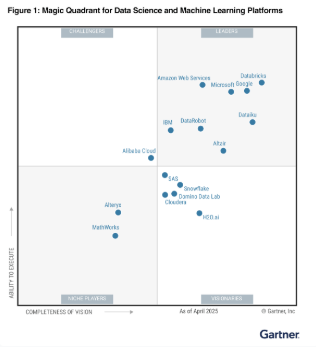
DataRobotのAIアプリケーションとプラットフォームは、業界をリードする技術で、ビジネスの成果を最大化し、リスクを最小限に抑えます。

ビジネスインパクトの実績
デプロイ期間を短縮
83%
ユースケースを本番環境で利用
100+
(1 日あたり)の予測を確実に生成
1.4B
世界中の企業の信頼を獲得 当社のお客様は、インパクトの最大化、イノベーションの加速、リスクの最小化を実現しています。



エンタープライズエコシステムへの組み込み
カスタムアプリケーション
ビジネスアプリケーション
LLM

データプラットフォーム
AI インフラストラクチャー


AI ジャーニーを開始する
ビジネスを変革する第一歩を踏み出しましょう。
お問い合わせ