The brewing GenAI data science revolution
If you lead an enterprise data science team or a quantitative research unit today, you likely feel like you are living in two parallel universes.
In one universe, you have the “GenAI” explosion. Chatbots now write code and create art, and boardrooms are obsessed with how large language models (LLMs) will change the world. In the other universe, you have your day job: the “serious” work of predicting churn, forecasting demand, and detecting fraud using structured, tabular data.
For years, these two universes have felt completely separate. You might even feel that the GenAI hype rocketship has left your core business data standing on the platform.
But that separation is an illusion, and it is disappearing fast.
From chatbots to forecasts: GenAI arrives at tabular and time-series modeling
Whether you are a skeptic or a true believer, you have most certainly interacted with a transformer model to draft an email or a diffusion model to generate an image. But while the world was focused on text and pixels, the same underlying architectures have been quietly learning a different language: the language of numbers, time, and tabular patterns.
Take for instance SAP-RPT-1 and LaTable. The first uses a transformer architecture, and the second is a diffusion model; both are used for tabular data prediction.
We are witnessing the emergence of data science foundation models.
These are not just incremental improvements to the predictive models you know. They represent a paradigm shift. Just as LLMs can “zero-shot” a translation task they weren’t explicitly trained for, these new models can look at a sequence of data, for example, sales figures or server logs, and generate forecasts without the traditional, labor-intensive training pipeline.
The pace of innovation here is staggering. By our count, since the beginning of 2025 alone, we have seen at least 14 major releases of foundation models specifically designed for tabular and time-series data. This includes impressive work from the teams behind Chronos-2, TiRex, Moirai-2, TabPFN-2.5, and TempoPFN (using SDEs for data generation), to name just a few frontier models.
Models have become model-producing factories
Traditionally, machine learning models were treated as static artifacts: trained once on historical data and then deployed to produce predictions.
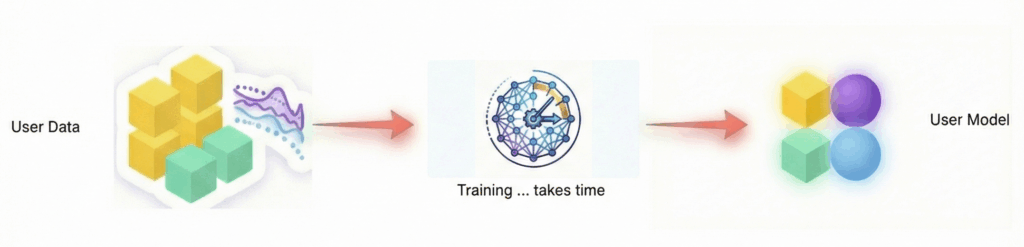
That framing no longer holds. Increasingly, modern models behave less like predictors and more like model-generating systems, capable of producing new, situation-specific representations on demand.
