モデル・リスク管理の原則におけるAIモデルの対応について Part 2
Part 1では、金融庁が公表したモデル・リスク管理に関する原則における対象やモデルやリスクなどの定義への考え方、全体の体制、8つある原則のまとめを表にして紹介した。Part2では、それぞれの原則が AI モデルにおいてどういった根本的意味合いを持つのかを具体的に解説したあとに、どう対応すべきかという問いに関して、AI サクセス(組織構築支援)という視点と DataRobot AI Platformで対応できる視点それぞれに付いて紹介する。
原則1-ガバナンス:取締役会等及び上級管理職は、モデル・リスクを包括的に管理するための態勢を構築すべきである。
AI 推進のための組織構築は多くの企業が検討してきたが、管理運用のための組織構築はまだ未着手という企業がほとんどであろう。本原則によって指針は示されたものの、実際に具体への落とし込みをする際にその難しさが顕在化するであろう。特に Part 1で述べたことの再強調になるが、AI モデル・リスクの管理を特定の個人のみに依存するのは限界がある。膨大なデータを扱い、複雑な処理を実施する AI モデル全てを人の頭脳によって把握・記憶することは困難であり、また例えできたとしてもそれは個別の力量の高い者に頼った結果であり、それらの者のリテンション問題が不安定要素として常に付き纏う。運用するAIモデルが多ければ多いほど、その限界は顕在化し、ツールをも活用した管理態勢が検討の俎上に上がってくるであろう。
原則2-モデルの特定、インベントリー管理及びリスク格付:金融機関は、管理すべきモデルを特定し、モデル・インベントリーに記録した上で、各モデルに対してリスク格付を付与するべきである。
昨今の AI プロジェクトは複数メンバーが担う傾向が高く、また人材の流動性が高くなっている観点からインベントリー管理の重要性は以前より高まっている。
気をつけるべきことは AI モデルはデータとコードから生成されるバイナリファイルに過ぎない点である。手元の AI モデルがなんのために生成されたものなのか、どういったデータとコードから作成されたものなのか、を正しく記録しておかないと再現性を満たすことができない。さらにコードとデータだけでなく、リスク格付など作成手順には含まれない情報も管理することが AI モデルの構築・運用におけるリソースをどこに割くのか判断する上で重要となる。
DataRobot はユースケース(AI 活用プロジェクト情報)登録機能を有している。AI モデルを生成するために利用したデータ、AI モデル生成過程が記録された AI モデル構築プロジェクト、運用に利用している AI モデルと IT アセットを登録するだけでなく、AI モデルが何の業務のために利用したものなのかや、AI モデルのビジネスにおける重要性(リスク格付)などの情報を登録・保持することができる。またユースケース登録機能で作成された各ユースケースは他のユーザーやグループに共有することが可能である。第1線がAIモデル作成まで完了した上で、ユースケースを第2線に共有すれば、それに紐づくデータやAIモデル構築プロジェクト、AIモデルへの参照を一元的に渡すことができる。
また、ユースケースへの更新はアクティビティとして全て記録されているため、第2線はどのような手順で第1線が AI モデルを構築していったのかを辿ることができ、そしてそこにコメントを残して再度第1線に返すこともできる。
原則3-モデル開発:金融機関は、適切なモデル開発プロセスを整備すべきである。 モデル開発においては、モデル記述書を適切に作成し、モデル・テストを実施すべきである。
AI モデルは、入力に対して確率値を返す動作は誤った AI モデルでも同じであるため、従来の IT 的なテストだけでなく生成元のデータとコード自体をチェックする必要がある。特に AI モデル生成には乱数が利用されるものも多いため、その再現性が可能な形で開発プロセスを整備する必要がある。さらに特定のツールで作成された AI モデルにおいては、そのツールが仮に利用できない状態になった場合での AI モデルの利用や再現を考慮することも重要である。そして AI モデルの限界を把握するためには、AI モデルの性質を可視化できるようにしておくべきであり、具体的には学習時に存在しない値や欠損データに対してどのように振る舞うのかなどを把握しておく必要がある。
