What are parametric models?
This article was originally published at Algorithimia’s website. The company was acquired by DataRobot in 2021. This article may not be entirely up-to-date or refer to products and offerings no longer in existence.
In machine learning, a parametric model is any model that captures all the information about its predictions within a finite set of parameters. Sometimes the model must be trained to select its parameters, as in the case of neural networks. Sometimes the parameters are selected by hand or through a simple calculation process. Given the multiple definitions of the word “model,” a parametric model can output either a probability or a value (in some cases a classification).
The vast majority of machine learning models one deals with on a practical basis are parametric, because relying on non-parametric models generally adds an assumption of too much simplicity in the underlying data.
Examples of parametric models
The following are five different examples of parametric models: exponential distributions, poisson distributions, normal distributions, the Weibull distribution, and linear regressions.
An exponential distribution is given by the function
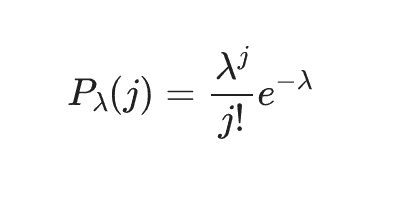
Exponential distributions are useful in the modeling of the time to failure of equipment, where the rate of failure is constant and the mean time to failure is the inverse of λ.
A poisson distribution is given by the function
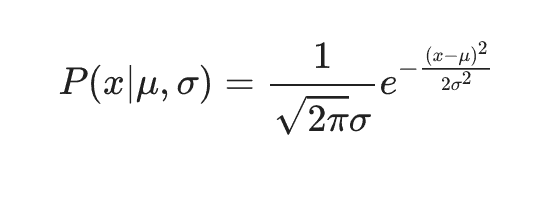
The poisson distribution models the probability of an event occurring in a fixed amount of time or space when it is known to occur at a constant fixed rate λ (the parameter), and each event is independent.
The normal distribution is an example of a model with multiple parameters. It is given by
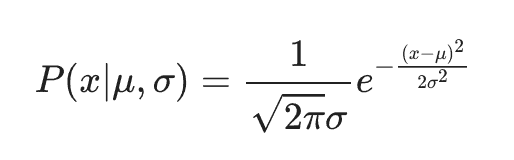
The parameter μ represents the mean of the data while the parameter σ represents the standard deviation of the data. σ is an example of a parameter with a restricted value range – it can only be positive. The normal distribution can be thought of as the simplest or smoothest distribution with a given mean and variance.
The two-parameter Weibull distribution is a parametric model useful in the modeling of the probability distribution of time to failure for equipment, and is a generalization of the exponential distribution. The distribution is given by
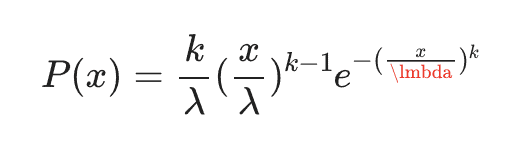
for x≥0 and P(x)=0 for x<0. λ, the scale parameter, and k, the shape parameter are both restricted to be a positive.
Finally, we have linear regression. Linear regression models are given by
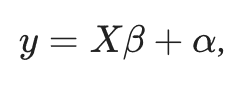
where X is a matrix and the parameters β and α are vectors. β and α are chosen so as to minimize the sum of the squares of the residuals from the linear regression line to the actual input data points. The assumption is that the statistics of the residuals are such that they are normally distributed around the linear regression line.
Parameter estimation
There are many methods of parameter estimation, or choosing parameters, in parametric modeling. One such method is maximum likelihood estimation, which yields the most likely parameter values given an input training data set. For instance, in Weibull distributions, the maximum likelihood value for the scale parameter λ is given by the average of the input data points raised to the power k, the shape parameter.
In other parametric models, it is very difficult or awkward to do maximum likelihood estimation and a process of model training is required. In neural networks, the process of back propagation is applied to training data in order to decide on the values of the weights that constitute the model parameters. It is critical in the design of machine learning models to know how difficult the process of parameter estimation will be. Finding the mean and standard deviation for a normal distribution model is not terribly difficult, while training a neural network can be fraught with risk and very computationally expensive.
As an example of a practical, business application of parametric modeling, consider the Weibull distribution. The Weibull model is widely used in the space industry to obtain statistics on the reliability of equipment when only a small number of reliability data points are available. Given perhaps 10 or 20 data points of failure times for a device, which is often all that is available for the kinds of custom and expensive equipment used in the space industry, one can predict the probabilities of failure for shorter times than were ever observed, critical for space equipment that often must work for years continuously in environments where repair and maintenance can be expensive, risky, or impossible.
Non-parametric models
The design of most machine learning models is such that they have a small number of parameters to eliminate the need for inefficient parameter searches, so that whether a model is parametric or non-parametric is usually a minor characteristic relative to the total large number of characteristics of a given machine learning model. However, in some cases, as with neural networks, there can be a large number of parameters and the process of choosing them can be expensive, time-consuming and fraught with risk. In general non-parametric models like the standard normal distribution and the exponential distribution e−x are simpler to handle and reduce complexity, but are not able to adequately handle many data modeling problems.
Get Started Today.