Automating Model Risk Compliance: Model Development
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning
It has been over a decade since the Federal Reserve Board (FRB) and the Office of the Comptroller of the Currency (OCC) published its seminal guidance focused on Model Risk Management (SR 11-7 & OCC Bulletin 2011-12, respectively). The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States. In response, these institutions have invested heavily in both processes and key talent to ensure that models used to assist critical business decisions are compliant with regulatory mandates.
Since SR 11-7 was initially published in 2011, many groundbreaking algorithmic advances have made adopting sophisticated machine learning models not only more accessible, but also more pervasive within the financial services industry. No longer is the modeler only limited to using linear models; they may now make use of varied data sources (both structured and unstructured) to build significantly higher performing models to power business processes. While this provides the opportunity to greatly improve the institution’s operating performance across different business functions, the additional model complexity comes at the cost of greatly increased model risk that the institution has to manage.
Given this context, how can financial institutions reap the benefits of modern machine learning approaches, while still being compliant to their MRM framework? As referenced in our introductory post by Diego Oppenheimer on Model Risk Management, the three critical components of managing model risk as prescribed by SR 11-7 include:
- Model Development, Implementation and Use
- Model Validation
- Model Governance, Policies, and Controls
In this post, we will dive deeper into the first component of managing model risk, and look at opportunities at how automation provided by DataRobot brings about efficiencies in the development and implementation of models.
Developing Robust Machine Learning Models within a MRM Framework
If we are to stay compliant while making use of machine learning techniques, we must demand that the models we build are both technically correct in their methodology and also utilized within the appropriate business context. This is confirmed by SR 11-7, which asserts that model risk arises from the “adverse consequences from decisions based on incorrect or misused model outputs and reports.” With this definition of model risk, how do we ensure the models we build are technically correct?
The first step would be to make sure that the data used at the beginning of the model development process is thoroughly vetted, so that it is appropriate for the use case at hand. To reference SR 11-7:
The data and other information used to develop a model are of critical importance; there should be rigorous assessment of data quality and relevance, and appropriate documentation.
This requirement makes sure that no faulty data variables are being used to design a model, so erroneous results are not outputted. The question still remains, how does the modeler ensure this?
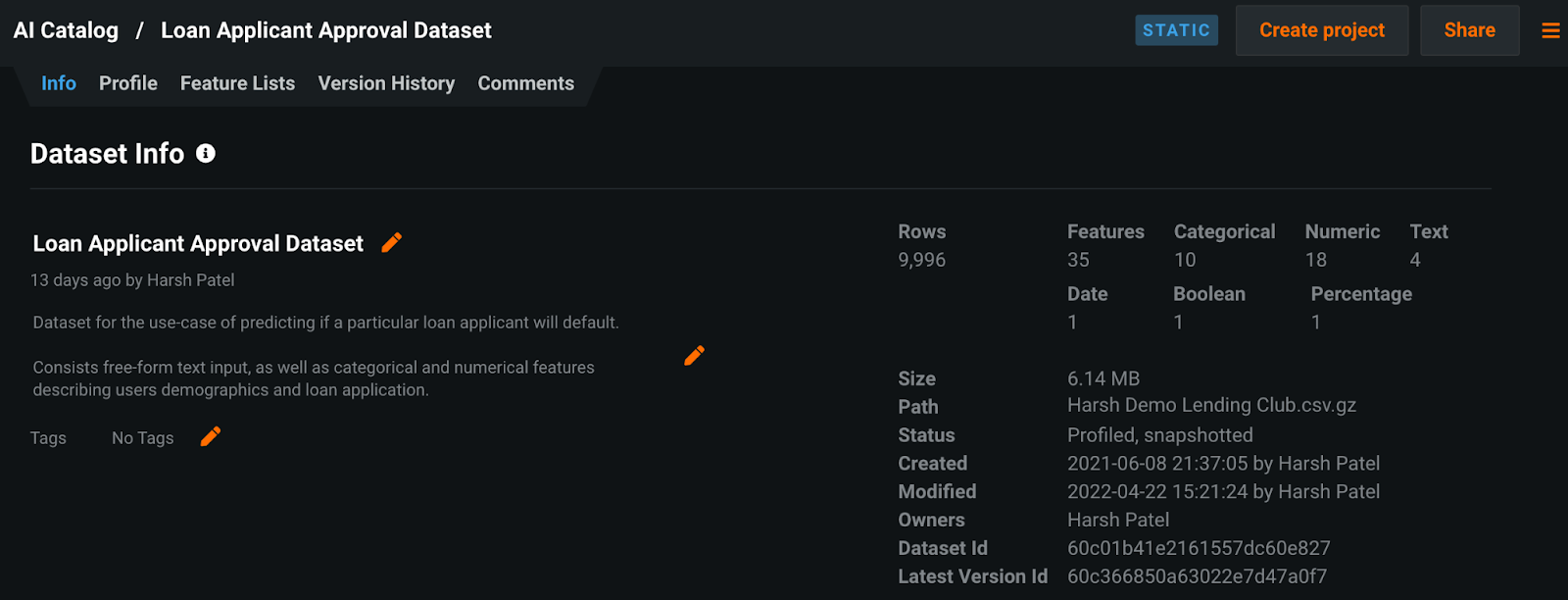
Firstly, they must make sure that their work is readily reproducible and can be easily validated by their peers. Through DataRobot’s AI Catalog, the modeler is able to register datasets that will subsequently be used to build a model and annotate it with the appropriate metadata that describes the datasets’ function, origin, as well as intended use. Additionally, the AI Catalog will automatically profile the input dataset, providing the modeler a bird’s eye overview of both the content of the data and its origins. If the developer subsequently pulls a more recent version of the dataset from a database, they are able to register it and keep track of the different versions.
The benefit of the AI Catalog is that it helps to foster reproducibility between developers and validators and ensures that no datasets are unaccounted for during the model development lifecycle.
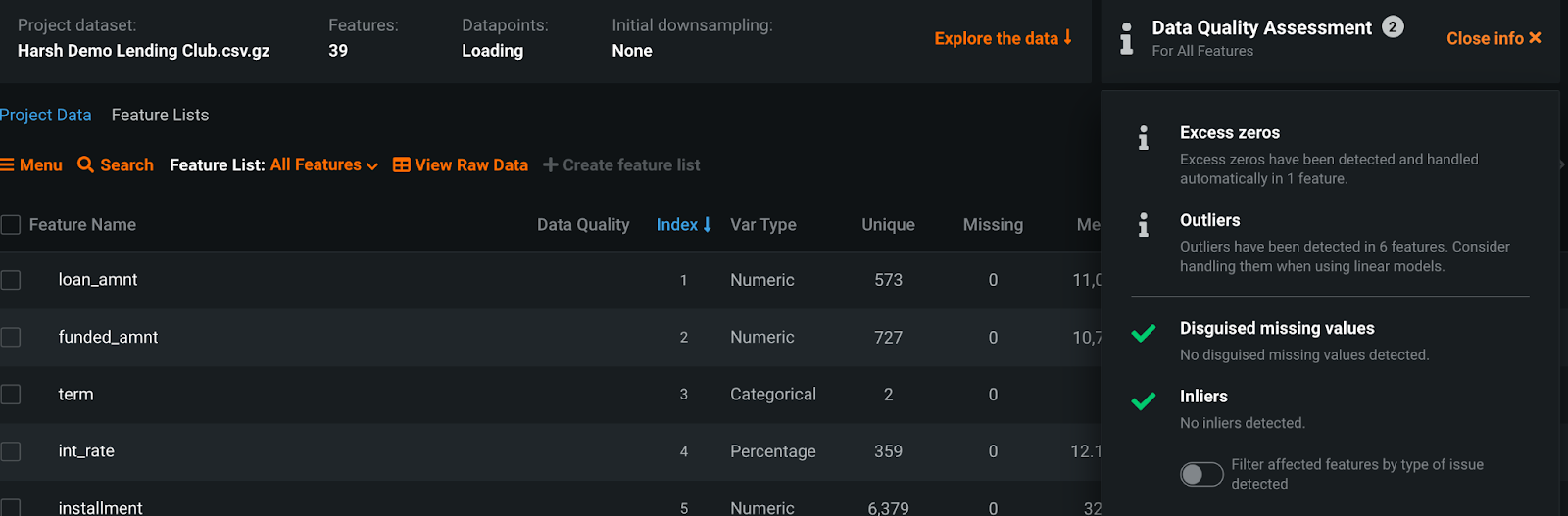
Secondly, the modeler must ensure that the data is free from any potential quality issues that may adversely impact model results. At the start of a modeling project, DataRobot automatically performs a rigorous data quality assessment, which checks for and surfaces common data quality issues. These checks include:
- Detecting cases of redundant and non-informative data variables and removing them
- Identifying potentially disguised missing values
- Flagging both outliers and inliers to the user
- Highlighting potential target leakage in variables
For a detailed description of all the data quality checks DataRobot performs, please refer to the Data Quality Assessment documentation. The benefit of adding automation in these checks is that it not only catches sources of data errors the modeler may have missed, but it also enables them to quickly shift their attention and focus on problematic input data variables that require further preparation.
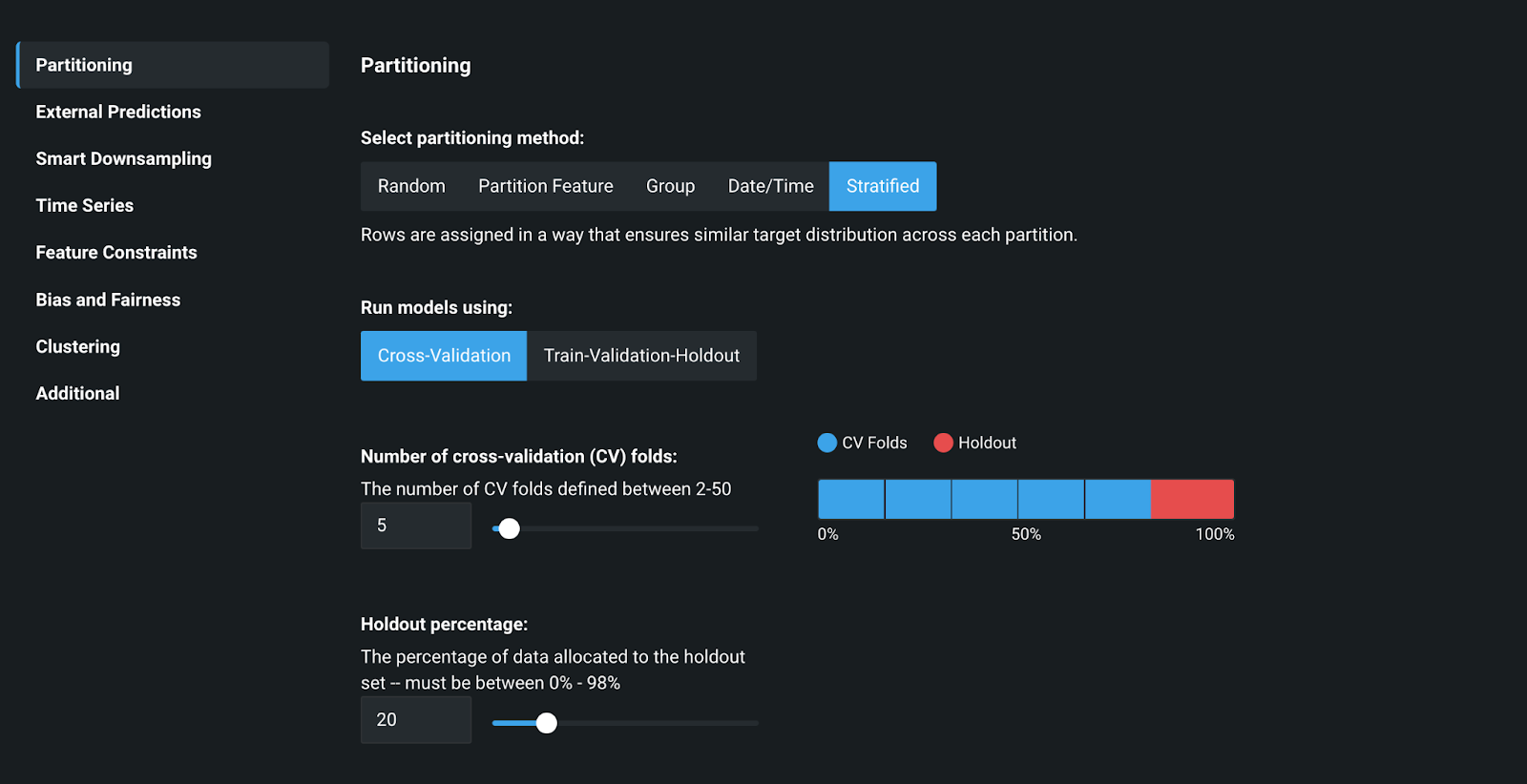