精度面での検証では、ホールドアウト(= 学習に利用していないデータ)を利用する。これは学習時のデータだけではなく、未知のデータに対してもパフォーマンスを発揮する(= 過学習していない)AI モデルになっているかを確かめるために重要である。そしてホールドアウトそのものに過学習した AI モデルとなる可能性を防ぐ上でも、第1線からはホールドアウトが閲覧できない形で AI モデル構築を行える仕組みがあることが望ましい。
DataRobot は、AI モデル構築ステージにおいて、ブループリントと呼ばれるデータ前処理とアルゴリズム、ハイパーパラメータのチューニングが組み合わさったテンプレートが自動的に多数実行され、精度順にリスト化される仕組みとなっている。その上で、AI モデルが構築する上での学習データと検証、ホールドアウトデータの分割や全ての AI モデルに共通なモデル可視化機能も自動で実行される。また AI モデルの差別も海外では頻繁に問題として取り沙汰されているが、DataRobot は AI モデルが差別的な判定をしていないか、様々な尺度から構築段階で検知する仕組みを有している。
またベンダーロックインを防ぐ上で、より包括的なモデル記述書として、SR11-7に対応したAI モデル構築に関するモデルコンプライアンスレポートを自動で生成することも可能である。
原則4-モデル承認:金融機関は、モデル・ライフサイクルのステージ(モデルの 使用開始時、重要な変更の発生時、再検証時等)に応じたモデルの内部承認プロセスを有するべきである。
シャドウ IT という言葉が一時期話題になったが、AI モデルが誰にでも手軽に作成できるようになった今、「シャドウ AI モデル」が社内に氾濫する可能性がある。そのため、AI モデルを安全に正しく使う上でも、第2線からの独立的なチェック体制及び、稼働開始フローをシステム的にも整備することが重要となる。また AI モデルは導入後にも時間とともに精度が劣化する性質から、定期的な再学習を必要とする。すなわち、AI モデルにおいては使用開始時のみに気を配るのではなく、再学習という変更の発生が従来の IT システムに比べて頻繁に起こることを考慮した内部承認プロセスを構築する必要がある。
DataRobot では AI モデル・ライフサイクルのステージに合わせたタスク、またそのタスクへの関わり方に応じて権限分掌を行うことができる。そして、権限分掌を行った上で、AI モデル・ライフサイクルのステージ変更及びその AI モデルの重要度に応じて、設定した承認ポリシーに従った承認ワークフローを設定することが可能である。これにより、第1線と第2線での内部承認プロセスをシステムとして構築することができるようになる。
原則5-継続モニタリング:モデルの使用開始後は、モデルが意図したとおりに機能していることを確認するために、第1線によって継続的にモニタリングされるべきである。
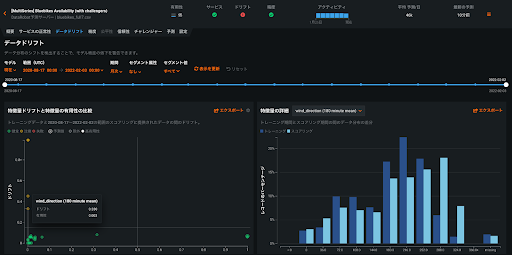
AI モデルは時間とともに当初想定していた性能を発揮しなくなる。また急激な市場の状況やその他の環境の変化等によって AI モデルの性能が大幅に劣化することは少なくない。実際、本稿執筆時(2022年3月)、新型コロナウイルスの蔓延に伴い、過去に作成された多くの AI モデルが再作成を余儀なくされている。このような AI モデルの性能変化を適切な間隔でモニタリングすることで、モデルを再作成するべきタイミングを適切に検知し、劣化したモデルの使用によってもたらされる経済的損失を未然に防ぐことができる。AI モデルにおけるモニタリングポイントは、従来のシステム的な「サービス正常性」と AI モデル特有の「データドリフト」と「精度変化」の三点となる。
