Python / R ユーザーのための Auto ML 活用法
はじめに
DataRobot で製造業のお客様を担当しているデータサイエンティストの長野将吾です。
直感的な UI で誰でも簡単に扱うことができる DataRobot ですが、実は Python や R を普段から扱うデータサイエンティストや R&D 部門の技術者の方々にもご活用いただいています。本稿では Python や R ユーザーの皆様の生産性をさらに高めるDataRobot の機能をユースケース(以下、事例)を交えながら解説します。
(注意:Python を例として説明しますが、R でも同様の操作が可能です。)
Python ユーザーのデータ分析業務に関する悩み
Python で普段データ分析をされているユーザーの皆様からデータ分析に関する以下のお悩みを頂きます。
- コードを書くことはできるが、データ分析のあらゆる処理をコーディングしたいわけではない
- コードを書くことばかりに時間が取られてしまい、ビジネスや業務そのものに割く時間が削がれてしまう
- コーディングができる人に案件が集中し、全てを捌くことができず困っている
もしコードを書きたいところや書くべきところは引き続きコーディングをし、それ以外を DataRobot に任せることができたら、皆様はもっと本来のビジネスに集中することができるでしょう。また、もし皆様が書いたコードをコーディングできない人が簡単に利用することができれば、皆様の知見は社内で共有され、一層の価値を生み出すことでしょう。
これらを実現する DataRobot の「Python SDK」と「Composable ML」をそれぞれご紹介します。
Python SDK の概要
直感的な UI が持ち味である DataRobot ですが、普段からコーディングしている皆様からみるとクリック操作が少し煩わしく感じるかもしれません。実際にこのようなお客様からは、「DataRobot に慣れるまでは GUI で操作したいが、慣れてからは Python で操作してみたい」というご要望も頂きます。これらの声にお応えするのがPython SDK です。DataRobot を Python から操作するライブラリが完備されています。通常の Python ライブラリと同様に、以下のように pip コマンドでインストールすることが可能です。
pip install datarobot
あとは、DataRobot から APIキーを取得 するだけで準備完了です。以下の手順をコードで記載してみます。
- DataRobot に学習用データの投入
- プロジェクトの作成
- ターゲットの指定
- モデリングモードの指定
- ワーカー数の指定
- 開始ボタンのクリック
まずはじめに、APIキーとエンドポイントを設定し、学習用のデータを読み込みます。
#ライブラリのimport
import pandas as pd
import datarobot as dr
# DataRobotのAPIに接続
your_token = 'APIキー'
dr.Client(token = your_token, endpoint = 'エンドポイント')
#学習データの読み込み
df_train = pd.read_csv('学習用データ.csv')次に、プロジェクトを作成します。学習用データとプロジェクト名を引数として指定しています。このコードは、DataRobot の GUI でデータ(今回は’学習用データ.csv’)をドラッグ&ドロップしたことに相当し、このコードを実行するとデータのアップロードが始まります。
#プロジェクトの作成
project = dr.Project.create(
sourcedata = df_train, #学習用データ
project_name = 'プロジェクト名'
)最後に、モデリングの条件に関する設定を行います。ここでは、ターゲット名、モデリングモードの指定、ワーカー数の指定をしました。オートパイロットモードを選択した場合、このコードを実行すると学習が開始します。
