DataRobotとNebius


本格的なエージェント体制を運用するために特別に設計された、実績のあるAIプラットフォーム。

インフラ構築ではなく、エージェント開発に
Nebius AI Cloud、NVIDIAのアクセラレーテッド・コンピューティング、およびDataRobot エージェントワークフォースプラットフォームに事前に統合されています。独自のインフラ構築も、統合プロセスも不要です。あるのは、本番運用への最短ルートだけ。
安定した性能、予測可能な価格体系、ノイジーネイバーの回避
Nebius AI Cloudの専用インフラ上で、自律型AIのワークロードを常時稼働。予測可能なパフォーマンス、低レイテンシー、そしてコストの透明性を実現します。

全てのエージェントを制御し、全てのポリシーを例外なく適用。
DataRobotは、データの所在を問わずあらゆるソースに接続。Nebius上での構築から本番運用に至るまで、すべてのエージェントを統合管理します。移行の摩擦をなくし、データの主権を守り抜き、ガバナンスの死角を排除します。
GPUクラスターから本番環境で稼働するエージェントに至るまで、検証済みのAI基盤を構築しました。
DataRobotとNebiusは、エンタープライズ向けのエージェント専用に設計された、検証済みの「AI ファクトリー」を提供します。AI専用のGPUインフラと、フルスタックの追跡可能性およびガードレールを備えた本番仕様のプラットフォームを融合させ、自律型AIの実戦投入を実現します。
