

AI Use Case for Insurance: Part I
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about DataRobot, AI Platform, data science, and more.
This is the first in a series of articles that introduce an AI use case in the insurance industry. The series will guide you through a process of building Property Casualty (P&C) insurance pricing models using the DataRobot platform.
If you speak with an insurance expert such as an actuary, they’ll most likely refer to what we’re going to walk through as Loss Cost modeling. To understand why we have to think about losses when pricing insurance, let’s start with a quick primer on the business process underlying P&C insurance.

At a high level, insurance is a business transaction between individual policyholders and an insurance company (Figure 1). The policyholders are seeking protection from accidental losses, for example, fixing a car after a collision or paying for medical bills after a hospital visit.
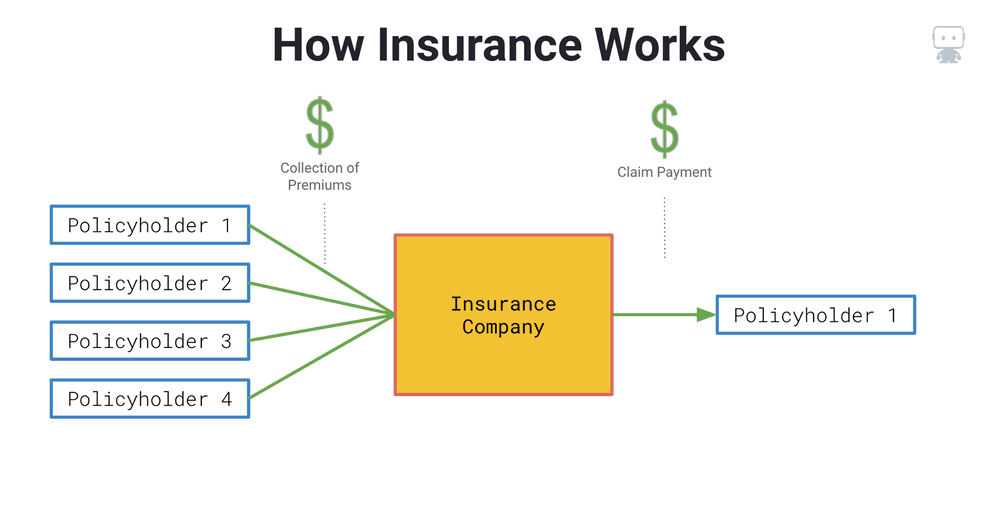
Insurance will cover these accidental losses in return for an insurance premium. Insurance premiums are collected from a large group of policyholders who are then pooled together in order to pay out future claims when any of the policyholders has an accident. When an accident occurs, the insurance payment is often much greater than the amount of premium paid by an individual policyholder. Herein lies the value of insurance: you’re not on the hook for a massive loss payment when an accident occurs; rather, you’re protected by the insurance company in exchange for paying small premium installments over time.
The next question is, how does an insurance company set the price for the insurance premiums they charge each policyholder? (Figure 2). They do so by analyzing historical loss data.
Insurers will use their historical loss experience in order to predict future claims for each individual they insure. This process of using historical loss data to predict the future is a classic example of supervised machine learning.

When building insurance pricing models, it’s very important that the model yields an accurate price for the insurance premium as well as a fair and nondiscriminatory price for everyone who wishes to purchase an insurance policy (Figure 3).

Insurers want an accurate price since it will make them more competitive. As we know, insurance is a highly competitive marketplace, which works in the favor of the policy purchaser: since everyone wants their business, they’re more likely to receive an adequate price.
But the actuaries and data scientists building these models are also responsible for ensuring their models are not biased or discriminatory towards segments of their policyholders.
Insurance regulators will scrutinize an insurer’s pricing models, oftentimes looking for discriminatory pricing based upon an individual’s level of education and their income, as well as race or gender.
This isn’t an easy task. Insurance companies need to make sure they have accurate prices so that competitors don’t gain an advantage; however, if their prices aren’t fair, regulators won’t allow them to sell policies or do business.
In order to build an insurance premium or price, insurers will utilize many characteristics to determine the expected cost of insuring each unique policyholder (Figure 4). The traditional method of building an insurance premium is conducted using rating manuals.
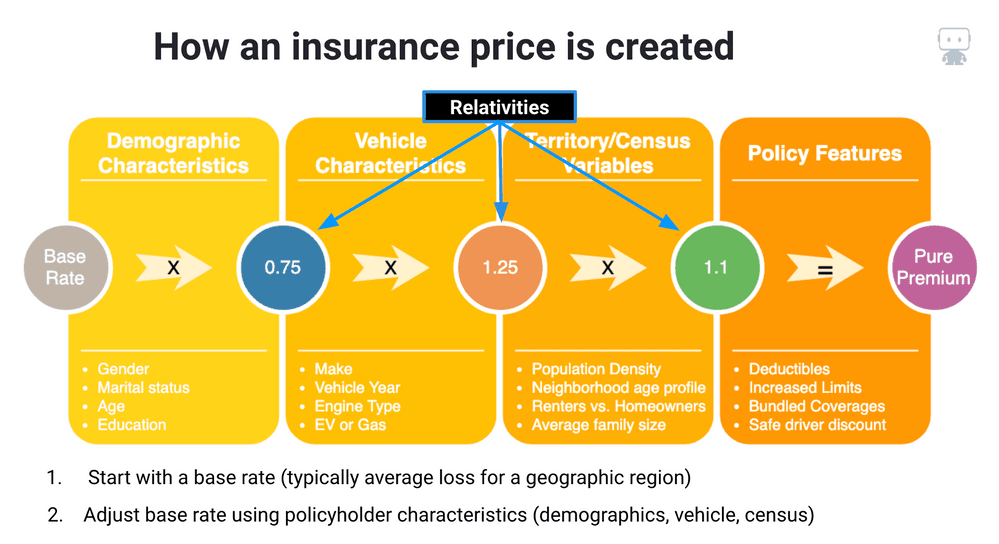
An insurer will start by looking up the average cost for each policyholder located in a particular geographic region; this is called the base rate.
Next, the insurer will look up the rating factors for each of the policyholder’s characteristics which get multiplied together to develop a final premium. These factors are referred to as relativities.
In order to properly determine the values for these relativities, we need to build a loss cost model.
Throughout this Insurance series, we’re going to show you how to do this by building models in DataRobot. In Part II of this series, we work through putting together the right data for modeling the problem.

-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