「サービス正常性」とは、運用に利用している AI モデルがシステムとして正常に稼働しているかを確認するものである。未知の入力が来た場合のエラーハンドリングをできているかなども含まれている。また従来の統計モデルに対して複雑化した AI モデルは推論時においても処理時間がかかるものもあるため、想定時間内に計算が完了しているかなどもチェックは必須となる。
「データドリフト」とは、AI モデルの運用にとって非常に重要な概念となる。学習時と推論時の各特徴量(説明変数)の分布が変化したことを表現する言葉で、データドリフトが発生していると AI モデルが学習時と同等の性能を発揮しない可能性が高い。データドリフトが発生する要因はいくつかあるが、代表的なカテゴリとしては以下の2つとなる。
- 時間経過とともに全体のトレンドがドリフトするもの
- 学習時と推論時の条件違いによって発生するもの
「時間経過とともに発生するデータドリフト」も、緩やかに発生するものや急激に発生するもの、周期的に発生するものがあるため、データドリフトが発生するサイクルに合わせて AI モデルの再学習を計画することが重要である。これらのドリフトは世の中のトレンドに影響を受けて起こるため、AIモデル作成者自身もその発生タイミングで感覚的に気づける場合が多い。
もう一つの学習時と推論時の条件違いによるデータドリフトは、データ変換処理上の違いが原因で発生する。同一の変換処理を利用しない理由として、例えば”学習時にはバッチで学習データを準備したが、運用時はオンライン推論だったため、それぞれの処理で通るデータパイプラインが違った”などが存在する。
変換処理の違いで実際に起こりうるものには以下のようなものがある。
- 学習時にだけ表記ゆれを修正し、推論時には表記ゆれ修正を行っていない
- 学習時と推論時でエンコーディングが違い一部の値が別の値として認識されている
- SQL の処理系の中で学習と推論時で欠損値の扱い方が違う
これらはそもそもがミスが起点で発生しているため、AI モデル作成者が捉えることは難しい。ただし、データドリフト検知を実施することによってミスに気付くことができるため、中長期的な AI モデル運用だけでなく、短期的なモニタリングにおいてもデータドリフト検知は重要となる。
「精度変化」はそのまま AI モデルの最終パフォーマンスを見るものだが、注意すべきは、精度が変化したことに気づくまで推論時点からはラグがあるということである。仮に AI モデルが3ヶ月後のデフォルトを予測しているものだった場合、その正解データは3ヶ月後にならないと収集することができない。この点からも AI モデル運用では精度変化を検知することも重要だが、精度変化だけでなく、先に上げたデータドリフトをモニタリングし、未然にリスクを検知することが重要となる。
DataRobot 内で作成した AI モデル及び Python、R、SAS などで作成した AI モデルを DataRobot に取り込んだ場合には自動的に「サービス正常性」「データドリフト」「精度変化」を時間および特定のセグメントごとにモニタリングできる。また DataRobot から外部に書き出された AI モデルでも、エージェント機能によって「データドリフト」「精度劣化」を同様にモニタリングできる。そして、運用状況をデプロイレポートとしてスケジュールされたタイミングで自動発行する機能も有しているため、AI モデルが増えた場合においてもスケールする運用体制を構築することができる。

原則6-モデル検証:第2線が担う重要なけん制機能として、金融機関はモデルの独立検証を実施すべきである。独立検証には、モデルの正式な使用開始前の検証、重要な変更時の検証及びモデル使用開始後の再検証が含まれる。
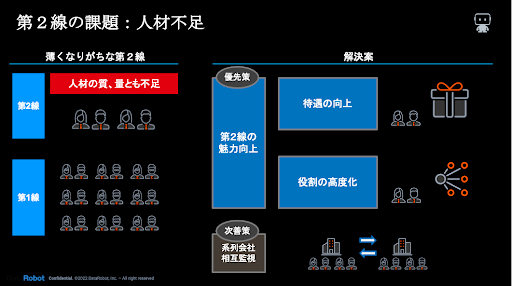
第2線に関する議論、特に体制面での議論に落とし込むと、一つ大きな課題が見えて来る。本原則の3つの防衛線ルールでの第2線は、原則1.4においてそれが第1線から独立すべき監督部門となるべき、とされている。第3線が管理態勢全般への監督を役割とする以上、実質的な管理監督の要はこの第2線であるため、その役割は極めて重大だ。ただ、”この役割に付きたい人はいるのだろうか?”
