A decade of open source at DataRobot: from predictive AI to the agent lifecycle
A decade of open source at DataRobot: from predictive AI to the agent lifecycle
Every era of DataRobot has shipped open source. The latest open-source contributions from DataRobot map directly onto where agents actually break in production.
Building an agent has never been easier. Pick a framework, wire up a model and a retriever, add a few tools, and a demo is running by lunch. The trouble starts after the demo. The workflow you guessed at turns out to be neither the most accurate option nor the cheapest one. The agent has to make a judgment call under uncertainty and has no fast way to reason about risk. And the moment more than one team starts using it, the inference bill and the latency both go sideways.
These are not framework problems. They are lifecycle problems, and they surface at three distinct stages: designing the workflow, reasoning under uncertainty at runtime, and serving the result to real users at scale.
None of this is new territory. Open source at DataRobot has never been a side quest. It has tracked the platform’s evolution stage by stage: teaching predictive AI in the open, then giving teams programmatic ownership of AutoML, and now shipping the actual infrastructure for each place agents go to production.
A decade of showing the work
The habit goes back to 2014, when the team open sourced its top-finishing code from the KDD Cup, alongside blog tutorials on gradient boosting, scikit-learn, and regression in statsmodels. The tutorials for data scientists repository, and later a run of generative AI accelerators, grew out of the same instinct: the only way to really understand AI is to build it, so hand people working code instead of a white paper. All of it sat on top of the R and Python SDKs, which is what turned a trial account into something people could script against instead of just click through.
Education answers “how do I learn this.” The next question is “how do I trust what got built,” and the answer was orchestration. The Pulumi provider and the accompanying CLI let a workflow be defined as code and rerun on someone else’s machine with the same result, turning AutoML from a black box into an exportable, auditable record. Blueprint Workshop, a Python client for constructing and editing blueprints programmatically, extended the same idea to the modeling layer itself: preprocessing, algorithms, and post-processing as code, not just as nodes in a UI.
Ownership was the logical next step after orchestration. Custom Models and Custom Tasks, built on the open-source DRUM framework, let teams bring their own pretrained models and preprocessing steps into a deployment and get monitoring, governance, and a leaderboard for free. Composable ML on top of Custom Tasks meant a blueprint could mix the platform’s own algorithms with a team’s proprietary preprocessing, without forcing a choice between the two.
The connective tissue between that era and this one is Pulumi. The same declarative pattern that once documented a predictive pipeline now provisions agent infrastructure: agent templates for CrewAI, LangGraph, and LlamaIndex ship with Pulumi wired in by default. The tools changed. The commitment to a code path instead of a walled garden didn’t.
The agent lifecycle, and where it breaks
It helps to name the stages before naming the tools. An agent moves through a predictable arc. You design the workflow that defines how it retrieves, reasons, and responds. At runtime, it has to reason about an uncertain world well enough to act. And the platform has to serve that agent to many tenants without breaking service level objectives or the budget. Each stage has a hard question attached: syftr answers the design question and Token Pool answers the serving question, both as open source releases, with more work underway on the runtime reasoning stage.
syftr: design the workflow before you guess
The first decision in any RAG or agentic build is also the one teams skip: which configuration to use. Which synthesizing LLM, which embedding model, which retriever, what chunk size, whether to add reranking, whether the flow should be agentic at all. The space runs past ten to the twenty-third unique configurations, and every choice trades accuracy against latency against cost. Most teams pick a reasonable-looking default and never find out how far it sits from the frontier.
