ディープラーニングは万能なのか
はじめに
DataRobotのデータサイエンティスト、詹金(センキン)です。
AI(人工知能)技術が注目を集める昨今、ディープラーニング(深層学習)という言葉を聞かない日はないほどです。一方で、従来の機械学習との違いや詳細な適切な利用シーンはわからないという方も多いのではないでしょうか。
そこで本稿ではディープラーニングと AI、従来の機械学習との違い、Kaggle コンペティション優勝者が使ったモデルや実務で使うモデルに基づいて、どのような領域でディープラーニングが優れているか、優れてないかを紹介します。
ディープラーニングとAI、機械学習の違い
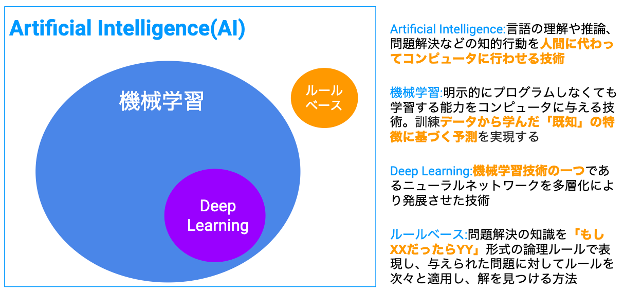
AI、機械学習、ディープラーニングの3つの関係を図にすると下図のようになります。最も広い意味で用いられるのが AI であり、機械学習は AI に内包される概念です。また、ディープラーニングは AI の一部であり、また機械学習の1種でもあります。ディープラーニング以外の機械学習としては勾配ブースティング、線形モデルなどが知られています。
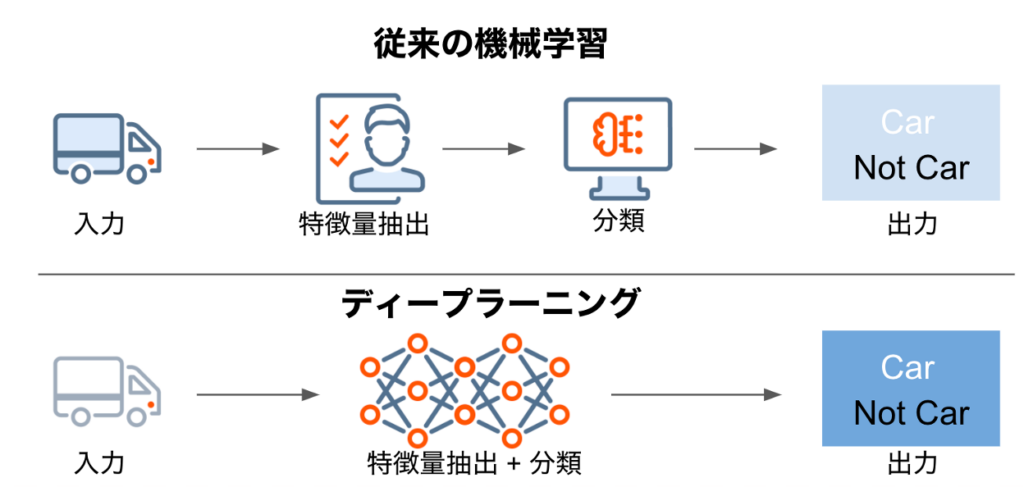
従来の機械学習は、人間のデータサイエンティストがマニュアルで特徴量を抽出することからスタートします。そして、抽出した特徴量を使って回帰・分類モデルを作成します。一方、ディープラーニングでは、特徴量抽出のステップはアルゴリズムの中に組み込まれているため、エンドツーエンドな学習を実行できます。つまり、ディープラーニングは生のデータと、回帰・分類など処理すべきタスクを与えられれば、自動的にその処理方法を学習することができるのです。
以下の図は「画像に車が写っているかどうか」問題を解く場合の、従来の機械学習とディープラーニングのそれぞれの仕組みを比較したものです。
ディープラーニングが優れている場合、そうでない場合:Kaggleでの結果を検証
機械学習のモデルの優劣を検証する上では、コンペティションは理想的な闘技場と言えるでしょう。Kaggle は、世界中のデータサイエンティストが機械学習モデルの精度を競うコンペティションサイトであり、企業や政府などの組織からお題と共に提供されたデータを元に、参加者が機械学習モデルの精度を競います。世界中の腕に覚えのあるデータサイエンティストが多数競い合った結果ですから、Kaggle で勝利をおさめたモデルはある意味ではその領域の最先端のモデルと言えます。
Kaggle で結果を残したモデルを分析するために、直近3年間のデータを収集しました。以下の図は、2017年からこれまでに終了した Kaggle コンペティションの一覧表です。この集計においては、賞金とポイントが付与される本格的な機械学習問題のみに絞り込んだ上で、リーケージや運要素に大きく左右された一部のコンペを除いています。
※画像レイアウトの制限により、記載していないコンペがあります

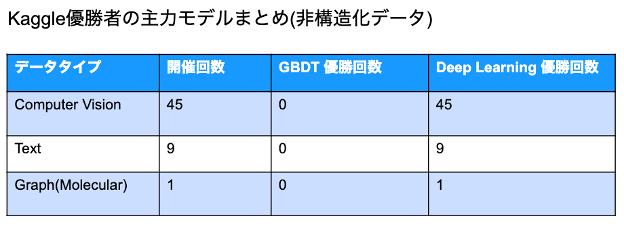
非構造化データの場合
