AI分析における知識整理の重要性
はじめに
DataRobotでヘルスケア分野と製造業のお客様を担当しているデータサイエンティストの伊地知です。予測分析や要因分析に用いるAIモデルの精度を高くするためには、精度に影響を与えると思われる本質的な要因をできるだけ組み込んだモデルを作ることが重要です。その際、業務プロセスに精通したエキスパートがドメイン知識に基づいて予測ターゲットと関係の強い本質的な要因が何であるかをよく検討し、AI分析の前に予めドメイン知識を整理して「要因から結果にいたる機序(メカニズム)」について有力な仮説を立てておくと、限られた時間の中で効果的にAIモデルの精度を改善するのに役立つでしょう。
本稿では、AI/機械学習を利用した予測分析/要因分析においても推奨される、ドメイン知識整理の具体的な方法を3つ解説します(表1)。
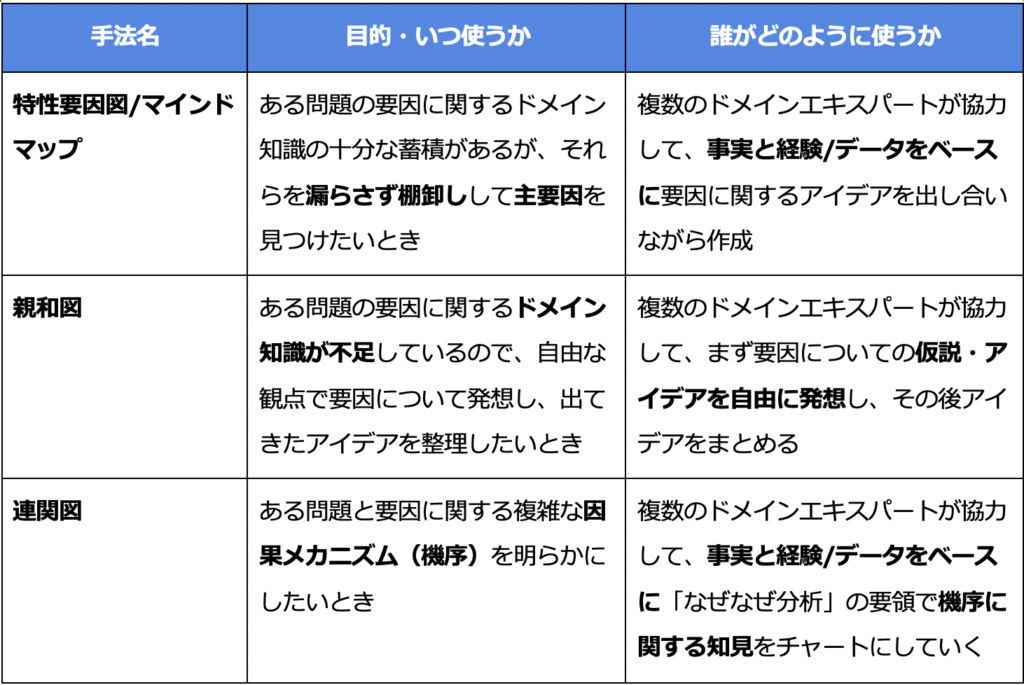
これらは1950年代から今まで日本の産業界、特に製造業を中心に導入された品質管理フレームワークで使われているツールですが、2020年代のAI分析プロジェクトにおいても大変有効に機能すると筆者は考えています。
要因アイデアを自由発想し、まとめる方法 – ブレインストーミング〜親和図法
例えばEコマースサイトで、ある商品の売り上げ予測を行うケースを考えてみましょう。売り上げ金額に影響を与える要因として何が考えられますか?
