機械学習パーティショニングのまとめ
Part 2
– 適切なパーティショニングを選択するために –
はじめに
DataRobot でテレコム・鉄道分野のお客様を担当しているデータサイエンティストの佐藤です。
Part 1※に続き、本稿では各パーティショニングの手法を、手法詳細・利用シーン・メリット・デメリットの観点から考察していきます。(DataRobot Auto ML の「高度なオプション」に設定画面がある手法については画面も示します)
※パーティショニングとは何か?パーティショニングの重要性などに興味がある方は機械学習パーティショニングのまとめ Part 1をご参照ください。
パーティショニングの種類
マニュアルパーティション
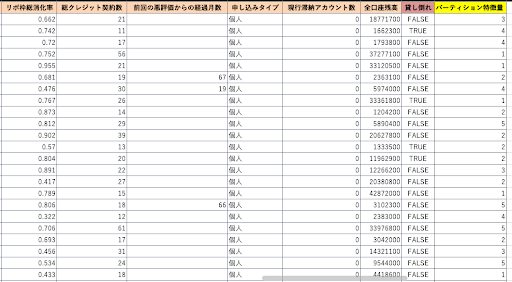
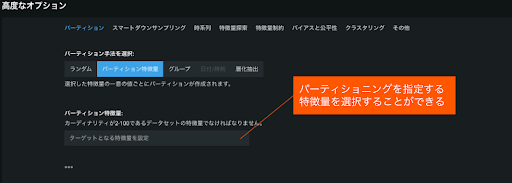
- 手法詳細
データにパーティショニングを指定する“パーティション特徴量“を追加し(上図1)、その値をベースにデータを分割する。
- 利用シーン
自身で各レコードごとにパーティションの設定をしたい場合に利用する。
- メリット
パーティション特徴量を利用することにより、自身で細かく検定データを指定してコントロールできる。
- デメリット
各レコードごとにどのパーティションに所属するかを検討する必要があるので、工数がとてもかかる。また、恣意的なパーティショニングが適応されるため、検討する材料として抜け漏れが発生する可能性がある。
ランダムパーティション(holdout法)
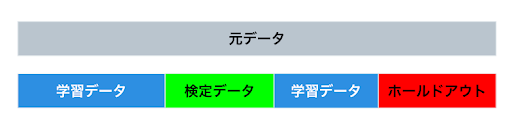
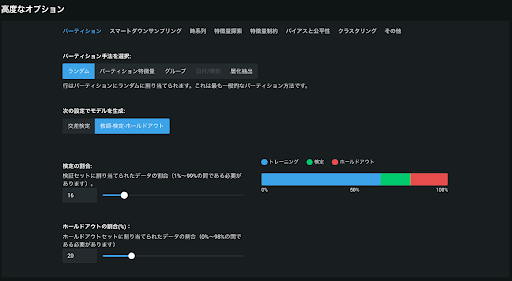
- 手法詳細
データを任意の一定割合でランダムに学習データと検定データに分割する。
- 利用シーン
データ量が多く、テストデータが学習データと同等の性質を持つと考えられる場合に利用する。
- メリット
純粋にランダムサンプリングを行うだけなので、計算量が少なく、計算時間が他のパーティショニングに比べ短い。
- デメリット
後述の k分割交差検定と比較すると検定データの量が1回分のみなので汎化性能を厳密に評価することができず、モデルの信頼性が低くなる可能性がある。
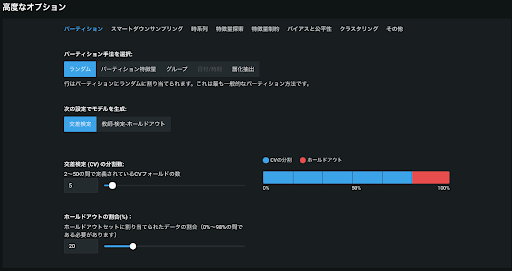
k分割交差検定(k-Fold)
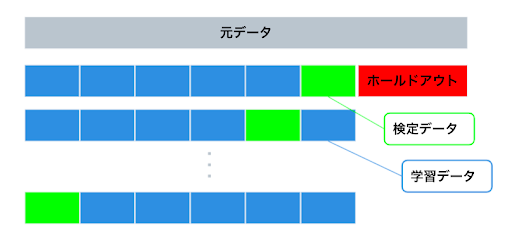
- 手法詳細
ホールドアウトを除いたデータをランダムサンプリングによって k 個の塊(Foldと呼ぶ)に分割し、Fold の一つを検定データ、残りの Fold を学習データとする。上図5のように、対象となる学習データと検定データを k 回組み替えてモデルの学習と検定を行う。
- メリット
全データで検定(バリデーション)を行うことができるので汎化性能が高くなり、信頼性が高くなる。各 Fold ごとのスコアから、データに偏りが発生しているか、発生しているとしたらどういう特徴があるかの Deep Dive がしやすい。
- デメリット
ランダムパーティションに比べて計算量が k 倍に増加するため時間がかかる。そのためデータ量が大きい場合には実装するのが現実的でない場合がある。(DataRobot Auto ML ではデータレコード総数がある閾値を超えると、一つの Fold での検定スコアが良くないモデルに対して自動で k分割交差検定を行わないようにしています)
Leave-one-out法
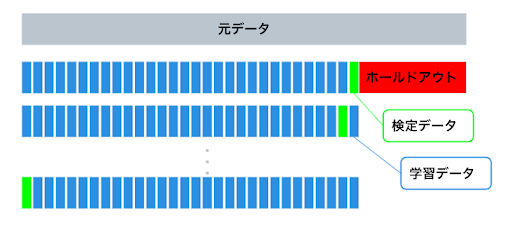
- 手法詳細
データの一つ(1行)を検定データとし、その他のデータを学習データとする。これをデータの総数分だけ、対象となる学習データ・検定データを組み替えてモデルの学習と検定を行う(k分割交差検定の k が行数分になったケース。DataRobot Auto ML では「高度なオプション」から k の値を変更することができます))
