機械学習を使った出店計画(1)
DataRobotのデータサイエンティストの中山晴之です。
最近、小売・流通業界や外食産業において、機械学習を使って課題を解決しようとする動きが見られるようになりました。そして、その動きをDataRobotが加速しています。DataRobotの登場により、これまで敷居の高かった機械学習やAIがグッと身近なものになったためです。このブログでは、特に新店の売上予測を題材に取り上げ、機械学習を使って新店の売上予測をする上でのポイントを解説していこうと思います。
小売・流通業界や外食業界で、売上を拡大するためには、店舗数を増やす必要があります。しかし、出店した店舗が赤字では業績に悪影響を及ぼします。しかも、退店となると、これまでの投資が無駄になるだけでなく、退店費用や違約金の支払いなど、多額の損失が発生します。すべてを合計すると一店当たり数千万円になるでしょう。
このような事態を極力避けるためには、新店の候補地ひとつひとつ、そこで期待される売上を正確に予測する必要があります。従来は、新規店舗開発などの専門部署で、その道のベテランと呼ばれる人が経験と勘で判断してきました。しかし、すべての新店候補地を見て回る余裕はなく、また、正確性という点でも限界が見られました。そこで、重回帰を使用して売上を予測するところが増えてきましたが、満足できる結果が得られていないというのが実情ではないでしょうか。
そこで、重回帰の代わりに機械学習を使用して予測の精度を向上させようとする動きが見られるようになり、実際に成果を上げているところが出始めています。出店の失敗を一店舗減らすだけでも数千万円のロスを防ぐことができるので、その効果は絶大です。
しかし、ただ単に機械学習を使えば満足できるような予測精度が得られるわけではありません。予測の精度を上げるためには、いろいろと注意すべきポイントがあります。そうしたポイントを、これから幾つかのブログに分けて、お話したいと思います。その第1回はデータについてです。
機械学習のプロセス
機械学習を使って新店の売上予測を行う場合、その手順は、下図のようになります。

「モデル」というのは、既存店に関するデータから、「どういう要因がどういうふうにどのくらい売上に影響するか」ということを学習した結果です。その学習結果であるモデルに新店候補地のデータを与えると、「既存店はこうだったから、この新店候補地ではこのぐらいの売上が期待できるだろう」と予測するわけです。
この予測の精度を上げるためには、どのようなデータを使うかがとても重要です。モデルを作るために使用する既存店のデータに、売上に影響を与える因子が含まれていなかったり、含まれていても正確な値でなかったり、あるいは、古い値であったりすると、精度の高い予測ができないだろうということは容易に想像できると思います。
データソース
新店の売上予測に使用する主なデータソースを表1に示します。
特に重要なデータを太字にしました。まずは、この太字のデータを使ってモデルを作り、徐々にデータを増やしていけば良いでしょう。また、後述するGISには「社外(公共団体)」に分類したデータがほとんどすべて収録されていますので、まだGISをお持ちでない場合は、その購入を検討されることをお勧めします。
| 分類 | データ名 | 調査周期 | 粒度 | 主な内容 |
| 社内 | POS | |||
| 店舗マスタ |
|
|||
| 社外(公共団体) | 国勢調査 | 5年 | 125mメッシュ |
|
| 人口推計 | 1年 | 都道府県 | ||
| 日本の地域別将来推計人口 | 1年 | 市区町村 | ||
| 住民基本台帳人口移動報告 | 1ヶ月 | 都道府県、大都市 | ||
| 住宅・土地統計調査 | 5年 | 都道府県、大都市 |
|
|
| 家計調査 | 1ヶ月 | 県庁所在地、主要都市 |
|
|
| 家計消費状況調査 | 1ヶ月 | 地方、都市階級 | ||
| 全国消費実態調査 | 5年 | 都道府県 | ||
| 小売物価統計調査(動向編) | 1ヶ月 | 県庁所在地、主要都市 | ||
| 小売物価統計調査(構造編) | 1年 | 都道府県 | ||
| 消費者物価指数(CPI) | 1ヶ月 | 県庁所在地 | ||
| 労働力調査 | 4半期 | 地方 | ||
| 就業構造基本調査 | 5年 | 都道府県 | ||