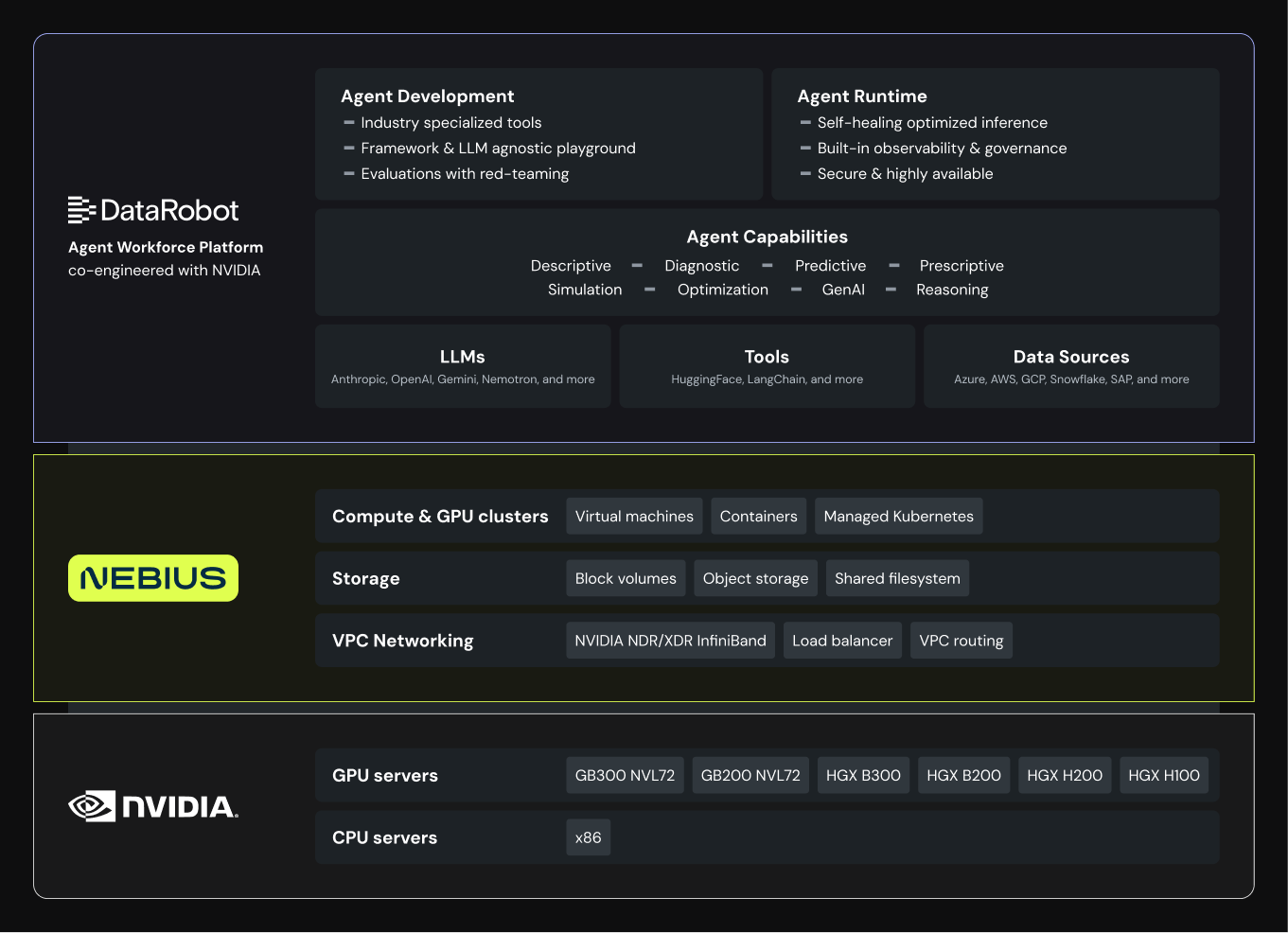
DataRobotとNebiusは、エンタープライズ向けのエージェント専用に設計された、検証済みの「AI ファクトリー」を提供します。AI専用のGPUインフラと、フルスタックの追跡可能性およびガードレールを備えた本番仕様のプラットフォームを融合させ、自律型AIの実戦投入を実現します。
GPUの運用と確保に奔走するのは、もうやめにしましょう。今こそ、エージェントを実戦へ。
ビジネスを変革するエージェントを構築し、全社規模で展開する。GPUの順番待ちや、共有クラウドの制約に縛られる必要はもうありません。
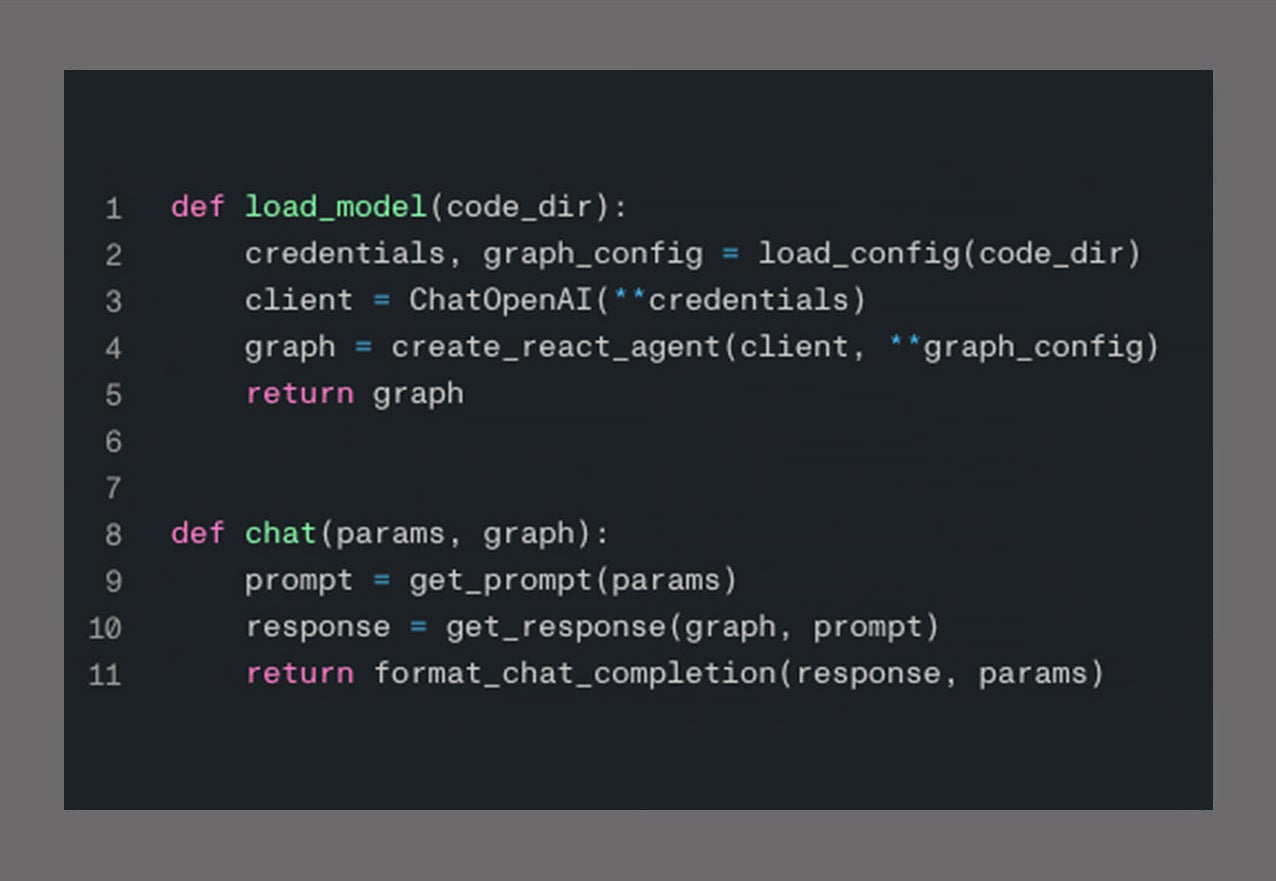
- 専用GPUキャパシティを基盤に、80種類以上のモデルを選べるLLMゲートウェイと事前構築済みのエージェントテンプレートを活用。特定の領域に特化した専門エージェントを迅速に提供し、リソースの奪い合いを回避。
- ワンクリックでエージェントをデプロイ。組み込みのマルチテナント機能とトークン制御により、リソースを奪い合うことなく、複数のチームでインフラを効率的に共有可能。