Once we have the data in place, the modeler must then ensure they design their modeling methodologies in a manner that is supported by concrete reasoning and backed by research. The importance of model design is further reinforced by the guidance articulated in SR 11-7:
The design, theory, and logic underlying the model should be well documented and generally supported by published research and sound industry practice.
In the context of building machine learning models, the modeler has to make multiple decisions with regards to partitioning their data, setting feature constraints, and selecting the appropriate optimization metrics. These decisions are all required to ensure they don’t produce a model that overfits existing data, and generalizes well to new inputs. Out of the box, DataRobot AI Platform provides intelligent presets based upon the inputted dataset and offers flexibility to the modeler to further customize the settings for their specific needs. For a detailed description of the all design methodologies provided, please refer to the Advanced Options documentation.
Lastly, while designing a proper model methodology is a critical and necessary prerequisite for building technically sound solutions, it is not sufficient by itself to comply with the guidance provided in MRM frameworks. To elaborate, when approaching business problems using machine learning, modelers may not always know what combination of data, feature preprocessing techniques, and algorithms will yield the best results for the problem at hand. While the modeler may have a favorite modeling approach, it is not always guaranteed that it will yield the optimal solution. This sentiment is also captured in the guidance provided by SR 11-7:
Comparison with alternative theories and approaches is a fundamental component of a sound modeling process.