AI モデル分析は現在最も先進性/将来性の高い領域の一つだ、データサイエンティストを志す者が、膨大な時間をかけてスキルを身につけてきたのも、その最前線で挑戦を続け、更なる高みとリターンを目指すためであり、「管理監督」という一歩引いた役割を望む者は少ないであろう。一方でAIモデルリスク発生時のインパクトを考えれば、企業としてはこの役割に最先端の知識を持つ者を配置したい。米国での AI 普及の初期を振り返ってみると、多くの企業でこのギャップが見落とされていた。例を挙げると第2線に引退間近の人員を配置し、管理態勢が形骸化し、リスクへの防衛が疎かになってしまった。この課題を解決し、強固な第2線体制を構築するには3つの方法があり得る
① 系列企業の第1線同士が検証し合う体制の構築
② 第2線ポジションの魅力向上
③ 牽制役ではなく、第1線と共闘する第1.5線の設計
①
ごく自然に思いつく打ち手だが、系列各社の第1線が他社の第1線の AI モデルを検証することができれば、上記の課題にはなりうる。金融庁の質疑回答を確認する限り、この対策は推奨されているとまでは言えないが、明確な否定もなく、その妥当性はどちらかと言うと、企業ごとの実務的な有効性次第であろう。系列企業とは言え、業務を異にする以上、他社の AI モデルをどれだけ理解し、有効な検証ができるかは各社が慎重に判断すべきであろう。
②
上記の打ち手が現実的でない日本企業には、米国企業の反省を踏まえると、ぜひ第2線のポジションの強化、そしてそのための人材キャリアパス設計を進言したい。端的に言えば、第2線での役割でも十分な報酬を期待でき、社内的にも将来性のあるキャリアパスが見えれば、スキルの高い人材にも十分魅力的なポジションとなる。
このような管理監督ポジションはどうしても軽視されがちだが、今一度AIモデルリスクのインパクトを概算して頂きたい。その数字を見れば、このポジションにいくらのコストをかけるべきか、自ずと見えて来るはずだ。
③
また、そもそもの役割として第2線を単なる第1線に対する牽制役とすべきではなく、もっと第1線と共闘する役割と考えても良いのではないか。第2線のポジションはある意味、ガードレール的な役割だが、現在 AI モデルリスク管理においては絶対的に正しいガードレールは存在しない。ならば、第2線は第1線がやろうとすることの本質を正確に捉え、リスクを抑止しつつ、その実現をサポートする、いわば「第1.5線」の役割である方がより現実的である。それにより第1線はより積極的に第2線の協力を仰ぐようになり、“守り”だけではなく、“攻め”をも兼ねた AI モデル検証体制が構築できるはずだ。
原則7-ベンダー・モデル及び外部リソースの活用:金融機関がベンダー・モデル等や外部リソースを活用する場合、それらのモデル等や外部リソースの活用に対して適切な統制を行うべきである。
ベンダー・モデルのデータやパラメーター等が不透明な場合に生じるリスクとしては、以下の2つが存在する。
- ベンダーがサービスを停止した際に再現性が保てなくなるリスク
- モデルの特性や限界を正しく把握できないリスク
1つ目のリスクはベンダー・サービスより API 経由で AI モデルを利用している場合などにおいて、その API が使えなくなることを意味する。このリスクを回避するためには、AI モデルをベンダー・サービスと切り離せる何らかの仕組みをそのベンダーが提示できるかどうか確認する必要がある。