分析した結果を見ると、非構造化データコンペ (画像、 ビデオ、テキスト、分子の化学構造式) の優勝者主力モデルはその全てがディープラーニングによるものであることがわかります。優勝者たちの解法は、手作業での特徴抽出は一切なしに、基本的には転移学習を利用しています。転移学習とは、ある領域で学習したことを別の領域に役立たせることで、効率的に学習させる方法です。同じ分野で十分に学習された学習済みモデルを利用することができれば、少ないデータ量かつ短い時間で学習可能となり、大変有用な手法です。これは具体的には学習済みの重み (画像では主にはImageNet、自然言語では BERT) を初期値として、 最先端のディープラーニングモデルを使ってコンペの新しいデータを学習するというものです。その他によく用いられる有効な手法としてはデータオーグメンテーション(データ水増し)、アンサンブル学習などが挙げられます。これらの新しい手法を用いることで、ディープラーニングが非構造化データにおいて非常に優れた結果を出すことができることは十分に証明されていると言えますが、多くの場合でディープラーニングはモデルの学習にかなりの長時間を要するため、試行錯誤のためには大量の計算リソース (GPU、TPU) が必要となり、最近のコンペではそのような大量の計算リソースを使える環境にいるかどうかが勝負の明暗を分けることもしばしばあります。
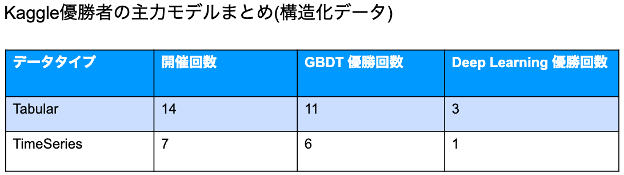
構造化データの場合
構造化データコンペ (テーブル、時系列) の優勝者の主力モデルは勾配ブースティングが圧倒的に多数を占めています。優勝者たちの解法は、基本的には特徴量エンジニアリングを中心に取り組まれており、また特に時系列課題において検定手法の選び方について慎重に検討がなされています。アンサンブル学習も多くの場合で有効です。これらの中にもディープラーニングが優勝したコンペが4件あります。アメフトの運動データ (座標、速度…)1件、金融系匿名データコンペ2件、WikiTraffic 時系列データ1件の計4件ですが、これらに共通する特徴としては、データセットに含まれる変数があまり豊富でなく、かつ特に匿名データである場合、人間のドメイン知識を活用することが難しかったという点が挙げられます。そのため、手作業で抽出した特徴より、ニューラルネットワークによる自動的な特徴抽出がより有効だったのではないかと考えられます。
半構造化データの場合
ここではシグナル (音声、地震波、電流) とマルチモーダル(画像、自然言語、数値データを含む) を半構造化データと定義してまとめて取り上げたいと思います。優勝者たちの解法を見ると、ディープラーニングと勾配ブースティングのいずれでも良い精度を達成できており、その差は僅かということがわかります。このようなデータにおいては手作業での特徴抽出が効果を発揮する部分もありますし、ニューラルネットワークによる自動的な特徴抽出が有効な部分もあったのだろうと考えられます。
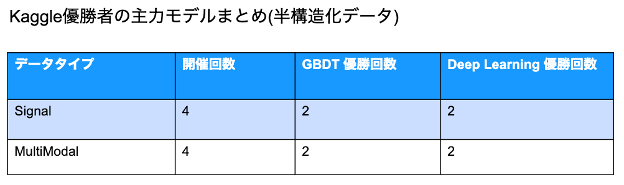
実務で使うモデル
現在ディープラーニングが最も活躍している分野、例えば顔認識、医療画像診断、音声アシスタント、機械翻訳などでは、従来の機械学習モデルの精度より、遥かに優れたパフォーマンスを実現可能です。これらについては従来の機械学習モデルの精度では実用に足る精度を達成することは困難な課題ですので、ディープラーニングを使うべきであるケースが多いでしょう。
一方で、与信審査、不正検知などのテーブルデータ、需要予測などの時系列データでは、十分データが存在する際には多くの場合で勾配ブースティングや非線形カーネルを用いたSVMなどの非線形なモデルで高い精度のモデルを構築可能です。また、データが少ない際にはシンプルな回帰モデルなどの方が精度の良いこともよくあることです。
筆者はこの3年間で約20のKaggleコンペティションに参加しており、その過程で身につけた機械学習スキルは実務においても非常に役に立っています。ただし、Kaggle ではコスト(時間、サーバ代)とモデルの説明性ともに一般にはあまり重視されずに、精度のみが追求されることが多いかと思います。しかしながら、実務の機械学習プロジェクトにおいては、精度以外にもコスト面や説明性が当然のこととして求められるなどコンペとは異なる部分も多いのが現実です。