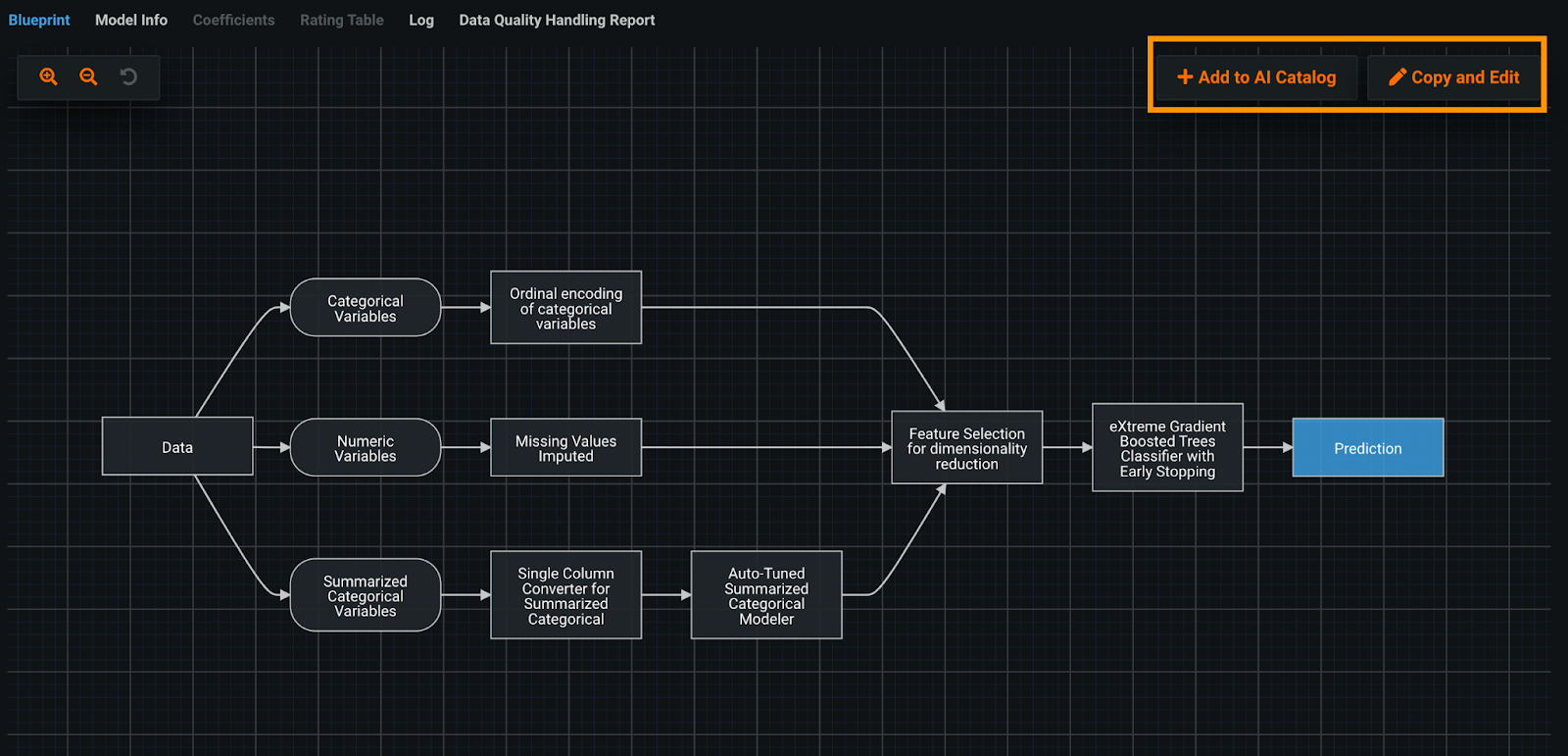
A major challenge that this provides the modeler is that they have to spend large amounts of time developing additional model pipelines and experiment with different models and data processing techniques to see what will work best for their particular application. When kicking off a new project in DataRobot, the modeler is able to automate this process, and simultaneously try out multiple different modeling approaches to compare and contrast their performance. These different approaches are captured in DataRobot’s Model Leaderboard, which highlights the different Blueprints, and their performance against the input dataset.
