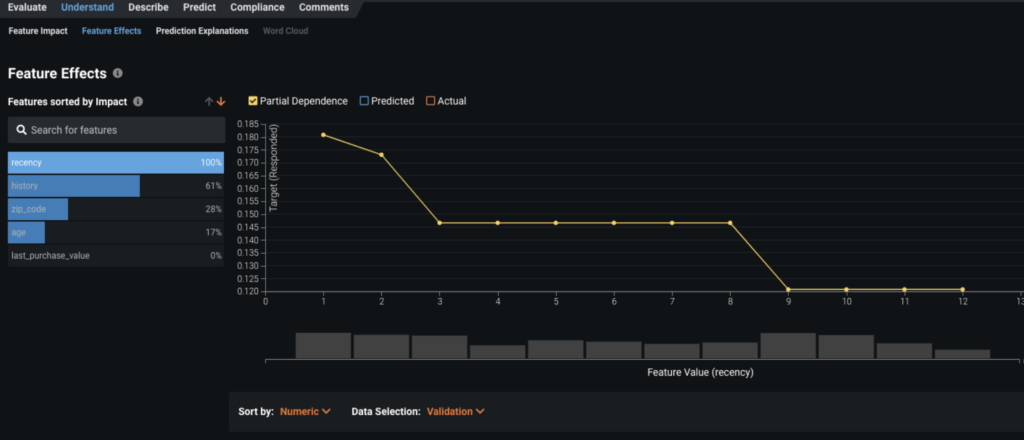
We take a look at the partial dependence plots (in Feature Effects) to further evaluate the marginal impact top features have on the predicted outcome. We learn that the more recently a customer visited the website, the more likely they are to respond to the promotion. As we go further back in time (12 being furthest out) we see a sharp drop in probability to respond.
Evaluate Accuracy
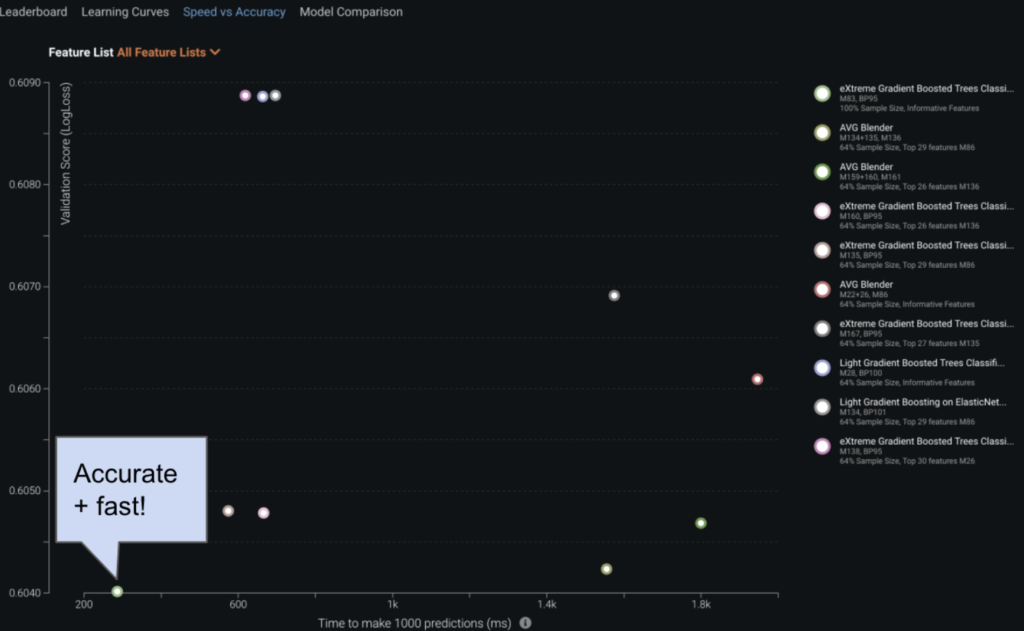
In understanding which model is ‘best’ for the use case, we can look at the Speed vs Accuracy visualization. For a subset of the most accurate models, this chart plots the time to make 1000 predictions on the X-axis against the model’s performance in terms of LogLoss (our default project metric) on the Y-axis. There is a clear winner in our example below: an XGBoost model with the lowest LogLoss is also the fastest model.