#ターゲットの設定
project.analyze_and_model(
target = 'ターゲット名',
mode = dr.AUTOPILOT_MODE.FULL_AUTO, #オートパイロットモードを選択
worker_count = 20 #使用するワーカー数を20に設定
)このように、非常にシンプルなコードで DataRobot が Python から操作できることを実感していただけたのではないでしょうか。もちろん、上記サンプルコード以外にも Python SDK を使えば DataRobot の GUI で実行可能な様々な操作が実装可能です。詳細はドキュメントをご覧ください。
Python SDK の活用事例
前章では、Python SDK の基本的なイメージをお伝えさせていただきました。この章では Python SDK の活用事例を3パターンご紹介させていただきます。
事例1:Python SDK と DataRobot で定型作業をまとめて処理する
Python SDK の威力を一番実感できるのは、同じ作業を何度も DataRobot で実行する場合であると考えます。例えば製造業ではセンサーデータ等の時系列データを様々なアイデアで加工し、その他のテーブルデータと結合することが多いのではないでしょうか?(この事例の詳細はこちら) PythonSDK を使えば、プロジェクト作成やモデリングは全部 DataRobot にまかせ、皆様は特徴量エンジニアリングやテーブル結合のアイデア等に集中することが可能です。
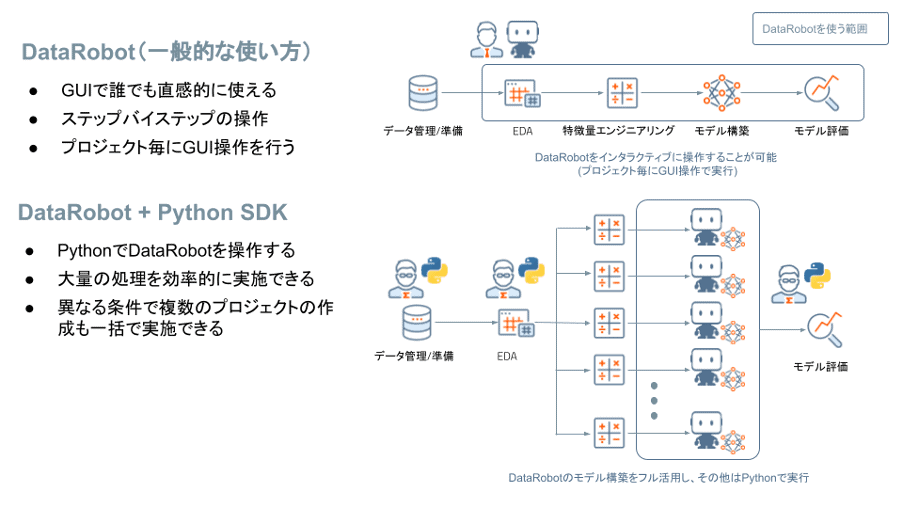
こちらの事例もサンプルコードを記載しました。先ほど解説したコードを少し書き換えるだけで、例えば30種類のプロジェクトを一気に実行することが可能です。
#ライブラリのimport
import pandas as pd
import datarobot as dr
# DataRobotのAPIに接続
your_token = 'APIキー'
dr.Client(token = your_token, endpoint = 'エンドポイント')
for i in range (30):
#データの読み込み
df_train = pd.read_csv(f'学習用データ_{i}.csv')
#プロジェクトの作成
pj_name = f'プロジェクト名_{i}'
project = dr.Project.create(
sourcedata = df_train,
project_name = pj_name
)
#ターゲットの設定
project.set_target(
target = 'ターゲット名',
mode = dr.AUTOPILOT_MODE.FULL_AUTO, #オートパイロットモードを選択
worker_count = 20 #使用するワーカー数を20に設定
)事例2:使いたい機械学習モデルを自由に選択
ビジネス要件によって既に使いたいモデルの種類がある程度決まっていることはないでしょうか? 例えば、製造業のお客様でよくある事例としては「Eureqa モデル等の数式が出力できるモデルが使いたい」等が挙げられます。その他にも、「勾配ブースティング系のモデルだけ使ってみたい」等の用途も考えられます。これらの要望も Python SDK を使うことで、使いたいモデルを細かく調整することが可能です。例えば、以下のサンプルコードでは、まずモデリングモードとしてマニュアルモードを選択することでブループリントの候補を取得しています。得られたブループリントの候補に対して簡単なテキスト処理を行うことで LightGBM、 RandomForest、 Elastic-Net を用いたブループリントのみを選択し、実行しています。
#ターゲットの設定
project.set_target(
target = 'ターゲット名',
mode = dr.AUTOPILOT_MODE.MANUAL, #マニュアルモードを選択
worker_count = 20 #使用するワーカー数を20に設定