- 利用シーン
データ数が少なく、データ全体を有効活用する必要があるケースで利用する。
- メリット
データが少量であったとしても全てのデータを利用することができるので、学習用のデータ量が増加するほか、検定を細かく行えるので、汎化性能を高めることができる。
- デメリット
データ総量分だけ分割しているので、計算時間がk分割交差検定よりさらにかかる。
層化抽出法 + k分割交差検定(Stratified k-Fold)

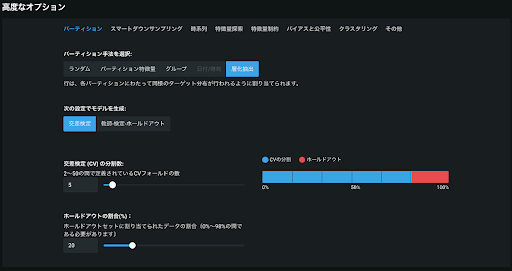
- 手法詳細
ホールドアウトを除いたデータを k 個の Fold に分割する際、Fold 内のカテゴリ分布(例:ポジティブクラスとネガティブクラスの割合)がなるべく一致するようにサンプリングを実施する。
- 利用シーン
分類問題のように、パーティション毎のカテゴリ分布が重要なケースにおいて一般的に利用する。
- メリット
ターゲットの比率が各 Fold で一定になるため、未知のデータも同様であるという仮定が成り立つのであれば良好な検定スキームになる。
- デメリット
データや課題の特性を考慮せずに層化抽出を行うとターゲットリーケージが発生したり、実は母集団と同一のカテゴリ分布ではなくてデータに偏りが発生する場合がある。
グループパーティション(Group k-Fold)
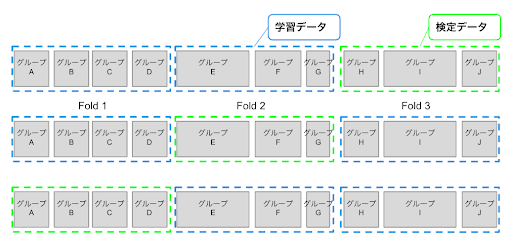
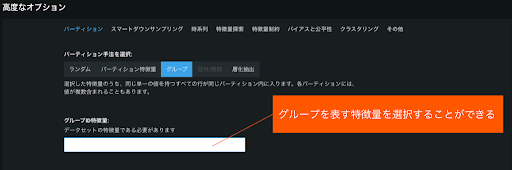
- 手法詳細
あるグループに属するデータが全て学習データや検定データの同一の Fold に含まれるように分割を行い、特定のグループに属するデータが学習データと検定データをまたがることがないようにする。
- 利用シーン
”同一人物が繰り返し出てくる場合”、”同じ製造ロット”や”同じ国”などデータ内に特有のグループが存在し、学習データに含まれない未知のグループに対して予測したい場合に利用する。
- メリット
k-Fold などで学習を実施する際に、ある特定の人物や製造ロットなどのグループを過学習したモデルができてしまうリスクがを低減されるので、予測時のターゲットリーケージを防ぐことができる。
- デメリット
k-Fold と同様に計算時間が多くかかる上、ドメイン知識がないとグルーピングする基準などの設定が少し難しい場合がある。また、グループ数が少ない場合は特定のグループの性質を過学習するリスクにも注意が必要になる。
日付/時刻パーティション
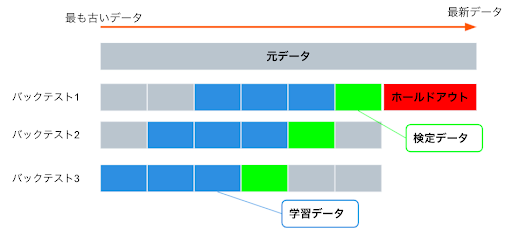
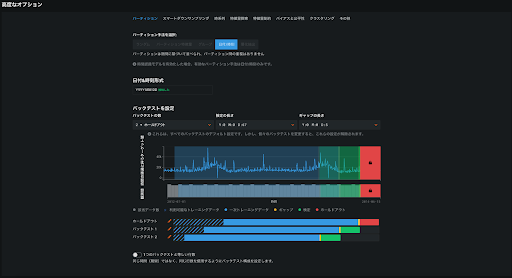
- 利用シーン
データが時系列性をもつ場合に利用する。(過去のある時点のデータと未来のある時点のデータ間が独立ではなく関係性があると認められる場合)
- メリット
データに時系列性がある場合にターゲットリーケージを防止できる。また、トレーニング期間や検定期間を設定することで必要以上に昔のデータなどを利用しないで学習を行うことができる。
- デメリット
検定データの量が減少したり、データを十分に使うことができなくなる場合がある。
発展的な手法
Adversarial Validation
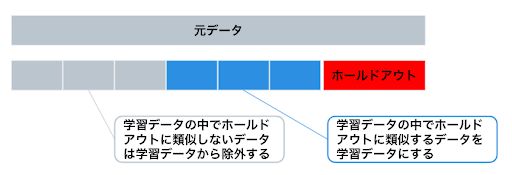
- 手法詳細
まず、ホールドアウトを除いたデータ(= 仮の学習データ)にFalse、ホールドアウトに True と2値フラグを立てて、それらを分類する2値分類モデルを作成する。仮の学習データの中でホールドアウトとうまく分類できないデータ、つまり、ホールドアウトに類似するデータを抽出し、次の予測モデル作成ステップで学習データとして使用する。
- 利用シーン
機械学習モデリングを実施する前の段階で、適切な学習データを抽出する目的で用いられる。すなわち、学習データとして使いたいデータの一部と将来予測を行いたい未知データ(ホールドアウトで近似)との間に分布的な偏りが存在すると考えられるときに利用する。