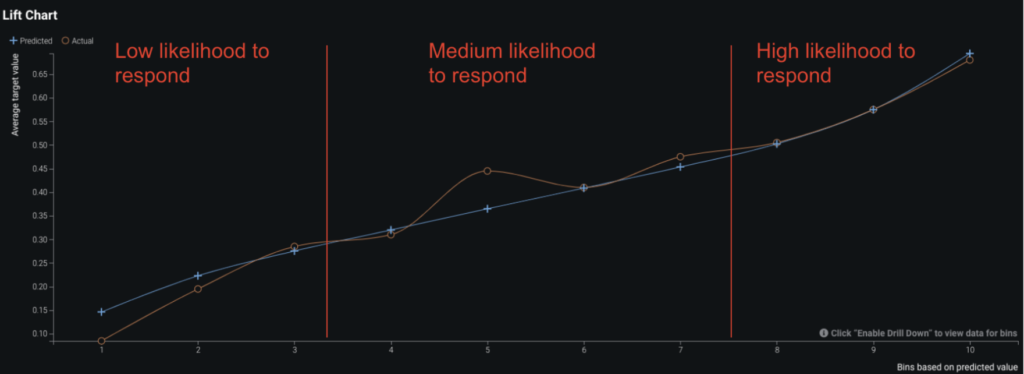
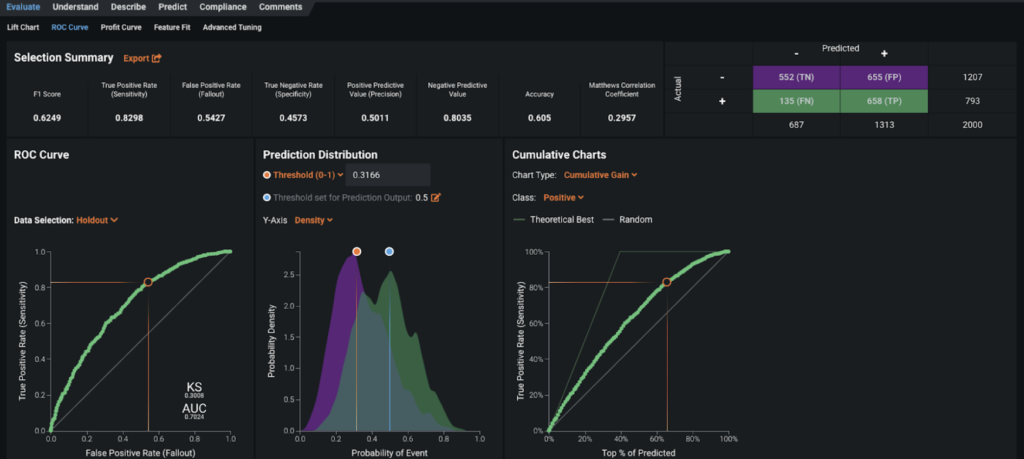
In researching the accuracy of our model, we use DataRobot’s suite of evaluation tools to answer “How well is my model performing?” We start by looking at the Lift Chart of the top model. The Lift Chart displays our average model performance at various likelihoods to respond, starting with the lowest likelihood to respond in bin 1 and moving to most likely at bin 10. We can see that our model is doing a good job of predicting the customers most likely to respond. In the context of this use-case we may want to focus on the middle, meaning customers who are on the fence about responding. This is the group that, given effective promotions, could be encouraged to take action.
The ROC Curve tab allows you to check how well the prediction distribution captures the classification separation. You can use the provided Confusion Matrix to explore the appropriate threshold for separating the positive group from the negative group. For our purpose, the positive group contains customers likely to respond, while the negative group would not take action.
Post-Processing
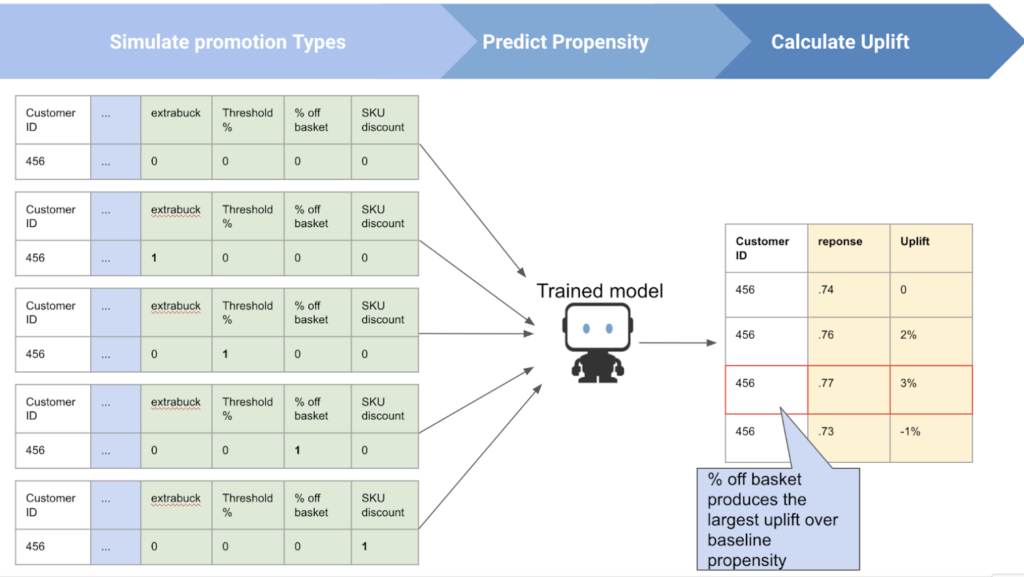
Post-processing is key in this use-case framework for calculating uplift based on cycling through (i.e., simulating) over various types and product categories to determine an optimal promotion. This can either be scripted using DataRobot’s Python API, or done directly using the Optimization App. There is flexibility in how product category data is used, which is dependent on the marketing decision makers. On one hand it can be simulated as a decision in the uplift calculation; in this scenario, the product category would be cycled through just as the possible promotions types. On the other hand, if the product category must be fixed due to business constraints, it can be set as a constant while other promotion-related features are simulated.