以前その商品を人が販売していたときには、過去の販売経験や現場で学んだ事実に基づき、様々な要因についてかなり具体的で詳しいアイデアをお持ちだったかもしれません。しかし熟練者がリタイアし、また販売プロセスの主流がWebに変わったために、今は「その商品がなぜ売れるのか/売れないのか」が今ひとつ分からなくなってしまっているかもしれません。
すなわち、この仮想ケースでは「その商品をEコマースサイトで販売すること」に関するドメイン知識がまだ不十分な可能性が高く、AIで分析しても売り上げと関係が深い重要な因子(Vital Few Factor/Feature)を発見できないかもしれません。そこで、もっと要因についてのアイデアをたくさん出し、それらの言語情報を整理する必要があります。
こうしたアイデア出しと言語情報整理のために、品質管理の分野では以下の2ステップアプローチがよく使われています。
- 要因についてのアイデアを沢山出す:ブレインストーミング
- 「要因候補」について書かれた言語情報を整理する:親和図(KJ法)
ブレインストーミングは多くの方が実際に経験したことがあるのではないでしょうか。参加者は下記4つのルールを遵守すべきとされますが、筆者の経験でも議論が白熱するとついつい(特に1を)忘れてしまいがちです。そこで、可能であればブレインストーミングをコントロールする中立的な立場のファシリテータにも参加してもらって実施した方がベターです。
- 人の意見を否定したり判断しない
- アイデアの質より量を重視する
- アイデアを結合したり一部を発展させたりすることを推奨
- 奇抜な考え方やユニークなアイデアを歓迎する
考案者である川喜田二郎博士(1920-2009)のイニシャルを充てたKJ法は、品質管理分野で言語データを活用するためのフレームワーク「新QC七つ道具」[5]の一つとして採用され、そのときに「親和図」法と命名されました。
具体的には、ブレインストーミングによって得られた様々なアイデア(言語データ)をカードなどに「1枚1アイデア」の形式で表記し、それらを「似たもの同士のグループ」にまとめていきます。小売業界で一般的な「顧客の成約確率」を予測するテーマで、要因となりうる因子は何かブレインストーミングした結果を親和図にまとめると下図1のようになるかもしれません。

要因に関するドメイン知識整理の方法 – 特性要因図
ある問題の要因に関するドメイン知識の十分な蓄積がある場合、それらのドメイン知識をうまく整理するのに有用なフレームワークとして、石川馨博士(1915-1989)が1950年代に考案した特性要因図(フィッシュボーンチャート, Cause and Effect Diagram)[1]が日本の産業界(特に製造業)ではよく使われています。
特性要因図を使ったドメイン知識整理は下記ステップで行います。(複数のドメインエキスパートの共同作業で進めていくことを想定しています)
- 下図のように、特性要因図の一番右側には「結果(エンドポイント)」に当たる事象、すなわち品質問題やイベントの発生、あるいは機械学習の予測ターゲットとなる目的変数を記入します。
- 次に、説明変数に該当する「要因の候補」をその左側から矢印を引いて書くのですが、この時に複数の説明変数をある程度の大枠で分類し「大骨」とします。製造業においては以下の「5M+E」でまとめていく手法が推奨されていますが、これらの分類は製造業だけでなく広く業務プロセス全般にも適用可能です。
- 材料・部品 (Material)
- 設備・機械 (Machine) ※非製造業であれば「ツール」と読み替える
- 作業者 (Man)
- 作業方法 (Method)
- 検査・測定 (Measurement)
- 環境 (Environment)

- 「大骨」の情報が書き上がったら、それらから情報をさらにブレイクダウンして、「中骨」や「小骨」の情報にできるかどうかを検討します。
- 上図の形式で特性要因図を描き上げたら、次に要因候補等に考察を加え、「どの要因候補から先に『結果』との関係性をチェックするか?」を決めていきます。その際にとても有効なのが、要因候補等を以下の定義で、CNX のいずれかに分類する手法です。(このやり方は、日本流品質管理がアメリカに渡ってシックスシグマ方法論[2]になった後に、主に間接業務プロセスでのシックスシグマ改善活動を促進するために発案されたものと筆者は記憶しています)
- C(Constant):
自分達で制御可能だが、現在すでに最適状態に固定されていると考えられる要因 - N(Noise):
