AI 人材も揃い、GPU も揃いました。
課題は、エージェント型AIをエンタープライズレベルで機能させることです。
DataRobot にお任せください。
成果を上げるために設計された 唯一のエージェントワークフォースプラットフォームなら終わりのないPoCはもう必要ありません
複雑なエンタープライズ環境を統合することを意図して設計されています
基盤エージェント
特化型エージェント
DataRobotなら、エージェントを
デモで終わらせません
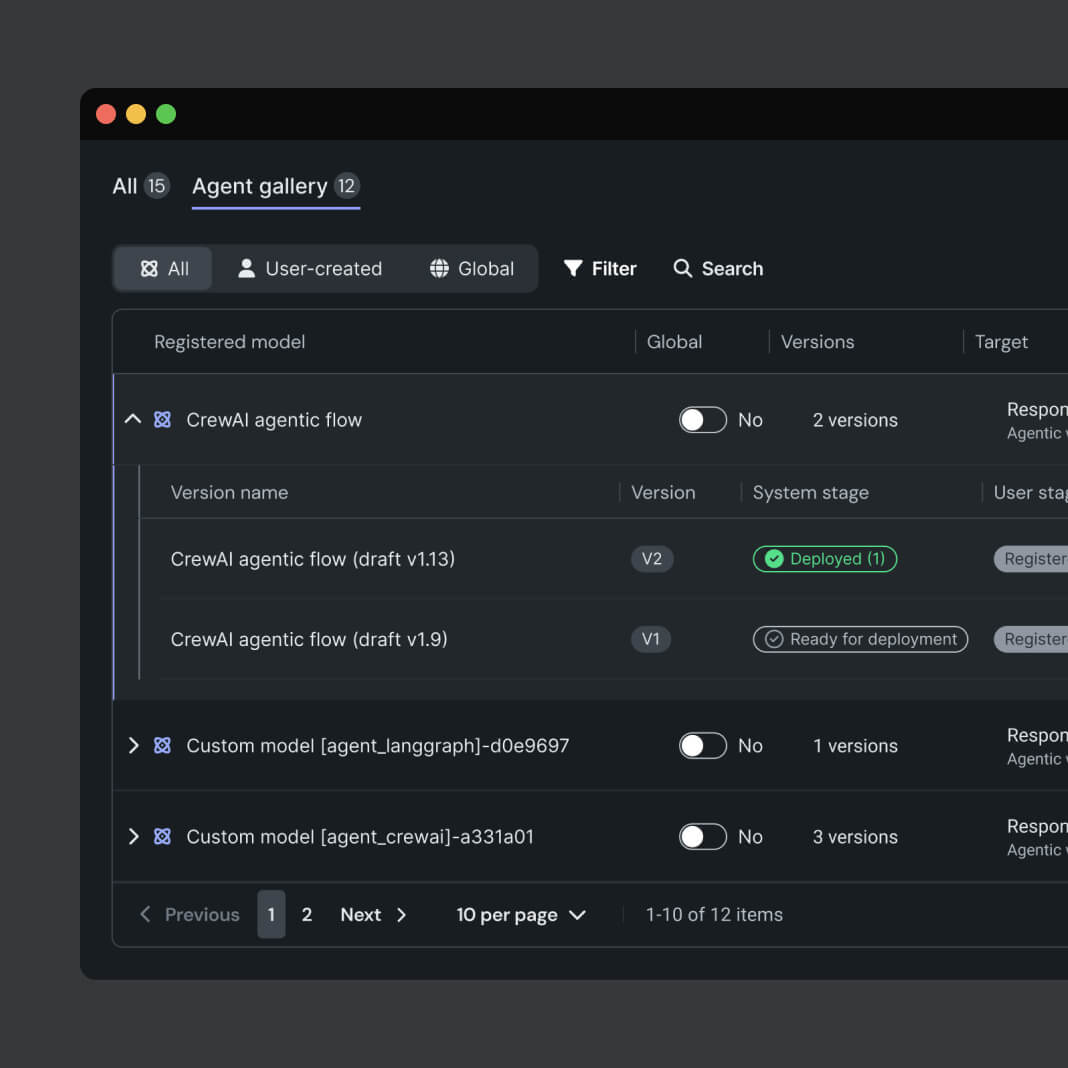
構築、運用、管理をひとつのエージェントプラットフォームで可能に
エージェントのライフサイクルのあらゆるフェーズを強力に推進
エージェントの構築
エンタープライズグレードのエージェントを独自の条件に合わせて構築
カスタマイズ可能なブループリントとあらかじめ用意された統合機能により、ユーザーの開発環境でも DataRobot の開発環境でも迅速な構築を実現
LLM から埋め込みまで、ユーザーのデータやユースケースに最適なコンポーネントを選択することで、単に機能を寄せ集めるのではなく、特定の目的に適したエージェントを構築可能
精度、レイテンシー、コストの最適なバランスを見つけ出し、本番環境で安定して動作するエージェントを提供可能
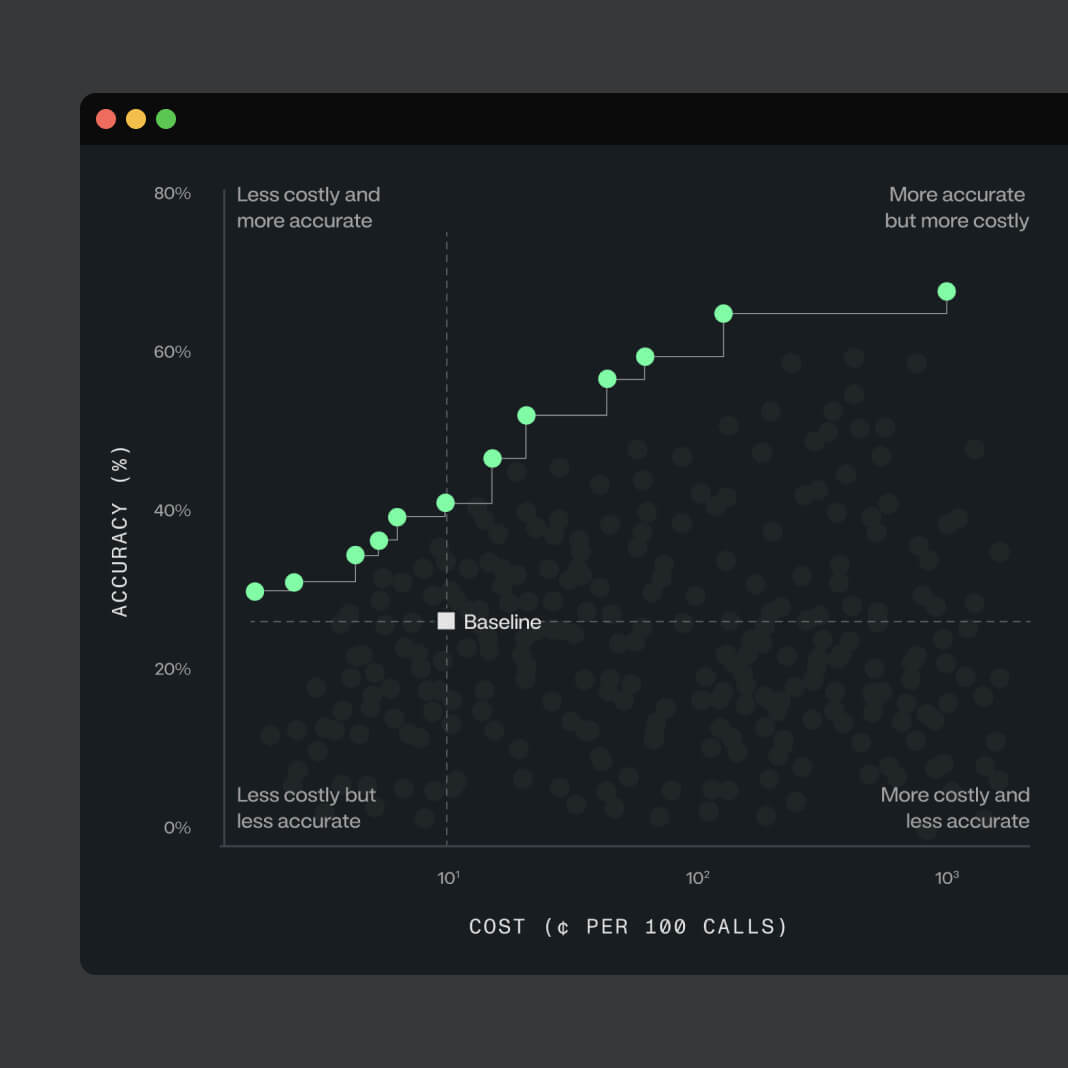
エージェントの運用