- サプライチェーンからエネルギー、ライフサイエンスまで。部門を超えた「エージェントワークフォース」を、全社規模で展開。
確実なパフォーマンス。透明性の高いコスト。想定外の事態をゼロに。
専用GPUリソースにより、安定したパフォーマンスと予測可能なコストを実現します。また、DataRobotのトークン割当管理機能により、作業の遅延を招くことなく、すべてのチームが予算内に収まるよう管理されます。
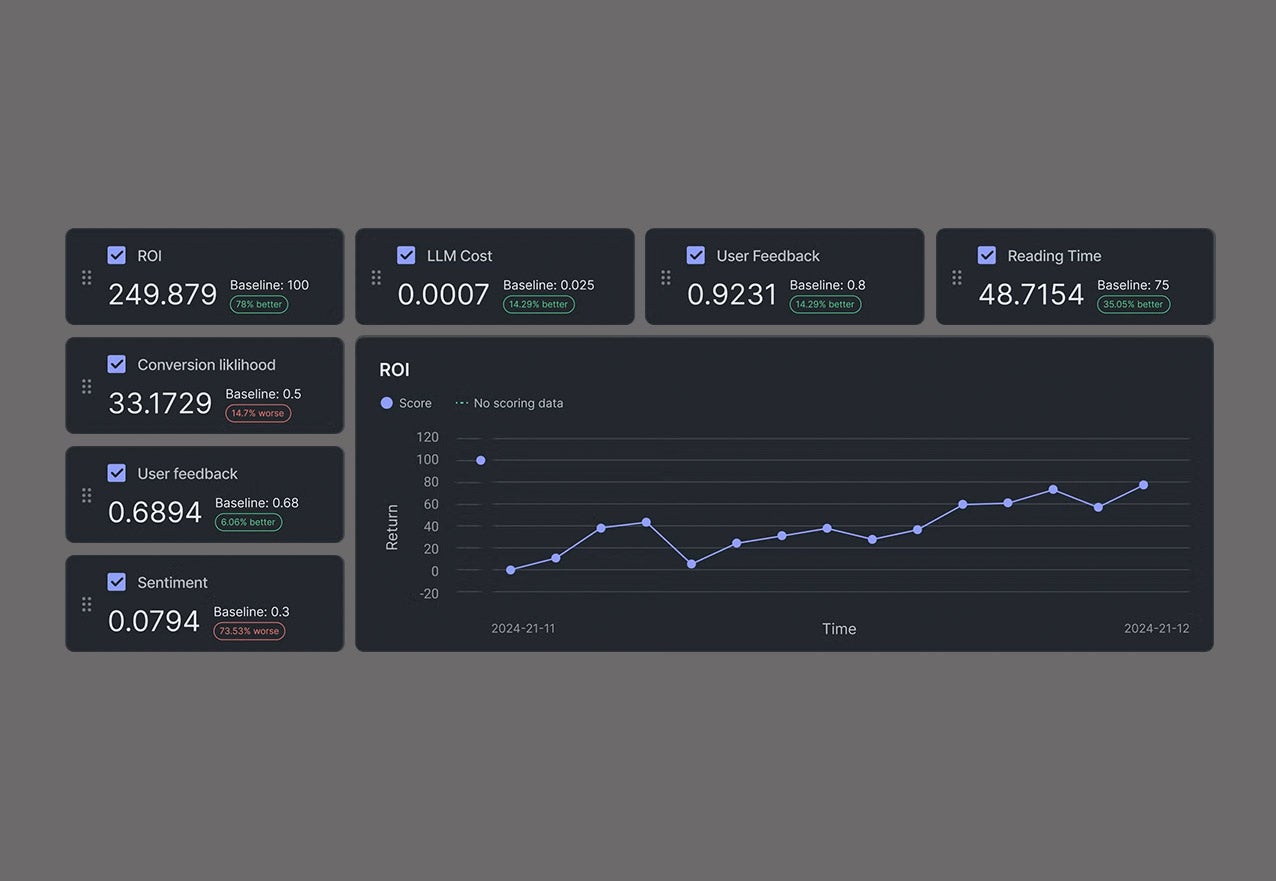
- Nebiusの予約済み価格とDataRobotのトークン割当管理により、無駄のない投資を実現。
- 専用GPUキャパシティでエージェントを稼働させ、パフォーマンスの変動を排除。自己修復型推論が、高負荷下でも揺るぎない信頼性を維持。
- Nebiusのマルチテナント機能と、各エージェントを管理対象の範囲内に収めるDataRobotの組み込み制御機能を活用し、チーム間でGPUインフラを効率的に共有可能。
一度の構築で、あらゆる場所で動作し、すべてを統治する。
データは、今ある場所から動かす必要はありません。エージェントは、経済的およびパフォーマンスの面で最も理にかなった場所で動作し、どこへ展開しても、ガバナンスは途切れません。
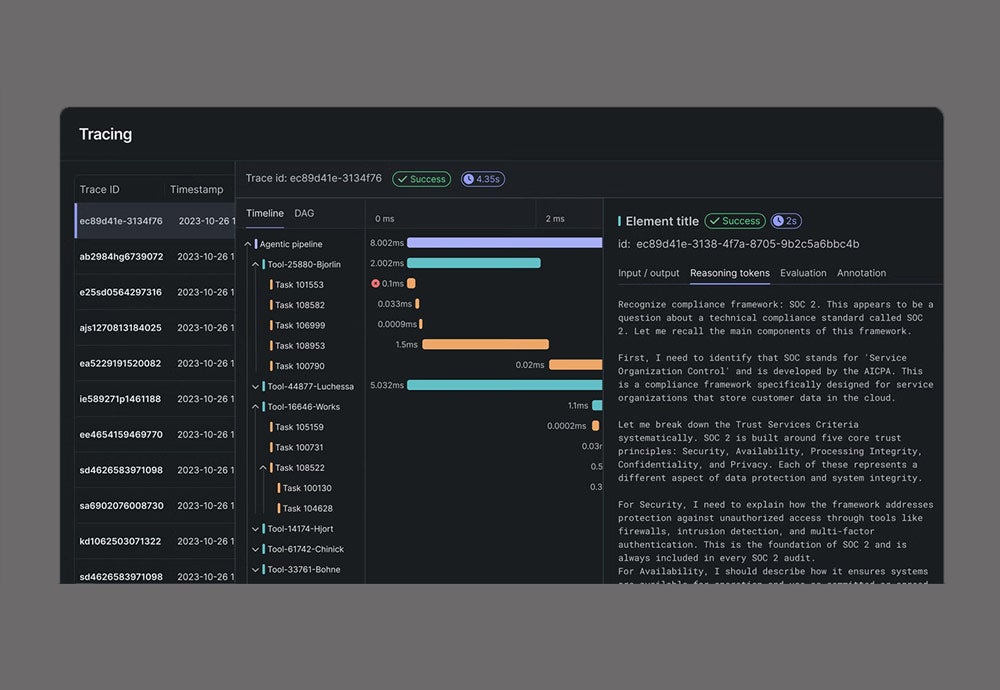