自分達では制御できない、あるいは現在制御していない要因(誤差因子と言う) - X(Experimental):
自分達で制御可能で、実験/シミュレーションを行って結果への影響の大きさを評価し、最適値を探索するべき要因(制御因子と言う)
なお、本稿の主題から少々脱線しますが、品質改善活動の方法論であるシックスシグマを間接業務プロセスの改善活動にも適用して成果を出したいという動きに合わせて、PF/CE/CNX/SOP なるアプローチが開発されました。これはそれぞれ以下の略称を合わせたものですが、筆者も昔実際にこの順番に間接業務プロセスの改善プロジェクトを進めたところ、しっかり成果が出たことを覚えています。今でも通用するパワフルなアプローチだと思います。なお業務フロー図の描き方は専門解説書(例えば[3])を参照ください。
- PF(Process Flow Diagram):業務フロー図
- CE(Cause and Effect Diagram):特性要因図
- CNX:CNX 分類
- SOP(Standard Operating Procedures):標準作業手順
さて、仮想事例ですが、下図3は「超音波診断装置ブローブの最終検査感度不良」を題材に特性要因図を描いて CNX フラグを追記したチャートになります。

CNX 分類までできたら、その後の基本的な方針は、以下のどちらかあるいは両方になります。
- 結果(エンドポイント)と関係性の強い N(誤差因子)を制御して影響を抑制する
- あるいは「Nに大きな影響を受けないように X(制御因子)を最適値に設定する」
方針Aは、もしNを低コストで制御できる場合には合理的な方針です。具体的には「今SOP(Standard Operating Procedures:標準作業手順)が定まっていなくて個人の判断任せになっているクリティカルなプロセスにSOPを導入し作業員にトレーニングも行う」などのケースをイメージしてみてください。このとき、本当にそのプロセスがクリティカルであることを予め知っていなければなりません(そうでないとSOP導入にかかる手間やコストと比較してROIが出ません)。したがってそのN(誤差因子)が結果(エンドポイント)と強い関係性があるかどうかを検証する、言い換えればSOPを適用するべきNを見つける目的で分析が行われます。(まさにPF/CE/CNX/SOPの順番になる)
方針Bは、工学分野でロバストパラメータ設計と呼ばれている最適化手法です。具体的な解説は専門書(例えば[4])に譲りますが、NとXの交互作用(Interaction)に注目して「Nが変動しても結果がバラつかないようにXの最適値を探索」していきます。
ところで、筆者は「ブレインストーミングでアイデアを出し合って特性要因図を作成する」のようなネット記事を見たことがあるのですが、これは特性要因図の間違った使い方です。特性要因図は現状の知識を整理するためのツールなので、そこに取り上げられるアイデアは「事実である、あるいはエキスパートの経験に基づいており妥当性がある」との前提が必要です。(だから「ドメイン知識」です)
ブレインストーミングは事実であろうがなかろうがお構いなく、ある意味無責任かつ自由に発想してアイデアを出し合う手法なので、そこで出された様々なアイデアに妥当性は保証されません。仮にそれらのアイデアを特性要因図で整理すると、フィクションになってしまいます。(ブレインストーミングで自由発想されたアイデアを整理するには後述の親和図を使います)
要因に関するドメイン知識整理の方法 – マインドマップ
マインドマップは樹形図による思考の可視化を通して、「アイデアを整理する目的」「アイデアを創造する目的」の両方で使えるとされています。予測分析/要因分析において知識を整理する場合には、マインドマップの作り方は特性要因図と相違ありません。特性要因図を使い勝手よく綺麗に描くフリーソフトは世の中にあまりないようなので、PC画面を共有しながらチームで議論を行う場合などにはマインドマップを描くフリーソフトを使っていただくのもありでしょう。
「因果メカニズム」に関するドメイン知識を整理/見える化するための方法 〜 連関図法
最後に、これまた「新QC七つ道具」から、連関図をご紹介します。以前、「機械学習だけで因果関係を明らかにすることはできず、ドメイン知識の助けが必要」と別のブログ[6]に書きましたが、では「要因と問題(結果)の因果関係」や「要因同士の因果関係」に関するドメイン知識をどのように表現すれば良いでしょうか。