エージェントを常に安全かつ確実に実行
ダイナミックなコンピューティングオーケストレーションにより、エッジ、クラウド、オンプレミスを含むあらゆる場所にエージェントをデプロイ可能
リアルタイムでエージェントの品質を監視して問題をリアルタイムで軽減することで、安全かつ信頼性の高いパフォーマンスを確保
エージェントとユーザーを認証して、データと API へのアクセスを制御
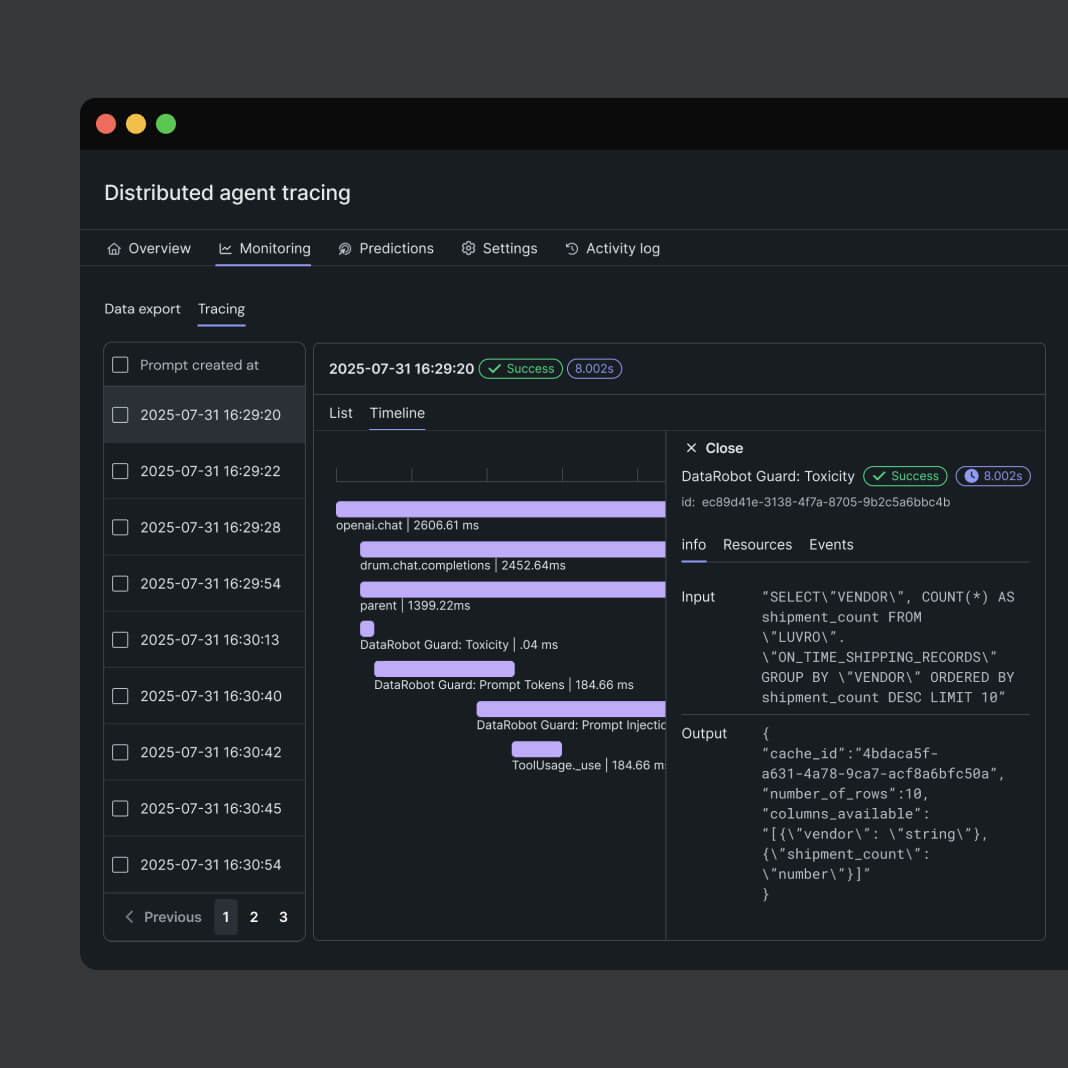
エージェントの管理
エージェントの暴走を阻止し、盲点を排除し、予期せぬ動作を回避
エージェントのライフサイクル全体ですべての資産と活動を追跡することで、包括的な可視性を確保し、実行される動作と場所を制御
アクセスから承認まで、強制力のある制御ルールを定義し、企業と業界のコンプライアンス要件に対応
テスト用のフレームワークと監査文書の自動作成機能を使用して動作の問題を検出し、ビジネスリスクを未然に防止
DataRobot は業界リーダーから高く評価されています
ガートナーの Magic Quadrant™ のデータサイエンスと機械学習プラットフォーム部門で、
複数年にわたってリーダーやカスタマーズチョイスに選出

IDC MarketScape の AI ガバナンスと ML 運用部門で
リーダーに選出
Forbes Cloud 100 と
Forbes AI 50 に複数年にわたって選出