)
bps = project.get_blueprints() #ブループリントの候補を取得
#LightgbmとRandomForestとElastic-Netだけ選択
lgb = [bp for bp in project.get_blueprints() if 'Light' in bp.model_type]
rf = [bp for bp in project.get_blueprints() if 'Random' in bp.model_type]
els = [bp for bp in project.get_blueprints() if 'Elastic' in bp.model_type]
bps = lgb + rf + els
#選択したブループリントに絞って学習
for bp in bps:
project.train(bp)事例3:スモールデータの要因分析で頑健性を確保する
要因分析の際には Permutation Importance を用いて算出した特徴量のインパクトから要因を考察することがありますが、スモールデータを扱う場合には注意が必要です。パーティションの区切り方によって Permutation Importance の結果が変動するため、特にスモールデータにおいてはパーティションの条件をランダムシードを変更しながら複数回モデリングし、解析結果の頑健性(ロバストネス)を高めることを推奨しています。この事例も定型作業の繰り返しとなるため、Python SDK を用いることで素早く結果を確認することができます(詳細はこちらのブログやウェビナーをご覧ください)。
Composable ML の概要
DataRobot には、ブループリントと呼ばれる、データ前処理、特徴量エンジニアリング、機械学習アルゴリズムの組み合わせからなる設計図が何千通りも搭載されています。DataRobotの熟練のデータサイエンスチームが日々開発しているブループリントは非常に強力で、高い精度のモデルを短時間で作ることができます。そして、このブループリントにさらに皆様の知見やアイデアを追加することができる機能がComposable MLです。
こちらが DataRobot に元から搭載されているブループリントの一例です。データが前処理や特徴量エンジニアリングを経て XGBoost(図中では、eXtreme Gradient Boosted Trees Classifier と表記)に投入されている様子が確認できます。
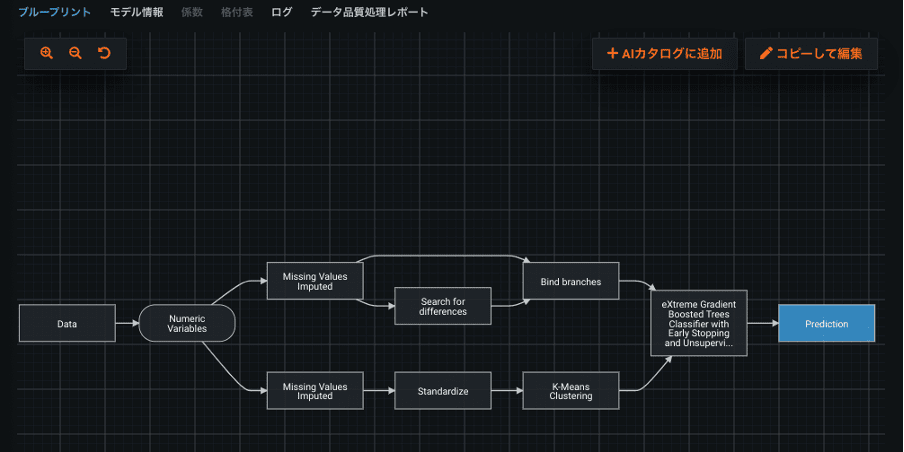
次は、このブループリントの XGBoost を、Composable ML を用いて筆者が Python でコーディングした「ロジスティック回帰」に書き換えた例です。このように、Composable ML では皆様が Python や R で書いたオリジナルの処理をブループリントに実装し、DataRobot で実行することができます。もちろん、この皆様が実装した処理は社内に共有することが可能です。Composable ML に関する詳細は、ドキュメントやオンラインコースをご参照ください。

Composable ML の活用事例
では、DataRobot のブループリントに皆様が手を加えたいケースとはどのような場合でしょうか。DataRobot は予めデータ前処理や特徴量エンジニアリングのほとんどを自動化していますが、ドメイン知識が必要な処理は実装されていません。そのため、Composable ML は皆様のドメイン知識をモデルに組み込みたい時に最も有用であると言えるでしょう。この章では Composable ML の活用事例を3パターンご紹介させていただきます。
事例1: ベースラインモデルの実装
DataRobot が作成した機械学習モデルを採用するべきか判断する場合に、これまで業務に使用していたモデルと比較したいケースがあります。例えば、簡単なルールベースのモデルや、別ツールで作成した機械学習モデルなどとの比較です。この場合、そのモデルを Python や R で書き、Composable ML を用いて DataRobot で実行することにより、DataRobot が作ったモデルとこれまで使用していたモデルをリーダーボード上で比較することができるようになります。