要因と結果(目的変数)との因果関係を表現する手法としては上述の特性要因図がポピュラーですが、特性要因図が想定している因果モデルでは下図4のように目的変数と要因との単層的な関係性を仮定しています。要因同士に関数関係がある(多重共線性)は考慮されますが、「他の要因の上流に位置していて目的変数に対して直接的な要因にはならない項目」は考慮されません。

一方、下図5「IC製造工程の分析例」[7]で要因「ゲート酸化膜厚」は別の要因「A特性の抵抗」や「Pチャネルの抵抗」の上流に位置付けられており、目的変数「Pチャネルの閾値電圧」の直接の要因とはなっていません。このように、要因同士にも多層的な因果関係がある、と考えられる場合には、特性要因図よりも連関図を使用してドメイン知識を整理するのが良いでしょう。

連関図のイメージを下図に示します。例えば要因Cause 5に向かって3つの要因Cause 11、Cause 12、Cause 13からの矢印が引かれているように、要因同士にも因果関係が認められるグラフ表示になっていることが連関図の特徴です。これは、大骨-中骨-小骨、と要因の整理のために階層を作る特性要因図とは違った表現です。

連関図を描画するときには、「なぜなぜ分析」が基本になります。まず、要因を深堀する対象となる問題(結果)を定義し(上図のProblem/Result)、下記ステップにしたがって作業を進めます。なお連関図法も、ドメイン知識を持った人達が集まったチームで行う作業となります。
- 問題(結果)を引き起こす直接の原因になっていると考えられる1次要因を考えます。ブレインストーミングではなく、事実あるいはエキスパートの経験に裏打ちされた項目にするのは特性要因図と同様で、最終的に5個以下の「本当に重要な1次要因」に絞り込んで表記します。(上図ではCause 1-4に該当)
- 次に、「なぜ1次要因が起こるのか」を考え、2次要因として項目と矢印を表記します。(上手ではCause 5-10に該当)
- さらに、「なぜ2次要因が起こるのか」を考えます。以下、同じように「なぜなぜ」を繰り返していきますが、一般的には4次要因くらいまで行ったら、さらにブレイクダウンして「なぜ」は考えられない場合が多いかもしれません。
- 前ステップまでで要因項目が出尽くしたら、次に要因同士の因果関係を発見してチャートに矢印を追加します。(上図ではCause 13がCause 2の要因になっている、と付け加えられています)
最後に主要因の特定作業をチームで行います。絞り込み方は様々ですが、例えば、他の要因から矢印が多く集中している要因や、2次要因以降に探索された要因(根本原因の可能性)などが選択されることが多いです。(上図では、Cause 2, 5, 14, 15 などが主要因の候補として浮かび上がりました)
AI分析における知識整理の重要性:まとめ
以上、皆様がAI分析(予測分析や要因分析)を始める前に既存の知識を全て棚卸して整理する方法や、予測精度に影響を与える要因についてのアイデアを創出してまとめるやり方の中でもポピュラーな手法をご紹介しました。
AIの会社のデータサイエンティストが書いたブログ記事としてはやや異色な内容だったかもしれませんが、AIを使って分析を行う場合でも、伝統的な統計解析を行う時と全く同様にドメイン知識をうまく利用して本質的な要因をモデルに取り込む必要があります。品質管理分野で長年使われているドメイン知識整理手法を皆様のAI分析プロジェクトでご利用いただくのに本稿が助けになれば幸いです。
(本ブログ記事は2020年5月に公開した内容に加筆・修正を加えたものになります)
参考文献
[1] 飯田修平(2018):「特性要因図作成の基礎知識と活用事例」, 日本規格協会
[2] 眞木和俊(2012):「図解 リーンシックスシグマ 」, ダイヤモンド社
[3] 山原雅人, 他(2018):「業務改革、見える化のための業務フローの描き方」, マイナビ出版
[4] 河村敏彦(2011):「ロバストパラメータ設計」, 日科技連出版社
[5] 猪原正守(2016):「JSQC選書26 新QC七つ道具 -混沌解明・未来洞察・バックキャスティング・挑戦問題の解決-」, 日本規格協会
[6] 伊地知晋平(2018):DataRobotブログ「機械学習を用いた要因分析 – 理論編 Part 1」
[7] 日本品質管理学会テクノメトリックス研究会(1999):「グラフィカルモデリングの実際」, 日科技連出版社