2つ目のリスクはベンダー・サービスの AI モデルに予期しないバイアスが含まれていることやどのようなパターンで精度が劣化するか把握できていないことを意味する。リスク回避手段の一つは、AI モデルの性質を調べるためベンダーに学習用データとコードの開示を要求することだが、学習データやコードの開示はそのベンダーの知的財産にも関わるため現実的ではない。現実的には、AI モデルのリスク格付けが高いものに関しては、ベンダー・モデルの利用を停止するという手段も選択肢にいれるべきである。補足となるが、近年の AI モデルは複雑化しており、ベンダー・モデルが一部処理のみで使われている場合も存在し、一見手元のデータからゼロベースで学習させたと思っていても潜在的にベンダー・モデルが紛れている可能性もある。そのため、AI モデルの透明性を求めた上でその内容を注意深く確認する必要がある。
DataRobot は、基本的には企業内での AI モデルの内製化を目指したプラットフォームであり、ベンダー・モデルに該当するケースは多くはない。ただし、一部の高度な分析テンプレートにおいては、事前学習済みのモデル(高度な自然言語処理や画像データの前処理)を含んだものが存在する。DataRobot では、これらの処理が使われた AI モデルかどうかを確認することができるため、該当処理を含まない AI モデルを選択することもできる。また、他の処理は残したまま、該当処理だけを除きたいという要望に対しては、自動生成された分析テンプレートを編集する ComposableML 機能も備えている。
そして内製化を目的としてDataRobotを導入しても、その利用者をすべて外部リソースに頼っている場合には、活動の結果を理解し、適切に評価することは難しい。外部リソースの活用をリスク管理を実施した上で実現できるためにも、ツールの導入だけでなく、人材育成は重要なウェイトを占めることになる。
原則8-内部監査:内部監査部門は、第3線として、モデル・リスク管理態勢の全体的な有効性を評価すべきである。
第3線の論点も多々あるが、一つ絞るなら、“今ではなく、これから”を見据えた管理監督が求められる。監督対象として企業が“今”どんな AI モデル・リスク管理態勢にあるのか、は当たり前として、第3線は企業の AI 戦略、つまり“これから”やろうとすることまで、助言し監督すべきである。さらにその前提として、常に最新のトレンドと情報を踏まえたアドバイスを求められる。前述のように AI モデルリスクがどんどん進化する以上、管理監督の論点も変化し続けているため、それらをいち早くキャッチアップし、社内での検証・改善に落とし込める機能が第3線に求められる。しかし、そこまで行くとやはり管理監督体制は一朝一夕で構築できるものではない。したがって企業によっては一定の外部支援を初期は求めるのも一つの手であろう。
まとめ
本稿ではあくまで AI モデルに注視して記述したが、モデル・リスク管理の原則では、モデルの定義は統計モデルやルールベースモデルなど、様々な手法をカバーするものと回答されており、AI モデルに限定されるものではない点には注意が必要となる。
リスク管理では、組織的な体制、人材の育成、またそれらをサポートするシステムが重要となる。AI モデル活用が金融機関において拡大中のいま、本ブログ及び弊社ソリューションが参考になれば幸いである。
参照文献
金融庁:モデル・リスク管理に関する原則
金融庁:コメントの概要及びコメントに対する金融庁の考え方
COSO──ガバナンスと内部統制3つのディフェンスライン全体でのCOSOの活用
三つの防衛線(3つのディフェンスライン)によるリスクマネジメント
Machine Learning in Production: Why You Should Care About Data and Concept Drift