| 経済センサス | 5年 | 125mメッシュ |
|
|
| 個人企業経済調査 | 1ヶ月 | |||
| サービス産業動向調査 | 1ヶ月 | 全国 | ||
| 商業統計 | 5年 | 500mメッシュ |
|
|
| 賃金構造基本統計調査(賃金センサス) | 1年 | 都道府県 | ||
| 国家公務員給与等実態調査 | 1年 | 全国 | ||
| 全国道路・街路交通情勢調査(交通センサス) | 5年 | 主要地方道 |
|
|
| 自動車保有台数 | 1年 | 都道府県 |
|
|
| 都道府県地価調査 | 1年 | 都道府県 | ||
| 社外(公共団体以外) | 地価 | |||
| 駅乗降客数 | ||||
| 競合出店状況 | ||||
| 大型小売店総覧 | ||||
| 日本スーパー名鑑 | ||||
| SC別基礎データ一覧 | ||||
| ホームセンター名鑑 | ||||
| 現地調査 | 店舗周辺概況 |
|
||
| 店前通行量 |
|
|||
| 店前交通量 |
|
|||
| 店前道路の状況 |
|
大きく、以下の4つに分類できます。
- 社内のデータ
- 社外の主に公共団体から無償で入手できるデータ
- 社外の第3社から購入するデータ
- 現地調査を中心として、自社でコストをかけて収集するデータ
まず、社内のデータとしては、POSデータや店舗マスタがあります。POSデータを使う上で注意しなければならないことは、「POSデータをすべて機械学習の学習用データとして使ってはいけない」ということです。予測をするときに不明なデータを学習用データとして使用してはいけません。例えば、客層ボタンを押して記録される客層データは新店に関しては不明なので使用してはいけません。また、店舗マスタがきちんとメンテナンスされておらず、改装やリブランディングの情報が反映されていない場合があるので、注意が必要です。
新店の候補地の周辺に関するデータとしては、国勢調査などのように、公共団体(一般社団法人もこちらに含めています)が無償で公開しているデータと、競合情報などのように、第3社から購入しなければならない情報とがあります。
公共団体が公開しているデータは、表1からも分かる通り、その「細かさ」がバラバラです。すなわち、調査・公開される周期や調査セグメントがバラバラです。5年ごとに調査・公開されるデータは、調査年が異なっていたりします。また、交通センサスのように、その収集方法から、「新店の売上予測には使えない」データもあるので、これも注意が必要です。(交通センサスは、秋の平日の午前7時〜午後7時までの交通量データのみです。平日と休日、天気によって、交通量は大きく変わりますので、交通センサスのデータだけに頼るのはとても危険です。)それから、最近はAPIが準備されているデータも増えてきましたが、ファイルで入手して整形してからでないと使えないデータも多く、しかも、メッシュデータの場合はCDを購入しなければ入手できない場合もありますので、取得コストはゼロではないことにも注意して下さい。
競合情報などは第3社から購入する必要がありますが、こうした第3社が提供するのは「現時点のデータ」のみで、「過去のデータ」は提供されないことが多いことに注意して下さい。例えば、既存店の数年前の売上を学習用データとして使用する場合には、その時点の競合店の数が分からないため、現在の競合店数から類推する必要があります。こうしたことを避けるために、これから第3社のサービスを契約しようとしている場合には、購入・取得したデータをきちんとデータベース等に保存する仕組みを合わせて構築することを推奨します。
社外から入手できないデータは自ら集める必要があります。そして、こうしたデータが、新店の売上予測ではとても重要です。別のブログで説明しますが、特に現地調査は重要です。現地調査の結果をいかに学習データに織り込むかが機械学習による新店の売上予測の精度を大きく左右します。ただし、現地調査にはコストがかかります。新店の候補地だけでなく、既存店に対しても定期的に実施する必要があります。もし仮に一店舗あたり10万円のコストがかかるとなると、500店舗で5,000万円かかることになります。そのため、現地調査で何を調査するか、既存店に対してはどのくらいの頻度で実施するか、に関しては、データの重要度と取得コストの観点から判断しなければなりません。
商圏