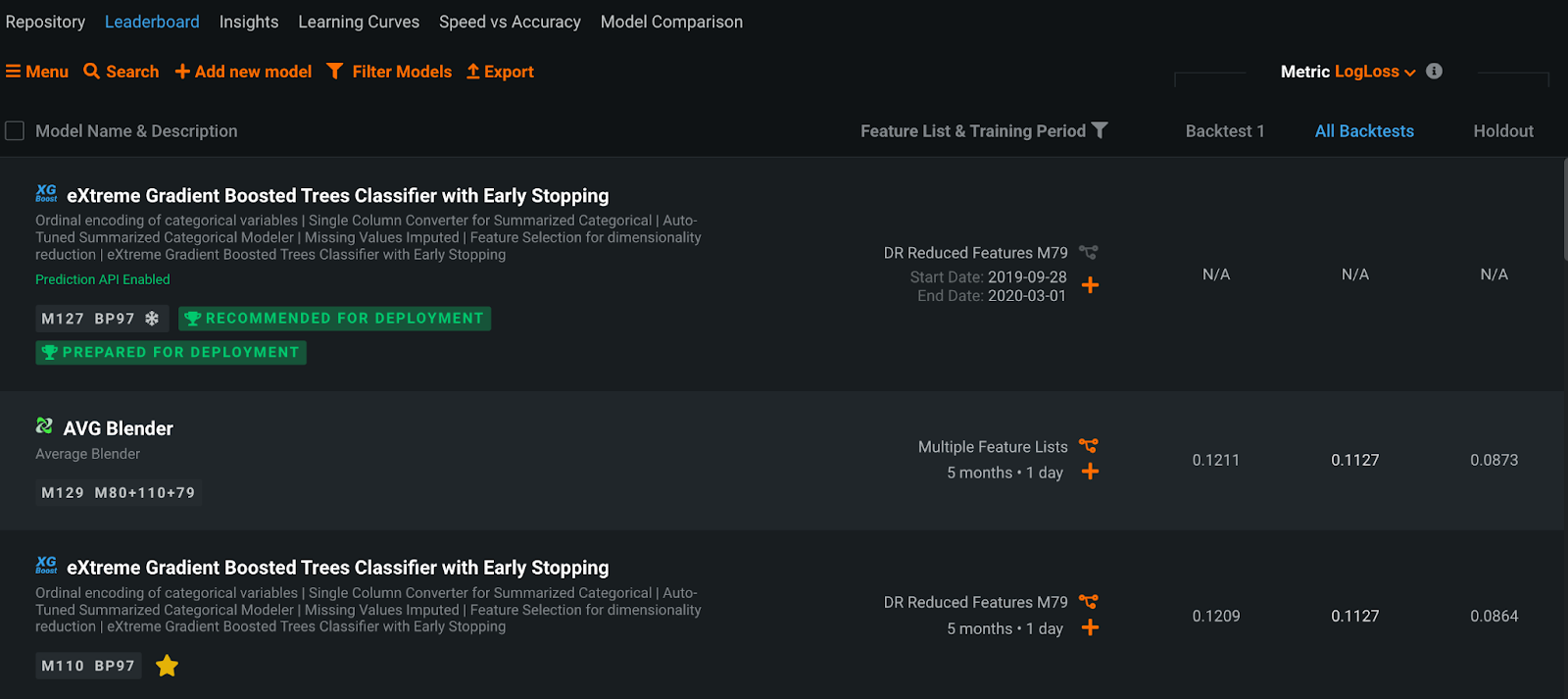
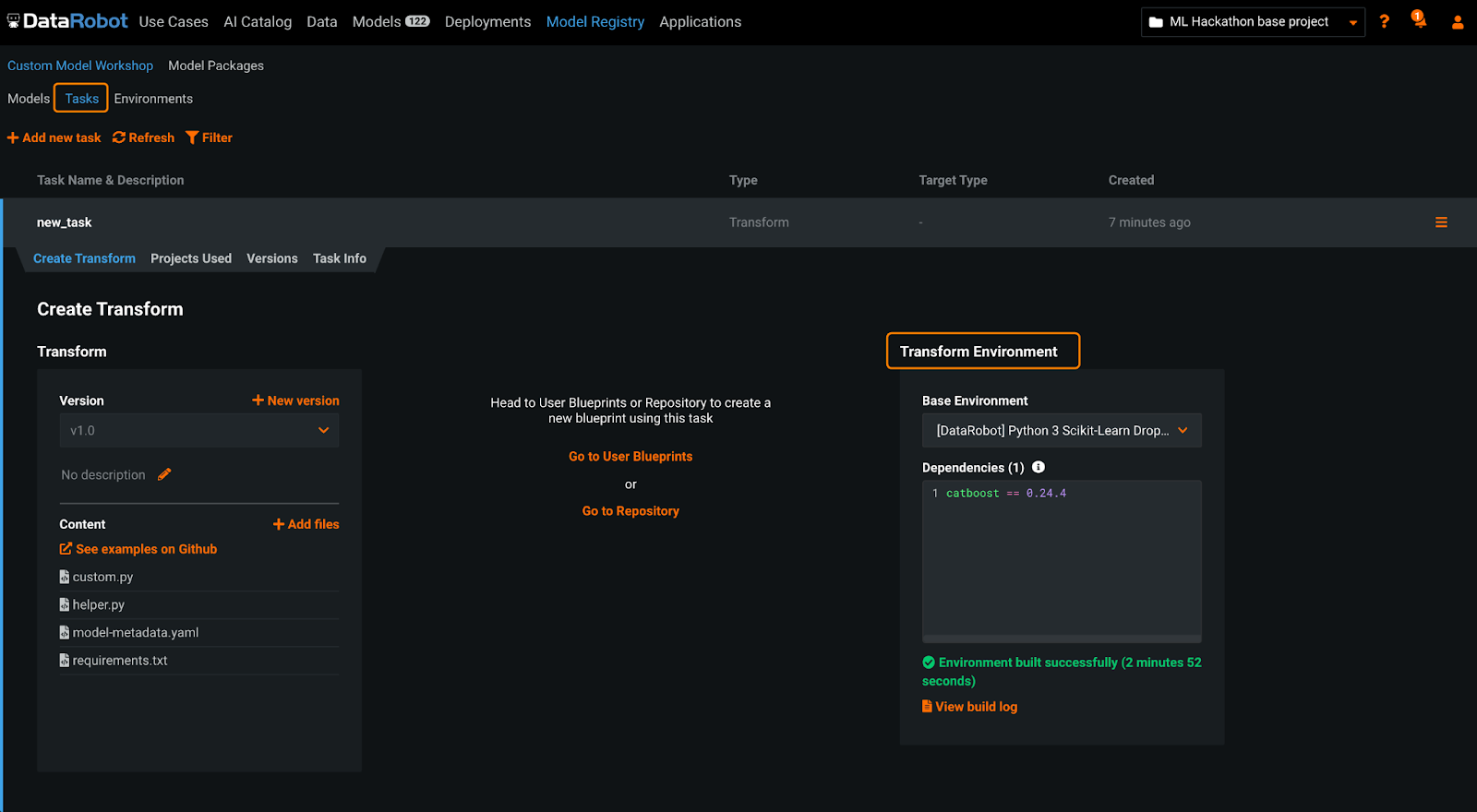
In addition to automatically creating multiple machine learning pipelines, DataRobot provides the modeler additional flexibility through Composable ML to directly modify the blueprint, so they may further experiment and customize their model to satisfy business needs. If they desire to bring in their own code to customize specific components of the model, they are empowered to do so through Custom Tasks — enabling the developer to inject their own domain expertise to the problem at hand.
Conclusion
Algorithmic advances in the past decade have provided modelers with a wider variety of sophisticated models to deploy in an enterprise setting. These newer machine learning models have created novel model risk that needs to be managed by financial institutions. Using DataRobot’s automated and continuous machine learning platform, modelers can not only build cutting edge models for their business applications, but also have tools at their disposal to automate many of the laborious steps as mandated in their MRM framework. These automations enable the data scientist to focus on business impact and deliver more value across the organization, all while being compliant.
In our next post, we will continue to dive deeper into the various components of managing model risk and discuss both the best practices for model validation and how DataRobot is able to accelerate the process.



Get Started Today.