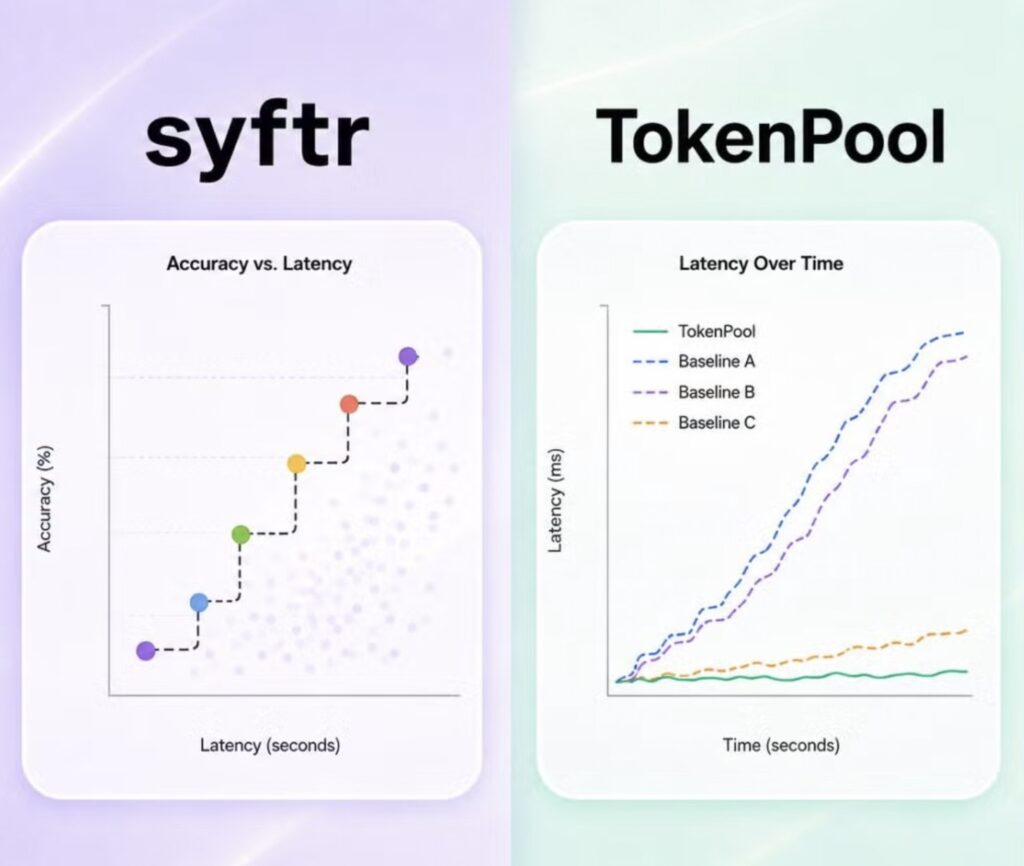
syftr searches that space instead of guessing. It uses multi-objective Bayesian optimization to find Pareto-optimal flows: the configurations where accuracy cannot improve without paying more, and cost cannot drop without losing accuracy. A domain-specific early-stopping mechanism prunes clearly suboptimal candidates before they burn through an evaluation budget, cutting search compute by 60 to 80%. On industry-standard RAG benchmarks, it identifies workflows that cut cost by up to 13 times with only marginal accuracy trade-offs.
syftr doesn’t replace judgment. It gives a data-driven way to navigate a design space too large to reason about by hand, searching across 10 proprietary and open-source LLMs, 13 embedding models, four prompt strategies, three retrievers, and four text splitters, and it produces production-ready pipeline code at the end.
pip install git+https://github.com/datarobot/syftr.gitToken Pool: serve every tenant without starving the ones that matter
A well-designed agent with sharp runtime reasoning still has to run somewhere, usually alongside everyone else’s. Multi-tenant inference hits a wall here. Dedicated endpoints strand GPU capacity on idle models. Rate limits treat every token as equal, even though one request can cost an order of magnitude more GPU time than another. Neither approach lets idle capacity be borrowed, and both fall apart under the bursts that characterize real inference traffic. The familiar result: one team’s batch job floods the endpoint, and everyone’s production latency spikes.
Token Pool fixes this at the API gateway, without touching the inference runtime underneath. It expresses capacity in inference-native units, token throughput, KV cache, and concurrency, rather than machine or pod counts. Tenants hold entitlements to a share of a pool, and service classes (dedicated, guaranteed, elastic, spot, and preemptible) set the protection ordering during contention. A debt-based fairness mechanism gives temporarily throttled workloads compensatory priority later, so no tenant is starved and none monopolizes the pool. It runs as a Kubernetes-native layer above vLLM or TensorRT-LLM.
In overload testing, Token Pool held sub-1.2 second P99 time-to-first-token for guaranteed workloads by selectively throttling spot traffic, while a baseline with no admission control degraded past 19 seconds across every workload. For anyone responsible for consumption-based economics or API governance, this is the missing primitive: capacity expressed in units that match what inference actually costs.
kubectl apply -f examples/sample-tokenpool.yaml
kubectl apply -f examples/sample-entitlement.yamlWhat’s next: closing the loop
These shipped projects operate as separate links today. Design-time search runs once. Runtime reasoning runs blind to how the serving layer is performing. The serving layer enforces policy without feeding anything back upstream. The workflow syftr found last quarter isn’t necessarily optimal against this month’s traffic, models, and prices.
The next open-source project connects production telemetry, the real cost, latency, and quality signals coming off the serving layer, back to the optimization layer, so workflows get re-evaluated against production reality instead of a single offline benchmark. It’s still in review, so it isn’t named yet, but it’s the natural fourth stage after design, reason, and serve.
Get started
- Build: install syftr with
pip install git+https://github.com/datarobot/syftr.gitand run the starter search - Build: stand up Token Pool against a local Kind cluster, no GPU required
A hands-on guide for each follows next in this series: running a first syftr search and reading the Pareto frontier, and standing up Token Pool to protect a production workload from a noisy neighbor. Start with whichever stage of the lifecycle is hurting most.

Get Started Today.