上記のデータソースから収集したデータのうち、関心があるのは、新店の候補地や既存店の「周辺」のデータです。この「周辺」、すなわち、その店舗のお客様の発生源(住んでいたり、働いていたり、立ち寄ったりするところ)となり得る範囲を商圏と呼びます。
駐車場の無いビルインタイプでは、徒歩で来店するお客様がほとんどですので、円商圏を使います。駐車場の有るロードサイドタイプでは、車で来店するお客様がほとんどですので、ドライブ商圏を使います。表2に示すように、円商圏は距離で、ドライブ商圏は走行時間で指定するのが普通で、それぞれ一般的に使用される値は、コンビニやファミレスなどの業態によって異なります。ドライブ商圏は、従来は、一般道は平均時速20km、幹線道路は平均時速30kmというように、平均時速を決めて距離を計算していましたが、最近は、渋滞や信号の有無を考慮して距離を計算するGIS(後述)も出てきています。
| 円商圏 | ドライブ商圏 | |
 |
 |
|
| 対象となる店舗タイプ | ビルイン | ロードサイド |
| お客様の来店手段 | 徒歩 | 車 |
| 範囲の指定方法 | 距離 | 自動車による走行時間 |
| 特徴 | 道路に関する情報(道路のどちら側にあるか、接道は幹線道路か、近くに信号は有るか、など)は一切無視する | 道路に沿って伸びるアメーバ状で、特に幹線道路に沿って長く伸びる |
| コンビニでの一般的な値 | 500m〜1km | 5分〜10分 |
| ファミレスでの一般的な値 | 1km〜3km | 10分〜30分 |
いずれの商圏の場合でも、店舗からの距離が遠くなればなるほどその店舗の利用率は低くなります。それを近似的に表現するために、1次商圏/2次商圏というように複数の商圏に分割するのが一般的です。例えば、下図のように、店舗周辺に一定の人口密度で人が居住している地域において、店舗利用率がシグモイド曲線(オレンジ色の線)を描いて減衰すると仮定すると、見込み客数は赤線のようになります。そこで、円商圏500mを1次商圏、円商圏1kmを2次商圏として設定します。このとき、2次商圏は、1次商圏との重なりを除いたドーナツ状として設定するのが一般的です。

※人口に関しては、100mごとにドーナツ状の領域を設定した場合の例です。
また、特に円商圏の場合は、途中で、川が流れていたり、踏切や高架の無い鉄道が走っていたりしますと、人の流れがそこで途切れますので、商圏がそれ以上伸びなくなり、形が正円になりません。これを商圏分断と呼びます。(ドライブ商圏の場合も同様のことが考えられますが、こちらの場合は、それが走行時間に反映されますので、特に意識する必要はありません。)
なお、現時点では、本当の商圏の形をご存じのところは無いでしょう。すなわち、本当にお客様がどこから来ているのか分かっていないと思います。円商圏にしろ、ドライブ商圏にしろ、「仮」に設定した商圏に過ぎません。真の商圏の姿を知ることが、機械学習による新店の売上予測の精度を大きく改善する鍵になりますので、データサイエンティストは、現在のデータでベストを尽くす一方で、真の商圏の形を把握する手段を検討すべきでしょう。近年ようやく、スマホおよびスマホを利用した決済が普及しつつありますので、それが実現できる日は近づいていると言えます。(目的来店が増えるような商品が開発されれば、商圏という概念が必要なくなり、出店が楽になりますので、それが本来目指すべき姿かもしれませんが。)
GIS
店舗を中心とした円商圏500mのデータを取り出そうとすると、公共団体が提供しているデータの中では125mメッシュデータや500mメッシュデータしか使えないことに気付きます。その他のデータは、何らかの形で、このメッシュにマッピングしなくてはなりません。また、125mメッシュや500mメッシュは、必ずしも店舗の位置に都合良く切られているわけではありません。こうして考えてみると、データ準備や前処理に膨大な時間がかかることが分かります。円商圏はまだしも、ドライブ商圏に至っては途方に暮れてしまいます。
それを解決するのがGISです。GISでは、こうしたデータ準備や前処理が既に済んでおり、新店の候補地や既存店の位置を指定して、商圏の種類(円商圏かドライブ商圏か)や範囲(距離や走行時間)を指定するだけで、その商圏内のデータを表示したりダウンロードしたりすることができます。