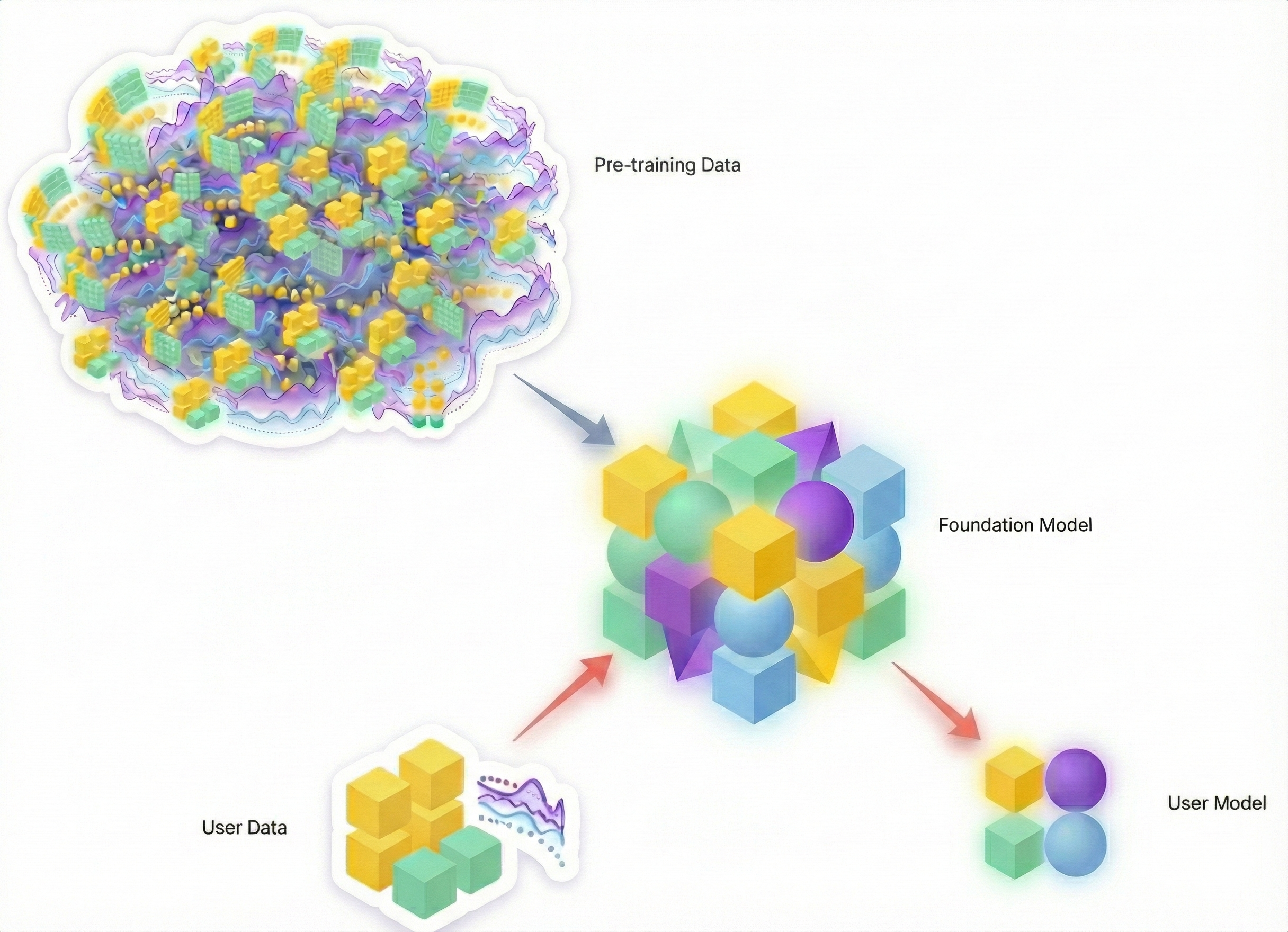
We are moving toward a future where you won’t just ask a model for a single point prediction; you will ask a foundation model to generate a bespoke statistical representation—effectively a mini-model—tailored to the specific situation at hand.
The revolution isn’t coming; it’s already brewing in the research labs. The question now is: why isn’t it in your production pipeline yet?
The reality check: hallucinations and trend lines
If you’ve scrolled through the endless examples of grotesque LLM hallucinations online, including lawyers citing fake cases and chatbots inventing historical events, the thought of that chaotic energy infiltrating your pristine corporate forecasts is enough to keep you awake at night.
Your concerns are entirely justified.
Classical machine learning is the conservative choice for now
While the new wave of data science foundation models (our collective term for tabular and time-series foundation models) is promising, it is still very much in the early days.
Yes, model providers can currently claim top positions on academic benchmarks: all top-performing models on the time-series forecasting leaderboard GIFT-Eval and the tabular data leaderboard TabArena are now foundation models or agentic wrappers of foundation models. But in practice? The reality is that some of these “top-notch” models currently struggle to identify even the most basic trend lines in raw data.