以下のリーダーボード例では、DataRobot が作成した3つのモデル(2種類の Elastic-Net Classifier と Light Gradient Boosted Trees Classifier)の精度が、Composable ML で実行したこれまでのモデル(ベースラインモデル)の精度よりも高いことが確認できます。同じ条件で DataRobot のリーダーボード上で比較することにより、DataRobot が作成したモデルの業務実装可否を判断しやすくなることでしょう。

事例2: ドメイン知識を活用したモデルの精度向上
先述した通り、DataRobot はドメイン知識に基づく特徴量エンジニアリングを実施しません。例えば、DataRobot は外れ値があればデータ品質評価機能を用いて警告をしてくれますが、外れ値の除去を積極的に行うことはありません。これは、本当に取り除いて良いデータなのかはドメイン知識のある皆様しか分からないためです。そのため、皆様が普段扱うデータセットに十分詳しく、外れ値を除去しても問題ないと考えるのであれば、このドメイン知識を DataRobot のブループリントに反映することが可能です。例えば、数値データの±3 σの範囲外のデータを欠損値に置き換える処理は外れ値が多いデータセットでは有効な場合が多いです。他にも、SMILES という分子の化学構造を踏まえた前処理を Composable ML で実装することにより、予測精度が向上した事例があります。詳細はこちらをご参照ください。
事例3: 途中のデータ処理結果を出力し、モデルを更に理解する
機械学習モデルがブラックボックス化されていると人はモデルを理解・解釈することができず、業務適用しづらくなります。DataRobot ではこのブラックボックス化を避けるため、Permutation Importance、Partial Dependance、SHAP 等の豊富なアルゴリズムの実装により説明可能なAI を実現しています。さらに、Composable ML を用いることでブループリントの途中の処理結果を CSV ファイルとして出力することが可能となり、モデルの解釈性をさらに高めることができるようになります。
例えば、One-Hot Encoding の処理結果を取り出したい場合は、下記のように CSV ファイルとして簡単に取り出すことができます。
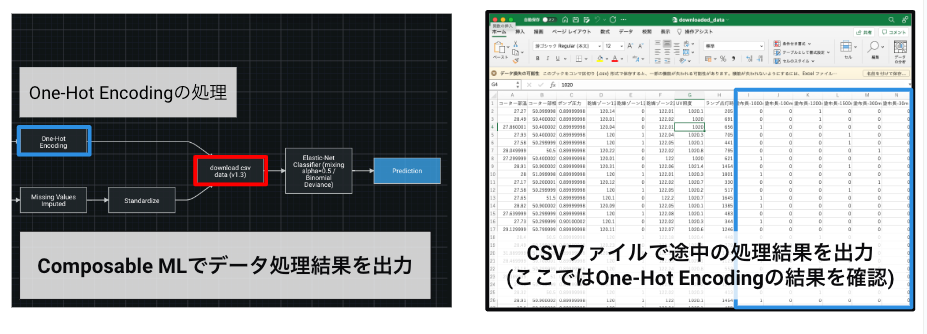
あるいは、学習器の直前までのデータ処理結果を CSV ファイルとして取り出せば、手元のローカル環境でデータ処理結果を学習させることが可能です。先ほどの事例2では、DataRobot 上で Python や R で実装したベースラインモデルを評価していましたが、このようにローカルの環境でモデルを評価することも可能です。この方法は、Python や R 以外のツールと DataRobot を同じ条件で比較したい場合にも有効です。
まとめ
本稿では、Python ユーザーの皆様に DataRobot をさらに活用していただけるように「Python SDK」及び「Composable ML」の機能を事例を交えながら解説しました。もちろん、R ユーザーの皆様も「R SDK」を用いることで同様のことが実行できます。皆様の機械学習プロジェクトの生産性向上の一助になれば幸いです。
参考
- DataRobot Python package documentation (Python SDK のドキュメント)
- ‘DataRobot’ Predictive Modeling API (R SDK のドキュメント)
- DataRobot Docs – Composable ML
- DataRobot Features – Composable ML