よく「どのGISがお勧めですか?」と聞かれます。実際、ドライブ商圏の形などは、GISによって大きく異なります。都道府県単位の粗い粒度のデータをメッシュにマッピングする手法も異なります。どれが良いのでしょうか。私の答えは「混在して使わなければ、どのGISを使っても構いません。」です。なぜなら、前述のように、円商圏にしろドライブ商圏にしろ、あくまでも「仮」の姿だからです。真の姿は誰にも分かりません。円商圏で指定する「500m」やドライブ商圏で指定する「5分」などにも、何の根拠もありません。だいたいこのぐらいだろう、ということで区切りの良い数字を使っているに過ぎません。したがって、大事なことは「同じ条件でデータを収集すること」です。そのため、もし、同じGISを使い続けていても、GISの仕様が変わって、ドライブ商圏の形が変わってしまったら、データをすべて取り直す必要があることに注意して下さい。敢えてお勧めするとすれば「APIでデータを取得できるGIS」ですが、まだまだ費用が高い印象があります。
データ選択とDataRobot
GISを使って、データを収集すると、一つのことに気づくと思います。それは、行数に比べて列数が非常に多いことです。これが、新店の売上予測のデータの大きな特徴です。私がかつて機械学習を使って新店の売上予測を実施した際には、列数(特徴量の数)は2,000近くまで膨れ上がりました。しかも、これは行数(店舗数)には全く依存しません。店舗数が100程度しかなくても、売上に影響する可能性のある因子(特徴量)の数は、やはり2,000ぐらいはあるのです。
これまで重回帰で新店の売上予測を実施されてきた方は、「こんなにたくさんの特徴量をそのまま使っても良いのだろうか?」「10ぐらいまで絞り込まないといけないんじゃないだろうか?」と不安に思うでしょう。でもDataRobotは大丈夫です。DataRobotにはすべての特徴量をそのまま入力して構いません。
DataRobotは、こうした大量の特徴量をきちんと処理するだけでなく、
- どういう特徴量が売上に影響を与えているのか
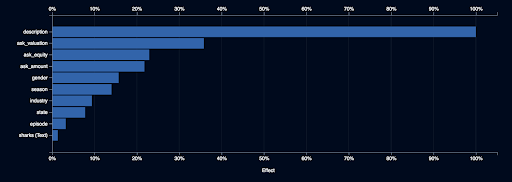
- 上記の特徴量は、どういうふうに売上に影響を与えるのか
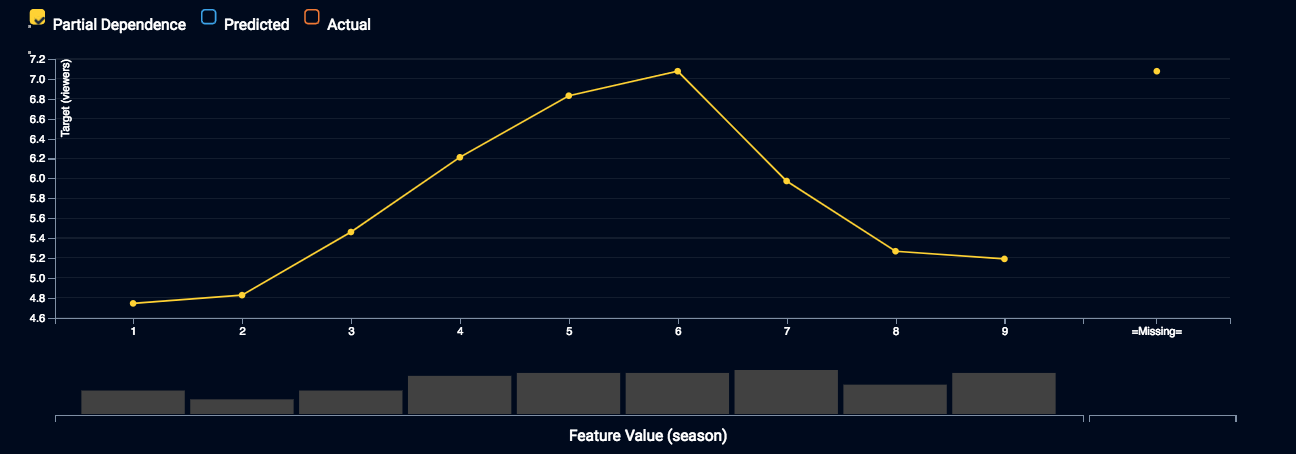
を示してくれます。 しかも、こうした機能が、すべてのアルゴリズムに対して用意されています。「ディープラーニングはブラックボックスなので、どうしてこういう結果が出てきたのか、分かりません」というようなことはDataRobotでは起こりません。
この説明性の良さは、以下の2つの点で非常に有効です。
- 上層部は、予測の精度よりも、何が効いてくるのか、に関心があることが多い
新店の売上予測を機械学習で行う場合、もちろん、予測の精度は重要です。しかし、他の人、特に上層部の関心は、予測の精度よりも「いったい、何が売上に効いてくるのか」にあることの方が多いのが実情です。 - 待ちの出店から攻めの出店に変えることができる
これまでは、不動産業者から紹介される非常に多くの物件の中から、売上が高くなりそうな物件を選択してきました。しかし、もし、売上に効く因子を高い精度で見つけることができれば、売上が高くなりそうな地域が分かりますので、その地域で候補地を探すように不動産業者に指示することができるようになります。こうした方が、良い候補地が見つかる確率は高く、精査する物件数も格段に少なくなることでしょう。
まとめ
機械学習では、社内のデータ、社外のデータ、現地調査で収集したデータなど、大量のデータを使用します。そうしたデータソースから、新店の候補地や既存店の商圏内のデータを抽出します。その作業は非常に多くの工数が必要となりますので、GISを使用するのが一般的です。こうして集められたデータは、行数に比べて列数(特徴量の数)が非常に多いのが特徴です。DataRobotを使えば、この非常に多い特徴量を、そのまま使うことができます。予め、データ選択をする必要はありません。しかも、どの特徴量がどのように売上に効いてくるかが分かりますので、上層部に説明したり、新店の候補地を効率よく見つけたりすることができます。
なお、予測の精度を上げるためには、「特徴量エンジニアリング」と呼ばれる、データの加工が重要です。新店の売上予測でも、新店の売上予測ならではの特徴量エンジニアリングがあるのですが、それに関しては、またの機会と致します。