- Nebius AI CloudにDataRobotエージェントを展開し、他のクラウド上のデータに接続します。強制的なデータ移行も、レジデンシーの妥協も、一切不要。
- DataRobotの統合オブザーバビリティ・ダッシュボードから、すべてのエージェントを監視し、あらゆるトークン利用を追跡。全社規模のAI労働力に対して、ガバナンス・ポリシーを確実に適用。
- OpenTelemetry(OTel)準拠のモニタリングとトレースを採用。稼働ステータス、リソース利用率、トークン使用枠をリアルタイムに追跡。
- エージェントを書き換えることなく、クラウド間やオンプレミス環境間でワークロードを移行可能。DataRobotは、必要な場所ならどこでも動作します。
検証済みのAIスタック。あらゆるレイヤーのエージェント向けに特別に設計されています。
次世代のエージェントワークフォースの推進に向けた連携

「エージェントが継続的に稼働している場合、パフォーマンスのばらつきや予測不可能なコストが運用リスクをもたらします。」「DataRobotとの提携およびNVIDIAのAI基盤を活用することで、Nebius AI Cloud上で検証済みの導入環境を提供しています。この環境では、安定したレイテンシー、予測可能な価格設定、そしてエージェントのワークロードを継続的に処理するために必要なパフォーマンスを実現しています。」