銀の弾丸:最適化されたエージェント型ワークフローへの近道
本ブログはグローバルで公開された「Silver bullets: a shortcut to optimized agentic workflows」の抄訳版です。
要約(TL; DR)
エージェント型AIのプロジェクトが壁にぶつかる一番の原因は、目的に合わなくなったワークフローを使い回してしまうことです。私たちはsyftrというツールを使って、複数のデータセットで常にうまく機能する特別なワークフローを発見しました。これを「silver bullet(銀の弾丸)」と呼んでいます。
この「銀の弾丸」は、コストを抑えながらも、驚くほど高い精度と速さを実現します。ランダムな方法や、過去の学習を流用する方法よりも、ずっと早く成果を出せるのです。完全な分析にかかるコストのわずかな費用で、約75%もの性能を引き出せるので、プロジェクトの素早いスタート地点として最適です。もちろん、さらに性能を高める余地も残されています。
もし、あるプロジェクトで使ったエージェント型ワークフローを別のプロジェクトで再利用しようとしたことがある方であれば、それがうまくいかないことが多いのをご理解いただけると思います。それはモデルが扱えるコンテキスト長が足りなかったり、より複雑な推論、あるいは応答速度の要件が変わることがよくあるためです。
古い設定がたまたま機能しても、新しい課題に対しては、性能が過剰でコストが高すぎる場合があります。そうした時は、もっとシンプルで速い設定の方が良いこともあります。
そこで私たちは、この疑問に答えを出そうと考えました。
「多くの用途でうまくいく、万能なエージェント型フローは存在するのか?もし存在するなら、それを目的に応じて選んで、すぐにプロジェクトを進められるか?」
私たちの研究の結果、答えは「イエス」でした。それが、私たちが「銀の弾丸」と呼ぶものです。
私たちは、低遅延(速さ)と高精度という二つの目標に向けた「銀の弾丸」を見つけ出しました。これらは、最適化の初期段階で、他の一般的な手法を圧倒し、全体のコストを大幅に削減します。
以下のセクションでは、それらをどのように発見したのか、そして他の戦略と比べてどれほど優れているのかを詳しく説明します。
パレートフロンティアの基礎知識
専門的に学ぶ必要はありませんが、パレートフロンティアを理解すると、本ブログの内容をより理解しやすくなります。図1は、私たちの実験結果ではなく、syftrの最適化トライアルの完了状況を示す散布図の例です。サブプロットAとサブプロットBは同じものですが、Bでは最初の3つのパレートフロンティア、つまりP1(赤)、P2(緑)、P3(青)がハイライトされています。
- 各試行(Each trial): 特定のフロー設定について、精度と平均レイテンシー(応答時間)が評価されます(高精度・低レイテンシーが好ましい)。
- パレートフロンティア(P1): これより高い精度と低いレイテンシーの両方を同時に達成するフローは他に存在しません。
- 非パレートフロー(Non-Pareto flows): 少なくとも一つのパレートフローが、両方の指標でこれらのフローを上回ります。
- P2、P3: P1を取り除くと、P2が次に優れたフロンティアとなり、その次にP3が続きます。
パレートフローの中から、優先順位(例えば、最高の精度よりも低レイテンシーを優先するなど)に応じて選ぶことはあるでしょう。しかし、パレートフロー以外のフローを選ぶことは絶対にありません。なぜなら、フロンティア上には常により優れた選択肢が存在しているからです。
syftr を使用したエージェント型AIフローの最適化
私たちは実験を通して、精度とレイテンシーの観点からエージェント型フローを最適化するためにsyftrを使用しました。
このアプローチにより、以下のことが可能になります。
- 質問と回答(QA)のペアを含むデータセットを選択する
- フローパラメーターの探索空間を定義する
- 精度やコスト、または今回のケースでは精度と応答速度のような目標を設定する
つまり、syftrは、設定した目標に基づいてフロー構成の探索を自動化するツールなのです。
図2は、syftrのハイレベルなアーキテクチャを示しています。
エージェント型フローのパラメーター設定は事実上無限に存在するため、syftrは2つの重要な技術に依存しています。
- 多目的ベイズ最適化:探索空間を効率的にナビゲートします。
- ParetoPruner:最適でない可能性が高いフローの評価を早期に停止し、時間と計算リソースを節約しながらも、最も効果的な構成を見つけ出します。
「銀の弾丸」実験
私たちの実験は、4つのパートからなるプロセスに従って行われました(図3)。
A: シード設定に単純なランダムサンプリングを使用し、syftrを実行します。
B: 完了したすべてのフローを、他のすべての実験で実行します。これにより生成されたデータが次のステップの入力となります。
C: 「銀の弾丸」の特定と転移学習の実施。