The graphic below depicts how the uplift component comes together. By creating a dataframe that contains multiple rows of the same customer but changing which promotion type is offered (i.e., changing the promotion feature), we are able to score the propensity to respond across various offer types on a customer-level basis. Given these predictions we can then calculate the uplift (i.e., which promotion provides the largest increase to propensity to respond) against a no-offer baseline.
Business Implementation
Decision Environment
After you inspect the model, DataRobot makes it easy to deploy the model into your desired decision environment. Decision environments are the methods by which predictions will ultimately be used for decision-making.
Decision Maturity
Automation | Augmentation | Blend
Assigning optimal promotions can be entirely automated by leveraging uplift scores to select from predefined choices of promotions per product category. Marketing managers can still review predictions and augment offers depending on business rules (e.g., only a certain number of percent-off offers can be distributed).
Model Deployment
For this use case, the predictions can be deployed using the DataRobot API. (You can learn more about the various DataRobot deployment options here.)
Predictions can be integrated with your marketing automation application of choice. We recommend the below workflow which leverages the marketing automation API. An example includes HubSpot, where as seen below you can set up a data pipeline that delivers DataRobot’s predictions to HubSpot, automatically initiating offers within the business rules you set. Note that prediction cadence should match the frequency at which promotions are rolled out. For example if the promotions are emailed and valid for 2 weeks, the below workflow should be executed on a bi-weekly basis to match promotion distribution. In practice, this cadence should be determined by marketing managers and can be anywhere from daily to upward of monthly-level promotions.
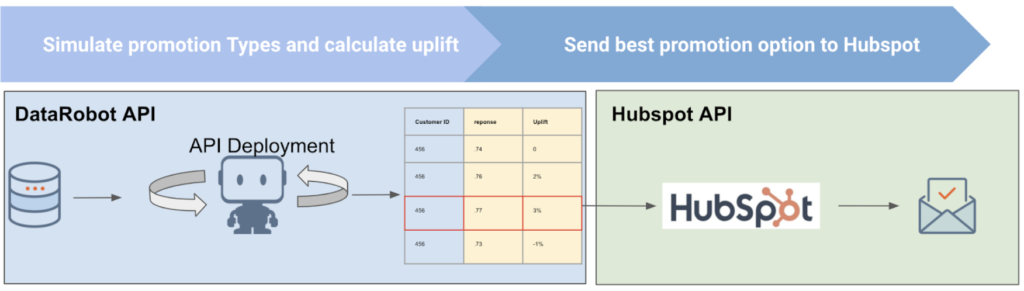
In addition to automating offers, the predictions can also be visualized in a BI dashboard or report for your marketing managers to access. These will provide them with both quantitative and qualitative insights to further their understanding of their target market, and enable them to discover the top drivers of not only what makes a good customer, but also what makes a good product.
Decision Stakeholders
Decision Executors
- Product managers, marketing managers
Decision Managers
- Chief marketing officer
Decision Authors
- Marketing analysts
Model Monitoring
Model performance can be monitored in MLOps once deployed through the API. MLOps functionality will enable data scientists to monitor the propensity model in terms of service health and data drift. This data drift is particularly important to monitor for this use case because it will show if underlying customer characteristics are shifting, indicating it’s time to retrain.
Implementation Risks
- Data
- Failure to target the right group of people
- Failure to conduct AB testing
- Failure to gather relevant customer RFM data
- Modeling
- No signal in marketing promotion data
- Model is not retrained at a regular cadence
- Model monitoring
- Be aware of class imbalance (don’t use accuracy!)
- Business
- Failure to effectively communicate results to business stakeholders and build trust in marketing automation with ML
- Failure to bring in domain experts in marketing

Experience the DataRobot AI Platform
Less Friction, More AI. Get Started Today With a Free 30-Day Trial.
Sign Up for Free
Explore More Use Cases
-
Industry AgnosticScore Incoming Job Applicants
Identify the most-qualified candidates from a broader pool of job applicants.
Learn More -
Industry AgnosticPredict Optimal Marketing Attribution
Optimize your marketing attribution by discovering which combination of touch points will lead to the highest amount of conversions.
Learn More -
Industry AgnosticPredict Employee Happiness and Anticipate Turnover
Nurture your workforce by predicting the future happiness of employees and proactively reduce the likelihood of employee churn or turnover.
Learn More -
Industry AgnosticClassify Customers into Predefined Categories
Better understand your customers by categorizing them into predefined customer segments.
Learn More