

Data Science Fails: Ignoring Business Rules and Expertise
There is a saying in science and statistics, “Correlation does not imply causation.” While records of this phrase go back to the 1880s, it has become more popular and widely used since the 1990s. The phrase cautions against concluding that one event causes another based solely upon observed data, without the use of rigorously designed experiments. For example, the chart below shows the historical relationship between the number of Japanese cars sold in the USA versus the number of suicides caused by crashing a motor vehicle.
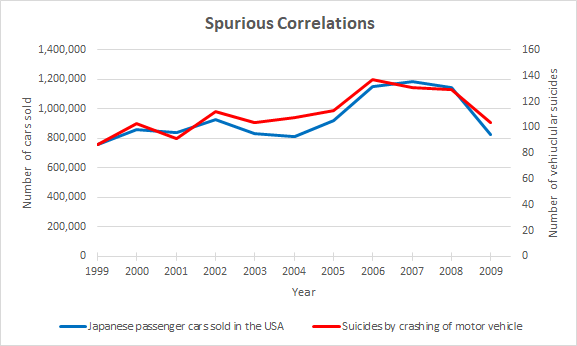
Even with quite a high correlation coefficient of 94%, it hardly seems reasonable to conclude that purchasing a Japanese car is a leading cause of severe clinical depression. This apparent relationship may be caused by a third factor, such as economic conditions, or it may even be coincidence. Sometimes a correlation means absolutely nothing, and the apparent relationship is purely accidental, just purely due to luck. Unless we can find a plausible mechanism by which one affects the other, we should exercise skepticism.
Nowadays, we have unprecedented access to data, plus the computing power and advanced algorithms to find correlations. But as the number of data fields increases, so does the likelihood that we are merely finding spurious correlations. It is not enough to merely find predictive accuracy, we also need to allow for business rules, the wealth of expertise available, and broader sources of rigorous evidence.
Case Study: Eradicating Cancer
In 2011, IBM Watson wowed the tech industry and cemented a place in pop culture with its win against two of Jeopardy’s greatest ever champions. Ken Jennings and Brad Rutter were the best players the show had produced over its decades-long run. Ken had the longest unbeaten run with 74 consecutive wins, while Brad had earned the highest total prize pool. On the other hand, Watson, named after the founder of IBM, had never competed on Jeopardy. Building a computer system to play Jeopardy is not easy. First, it must parse complicated wordplay in the clues, then search massive text databases to find possible answers, and finally determine which answer is the best. IBM researchers trained Watson by giving it thousands of Jeopardy clues and possible responses that had been manually labelled as correct or incorrect. From this data, Watson discovered patterns and made a model for how to get from an input (a clue) to an output (a correct response). While Watson was not able to solve every question correctly, it proved itself capable of outperforming the best human players.
With a convincing Jeopardy win behind it, Watson was looking for a new challenge. By turning its natural language processing abilities to medicine, Watson could read patients’ health records as well as textbooks, peer-reviewed journal articles, lists of approved drugs, etc. Maybe, with access to all this data, Watson might find patterns and solutions that no human could ever spot. In October 2013, IBM announced that The University of Texas MD Anderson Cancer Center would use Watson “for its mission to eradicate cancer.”
However, rather than playing to Watson’s strengths in natural language processing, and linking questions to answers from a text database, Watson was only trained on a small number of “synthetic” cancer cases, or hypothetical patients. It was not trained on real patient data. IBM’s internal documents show that the training recommendations were based on the expertise of a few specialists for each cancer type, instead of “guidelines or evidence.” Records show that the number of training cases varied for different types of cancer, from only 635 cases for lung cancer, down to only 106 training cases for ovarian cancer. The results showed that these training cases were not enough for Watson to learn how to make accurate decisions.
Healthcare is not like Jeopardy; if you make a mistake competing in Jeopardy you can still win, but if you make a mistake in healthcare someone’s life could be put at risk. Internal IBM documents show that Watson often gave erroneous cancer treatment advice and that company medical specialists and customers identified “multiple examples of unsafe and incorrect treatment recommendations.” For example, Watson recommended that a 65-year-old man with newly diagnosed lung cancer and evidence of severe bleeding be given combination chemotherapy and a drug called bevacizumab. However, bevacizumab, sold under the brand name Avastin, comes with a warning that it can lead to “severe or fatal hemorrhage” and shouldn’t be administered to patients experiencing severe bleeding.
Conclusion
While the case study above may suggest that AIs cannot help with healthcare, that is far from the case. For example, a recent systematic review and meta-analysis published in The Lancet concluded that automated diagnosis from medical imaging can “achieve equivalent levels of diagnostic accuracy compared with healthcare professionals.” With the demand for diagnostic imaging exceeding the supply of specialists in many countries, the use of AIs might address this resourcing shortfall. There are many successful healthcare AI use cases, such as identifying patients at risk of sepsis infection or predicting which patients will miss their medical appointment.
When AI is being asked to make decisions with significant consequences, such as life and death healthcare recommendations, it needs to be trustworthy. But if you don’t use enough training examples, you risk the AI learning spurious correlations. If you ignore business rules, such as warnings on medications, and only rely on pattern detection, you risk that your AI will make dangerous decisions. If you use synthetic data, you risk that your AI won’t learn how to solve real-life problems. The more consequential your AIs decisions, the greater the care you must apply.
For AI you can trust, follow best data science practices:
- Don’t make an AI learn something you already know. Don’t discard prior knowledge. Feature engineer the business rules and expertise into the algorithm. For example, this may involve using offsets or monotonicity constraints, or flagging compliance with each business rule as an extra input feature.
- Use enough data for true data relationships to be distinguishable from spurious correlations. You can’t get accurate models on difficult problems using only 106 training examples. Use learning curves, which track improvements in accuracy as you add more training examples, to measure whether you have used enough training examples or need more. The only way to glean reliable insights from small data is via rigorously designed experiments.
- Don’t do big projects all at once. AIs are better suited to narrow tasks than many diverse tasks. Break up large projects into smaller, more achievable use cases. Solve one at a time, one AI per task, leaving the most difficult or time-consuming use cases until last.
- Before deploying a new AI, have its behavior reviewed and signed off by a subject matter expert. Ask them to point out any AI behavior that doesn’t make sense, especially input features that don’t seem to have a plausible mechanism for being related to the outcome.


Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