AI イノベーションが評価され、Fortune 誌の「The Future 50」に選出
お客様の声
「企業の IT チームは、AI エージェントをインフラストラクチャーに統合して生産性を向上させるためのベストプラクティスを模索しています。NVIDIA Enterprise AI Factory のリファレンスデザインに DataRobot が追加されたことで、本番環境の AI に欠かせない基本的な監視、ガードレール、オーケストレーション機能を備えた AI エージェントをデプロイするための理想的なソリューションが提供されます。

6000 万ドルの ROI
調達から出荷まで
サプライチェーン全体をカバーする 50 以上の AI ユースケース
「DataRobot がチームにもたらしている大きなメリットは、反復作業を迅速に行えることです。おかげで、新しいことを試して、本番環境にすばやく導入し、実際のフィードバックに合わせて調整することが可能になりました。この柔軟性こそが重要であり、当社のようにレガシーシステムを利用している場合は、特に欠かせません。」

2 億ドルの ROI
掘削トラブルの検知から坑井能力の向上まで、
600 以上の AI ユースケース
「このプラットフォームは、Snowflake、SQL、S3 のデータを簡単に統合できるようにし、予測プロセス全体の自動化と迅速化に役立ちました。」

7000 万ドルの ROI
投資銀行業務から資産管理まで、
銀行全体で 40 以上の AI ユースケース