- メリット
ホールドアウトに対して学習データの偏りがなくなり、その学習データから作成したモデルで適切な予測ができるようになる。
- デメリット
ホールドアウトに対して学習データの分布を合わせるため、将来予測を行いたい未知データとホールドアウトが似ている、という仮定が成立していないと予測モデルの汎化性能が下がる可能性がある。また、学習データの量が少なくなるため、学習が十分にできない可能性がある。
Stratified Group k-Fold

- 手法詳細
層化抽出と Group k-Fold を合わせた手法。特定のグループに属するデータが全て一つの Fold に含まれるようにデータ分割を行なって学習データと検定データにまたがることがないようにしつつ、Fold 中に含まれているカテゴリー値の割合も同一にする層化抽出を行う。
- 利用シーン
グループ性を持ちつつ、分類問題で割合が重要なケースにおいて利用する。
- メリット
グループ性と分類問題の両方を考慮することができる。
- デメリット
Group k-Fold と同様に計算時間が多くかかる。また、層化抽出法と同様にデータが母集団と同一でないと偏りが発生する可能性がある。
Nested Cross Validation(Double Cross Validation)
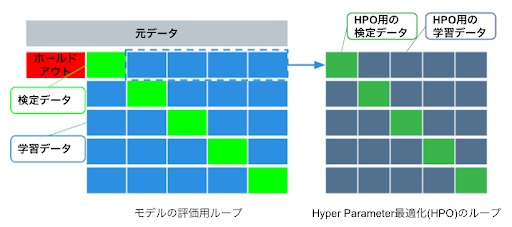
- 手法詳細
モデルのハイパーパラメーターチューニングとモデル評価で別々のパーティショニングを行なって、2重のループで交差検定を実施する。内側のループ(図16の右側)でハイパーパラメーターの最適化を行い、外側のループ(図16の左側)ではモデルの評価スコアリングを行う。外側のループにおける k-1個の Fold(学習データ)に属するデータを使って内側のループでの交差検定を行うため、外側のループで使用する検定データは決して内側のループの交差検定で使用されない。(DataRobot は多数のモデルを作成して評価するため、標準的に Nested CV を行なっています)
- 利用シーン
複数のモデルを作成した時に、公平にモデルを評価・比較する目的で利用する。
- メリット
ハイパーパラメーターのチューニングとモデル評価スコアリングで同一のデータが検定データに使われないようにしてオーバーフィッティングを回避するため、フェアに複数のモデルの精度パフォーマンスを評価できる。
- デメリット
外側ループの各k-1個の Fold 内で、ハイパーパラメーター最適化のためさらに交差検定が行われるため、より多くの計算時間がかかる。
まとめ
本稿では、Part 1・Part 2 を通してパーティショニングの重要性や各利用ケースにおけるパーティショニングの種類などを考察してきました。パーティショニングには様々な手法があり、それらの中からをデータの性質や分析目的に合わせて手法を適切に選択しなければ実業務で利用できるようなモデルを作成することはできません。
本稿で考察されているパーティショニングやその選択基準などが皆様にとって最適なパーティショニングを選択する上での一助となれば幸いです。
参考文献
Stratified Group Validation
https://www.kaggle.com/jakubwasikowski/stratified-group-k-fold-cross-validation
Nested Cross Validation
https://www.kaggle.com/c/data-science-bowl-2019/discussion/127469
https://machinelearningmastery.com/nested-cross-validation-for-machine-learning-with-python/
AI で迅速にビジネス価値向上を実現。今すぐ始めましょう。