D: 4つの未検証のデータセットに対して、3つの異なるシード設定戦略を使用し、それぞれ3回ずつsyftrを実行します。
ステップ1:データセットごとにフローを最適化する
私たちは、以下の各データセットに対して数百回の試行を実行しました。
- CRAG Task 3 Music
- FinanceBench
- HotpotQA
- MultihopRAG
各データセットに対し、syftrは精度とレイテンシーを最適化するパレート最適フローを探索しました(図4)。
ステップ2:「銀の弾丸」を特定する
すべてのトレーニングデータセットで同一のフローをチェックし、私たちは「銀の弾丸」を正確に特定することができました。それは、すべてのデータセットで平均してパレート最適となるフローです。
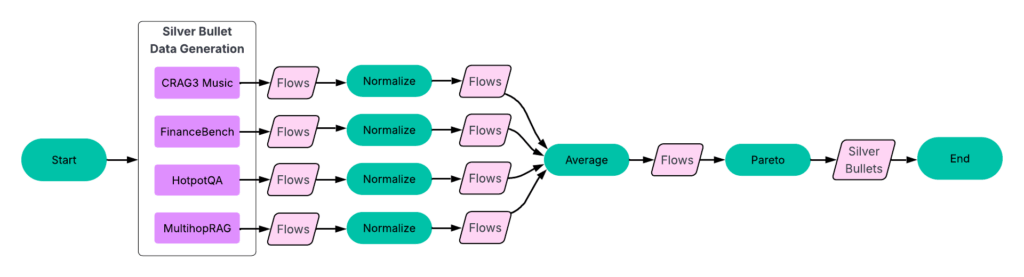
プロセス
- データセットごとの結果を正規化する 各データセットについて、精度とレイテンシーのスコアを、そのデータセット内の最高値で正規化します。
- 同一のフローをグループ化する 次に、複数のデータセットで一致するフローをグループ化し、それらの平均精度と平均レイテンシーを計算します。
- パレートフロンティアを特定する この平均化されたデータセット(図6を参照)を使用して、パレートフロンティアを形成するフローを選び出します。
これらの23のフローが、私たちが探し求めていた「銀の弾丸」です。これらは、すべてのトレーニングデータセットで優れた性能を発揮するものです。
ステップ3:転移学習によるシード設定
元のsyftrに関する論文で、私たちは最適化のシード設定方法として転移学習を検討しました。ここでは、それを「銀の弾丸」によるシード設定と直接比較します。
この文脈において、転移学習とは、(今回のテストとは別に)過去にトレーニング用データセットで行った一連の実験結果の中から特定の高性能なフローを選択し、未検証のデータセットでそれらを評価することを意味します。ここで使用するデータは、「銀の弾丸」の特定に使用したデータと同じです(図3を参照)。
プロセス:
- 候補を選択する 各トレーニングデータセットから、パレートフロンティアの上位2つ(P1およびP2)から最も性能の高いフローを選び出しました。
- 埋め込みとクラスタリング BAAI/bge-large-en-v1.5の埋め込みモデルを使用し、各フローのパラメーターを数値ベクトルに変換しました。次に、K-meansクラスタリング(K=23)を適用して、類似したフローをグループ化しました(図7を参照)。
- 実験の制約に合わせる 公平な比較のため、各シード設定戦略(「銀の弾丸」、転移学習、ランダムサンプリング)を23フローに限定しました。これは、私たちが特定した「銀の弾丸」の数と同じです。
注記: シード設定のための転移学習はまだ完全に最適化されているわけではありません。より多くのパレートフロンティアを使用したり、より多くのフローを選択したり、異なる埋め込みモデルを試したりすることも可能です。
ステップ4:すべてのテスト
最終評価段階(図3のステップD)では、Bright Biology、DRDocs、InfiniteBench、PhantomWikiという4つのテストデータセットに対して、約1,000回の最適化試行を実行しました。以下の3つのシード設定戦略ごとに、このプロセスを3回繰り返しました。
- 銀の弾丸によるシード設定
- 転移学習によるシード設定
- ランダムサンプリング
各試行では、GPT-4o-miniが審判を務め、エージェントの応答が正解(ground-truth answer)と一致しているかを検証しました。
結果
私たちは、以下の問いに答えを出すことを目指しました。
「ランダムサンプリング、転移学習、銀の弾丸のうち、新しいデータセットで最も少ない試行回数で最高のパフォーマンスを発揮するシード設定方法はどれか?」
そこで、未検証の4つのテストデータセット(Bright Biology、DRDocs、InfiniteBench、PhantomWiki)について、以下の点をプロットして比較しました。
- 精度(Accuracy)
- レイテンシー(Latency)
- コスト(Cost)
- パレートエリア(Pareto-area):結果が最適解にどれだけ近いかを示す指標
各プロットにおいて、垂直の点線は、すべてのシード設定試行が完了した時点を示しています。シード設定後、「銀の弾丸」は、他の戦略と比較して平均して以下の優れた結果を示しました。
- 最大精度が9%向上
- 最小レイテンシーが84%低下
- パレートエリアが28%拡大
Bright Biology
銀の弾丸は、シード設定後に最高の精度、最低のレイテンシー、そして最大のパレートエリアを達成しました。ランダムなシード設定の中には、完了しなかった試行もありました。すべての方法でパレートエリアは時間の経過とともに増加しましたが、最適化が進むにつれてその差は縮まりました。
DRDocs