They can handle complexity, but sometimes trip over the basics that a simple regression would nail it–check out the honest ablation studies in the TabPFN v2 paper, for instance.
Why we remain confident: the case for foundation models
While these models still face early limitations, there are compelling reasons to believe in their long-term potential. We have already discussed their ability to react instantly to user input, a core requirement for any system operating in the age of agentic AI. More fundamentally, they can draw on a practically limitless reservoir of prior information.
Think about it: who has a better chance at solving a complex prediction problem?
- Option A: A classical model that knows your data, but only your data. It starts from zero every time, blind to the rest of the world.
- Option B: A foundation model that has been trained on a mind-boggling number of relevant problems across industries, decades, and modalities—often augmented by vast amounts of synthetic data—and is then exposed to your specific situation.
Classical machine learning models (like XGBoost or ARIMA) do not suffer from the “hallucinations” of early-stage GenAI, but they also do not come with a “helping prior.” They cannot transfer wisdom from one domain to another.
The bet we are making, and the bet the industry is moving toward, is that eventually, the model with the “world’s experience” (the prior) will outperform the model that is learning in isolation.
The missing link: solving for reality, not leaderboards
Data science foundation models have a shot at becoming the next massive shift in AI. But for that to happen, we need to move the goalposts. Right now, what researchers are building and what businesses actually need remains disconnected.
Leading tech companies and academic labs are currently locked in an arms race for numerical precision, laser-focused on topping prediction leaderboards just in time for the next major AI conference. Meanwhile, they are paying relatively little attention to solving complex, real-world problems, which, ironically, pose the toughest scientific challenges.
The blind spot: interconnected complexity
Here is the crux of the problem: none of the current top-tier foundation models are designed to predict the joint probability distributions of several dependent targets.
That sounds technical, but the business implication is massive. In the real world, variables rarely move in isolation.
- City Planning: You cannot predict traffic flow on Main Street without understanding how it impacts (and is impacted by) the flow on 5th Avenue.
- Supply Chain: Demand for Product A often cannibalizes demand for Product B.
- Finance: Take portfolio risk. To understand true market exposure, a portfolio manager doesn’t simply calculate the worst-case scenario for every instrument in isolation. Instead, they run joint simulations. You cannot just sum up individual risks; you need a model that understands how assets move together.
The world is a messy, tangled web of dependencies. Current foundation models tend to treat it like a series of isolated textbook problems. Until these models can grasp that complexity, outputting a model that captures how variables dance together, they won’t replace existing solutions.
So, for the moment, your manual workflows are safe. But mistaking this temporary gap for a permanent safety net could be a grave mistake.
Today’s deep learning limits are tomorrow’s solved engineering problems
The missing pieces, such as modeling complex joint distributions, are not impossible laws of physics; they are simply the next engineering hurdles on the roadmap.
If the speed of 2025 has taught us anything, it is that “impossible” engineering hurdles have a habit of vanishing overnight. The moment these specific issues are addressed, the capability curve won’t just inch upward. It will spike.
Conclusion: the tipping point is closer than it appears
Despite the current gaps, the trajectory is clear and the clock is ticking. The wall between “predictive” and “generative” AI is actively crumbling.
We are rapidly moving toward a future where we don’t just train models on historical data; we consult foundation models that possess the “priors” of a thousand industries. We are heading toward a unified data science landscape where the output isn’t just a number, but a bespoke, sophisticated model generated on the fly.
The revolution is not waiting for perfection. It is iterating toward it at breakneck speed. The leaders who recognize this shift and begin treating GenAI as a serious tool for structured data before a perfect model reaches the market will be the ones who define the next decade of data science. The rest will be playing catch-up in a game that has already changed.
We are actively researching these frontiers at DataRobot to bridge the gap between generative capabilities and predictive precision. This is just the start of the conversation. Stay tuned—we look forward to sharing our insights and progress with you soon.
In the meantime, you can learn more about DataRobot and explore the platform with a free trial.
Get Started Today.