Bright Biologyと同様に、DRDocsでも「銀の弾丸」はシード設定後に88%というパレートエリアに達しました。これは、転移学習の71%やランダムサンプリングの62%と比較しても、非常に優れた結果です。
InfiniteBench
「銀の弾丸」が到達したパレートエリアに他の手法が追いつくには、約100回もの追加試行が必要でした。それでも、約1,000回の試行が完了するまでに、「銀の弾丸」で見つかった最速のフローには及びませんでした。
PhantomWiki
今回も、シード設定後に「銀の弾丸」が最高のパフォーマンスを発揮しました。このデータセットでは、コストのばらつきが最も大きくなりました。約70回の試行後、「銀の弾丸」による実行は、一時的により高コストなフローに集中しました。
パレートフロンティア分析
「銀の弾丸」でシード設定を行った試行では、平均して、23個の「銀の弾丸」フローが、1,000回の試行後の最終的なパレートエリアの約75%を占めました。
- 赤色の領域: 初期の「銀の弾丸」のパフォーマンスからの最適化による向上分
- 青色の領域: 最終段階でも依然として優位性を持つ「銀の弾丸」フロー
私たちの結論
「銀の弾丸」によるシード設定は、転移学習が多様な過去のパレートフロンティアのフローから選ばれているにもかかわらず、一貫して優れた結果をもたらし、転移学習を上回るパフォーマンスを発揮します。
私たちが設定した2つの目標(精度とレイテンシー)において、「銀の弾丸」は常に他の戦略のフローよりも高い精度と低いレイテンシーからスタートしました。
長期的に見ると、TPEサンプラーが初期の優位性を縮小させます。数百回の試行後には、すべての戦略の結果が収束することがよくあります。これは、最終的にどの戦略も最適なフローを見つけ出すはずであることを考えると、当然の結果です。
では、多くのユースケースでうまく機能するエージェント型フローは存在するのでしょうか?答えは「ある程度は存在する」です。
- 平均して、少数の「銀の弾丸」は、完全な最適化で得られるパレートエリアの約75%を達成します。
- Bright Biologyでは92%の再現率を達成したのに対し、PhantomWikiでは46%にとどまるなど、パフォーマンスはデータセットによって異なります。
結論として、「銀の弾丸」は、完全なsyftr実行を模倣するための安価かつ効率的な方法ですが、完全な代替品ではありません。より多くのトレーニングデータセットや、より長いトレーニング最適化を行うことで、その影響力はさらに高まる可能性があります。
「銀の弾丸」のパラメーター設定
私たちが使用したパラメーターは以下の通りです。
LLM(大規模言語モデル)
- microsoft/Phi-4-multimodal-instruct
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
- Qwen/Qwen2.5
- Qwen/Qwen3-32B
- google/gemma-3-27b-it
- nvidia/Llama-3_3-Nemotron-Super-49B
埋め込みモデル
- BAAI/bge-small-en-v1.5
- thenlper/gte-large
- mixedbread-ai/mxbai-embed-large-v1
- sentence-transformers/all-MiniLM-L12-v2
- sentence-transformers/paraphrase-multilingual-mpnet-base-v2
- BAAI/bge-base-en-v1.5
- BAAI/bge-large-en-v1.5
- TencentBAC/Conan-embedding-v1
- Linq-AI-Research/Linq-Embed-Mistral
- Snowflake/snowflake-arctic-embed-l-v2.0
- BAAI/bge-multilingual-gemma2
フローの種類
- vanilla RAG
- ReAct RAG agent
- Critique RAG agent
- Subquestion RAG
低精度/低レイテンシーから高精度/高レイテンシーの順に並べた、全23種類の「銀の弾丸」の完全なリストは、silver_bullets.jsonをご覧ください。
ご自身で試してみる
これらのパラメーター設定で実験してみたいですか?syftrのリポジトリにあるrunning_flows.ipynbノートブックを使ってみてください。ただし、上記に挙げたモデルへのアクセス権が必要です。
syftrのアーキテクチャやパラメーターについてさらに詳しく知りたい場合は、私たちのテクニカルペーパーを読むか、コードベースを探索してみてください。
また、私たちはこの研究について、2025年9月にニューヨーク市で開催される国際会議(International Conference on Automated Machine Learning)でも発表する予定です。