例えば、音声データの解析をする場合、Kaggle であれば一般的なアプローチは GPU/TPU に裏付けられた高度なディープラーニング技術を惜しみなく投入して、かつ試行錯誤にも時間的制約を加えることなく検討を尽くすというものになるでしょう。しかし、実は弊社ブログでもご紹介した Python ライブラリの librosa で MFCC (メル周波数ケプストラム係数) 特徴量を抽出して、勾配ブースティングを用いる比較的シンプルなアプローチでも多くの場合で十分な良い精度を得ることができます。ディープラーニングの精度に及ばないとしても、低コストで実用レベルの精度を実現できるのです。もう一つの事例はデジタル広告会社がよく使うクリック率予測(CTR)モデルです。大規模なデータに対して、ディープラーニングや勾配ブースティングを用いることで高い精度を得られますが、このアプローチはコストが非常に高くつきます。実はシンプルなロジスティック回帰でもその精度は実用レベルを達成可能であり、かつ非常に低コストで済むのです。このように多くの企業ではコストパーフォマンスの良いソリューションが採用されています。
精度、コスト以外ではモデルの説明性についても近年ますます重視されています。特に銀行、保険、医療といった規制の厳しい業界では、規制や業界のベストプラクティスを遵守するためには、導き出される結果に貢献した要因を理解できることが大変重要です。説明しやすい線形相関特徴量と線形モデルがこの目的でよく使われます。
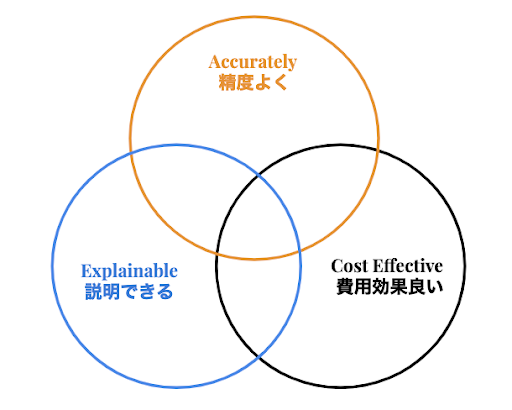
モデルの精度、コスト、説明性は、基本的に、トレードオフの関係にあります。それらを、いかに高い位置でバランスさせるかが、ビジネス価値向上へとつながります。
DataRobotにおける深層学習
DataRobot においても最近リリースしたバージョン6.0において、Visual AI の提供を開始しており、ディープラーニングへの対応を更に加速しています。この Visual AI は画像データを用いたモデリングを自動化することができる画期的な新機能です。通常、画像を特徴量として扱うにはディープラーニングに関する専門知識と技術が求められます。大量の学習データと計算リソースも必要で、とても誰もができることではありませんでした。DataRobot では Visual AI により画像の特徴量化が自動化されているため、誰でも簡単に何度でも、数値やテキストなどと画像を組み合わせたマルチモーダルなモデリングを実現できます。
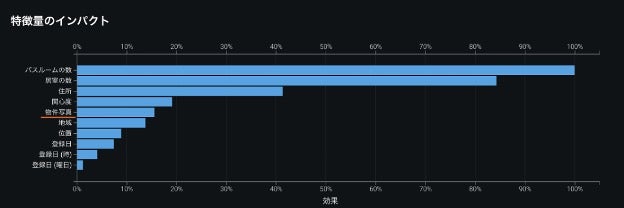
画像データを用いる場合でも、 DataRobot の従来の仕組みに完全に統合されているため、これまでとまったく同じ操作で同じように分析ができます。以下の例では、物件写真が物件価格の予測に与えるインパクトを他の特徴量と比べており、物件写真のインパクトは最大ではないものの、重要な特徴量の一つであることがわかります。
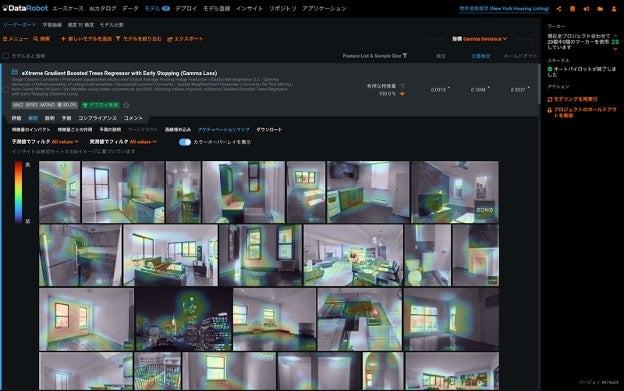
また、画像を用いてただ精度が上がったというだけでは不十分で、実際に運用するには「AI の説明性」も求められます。Visual AI では画像特徴量の性質を説明するインサイト機能も提供されており、画像と予測との関係が人間の経験や知識と照らし合わせて納得のいくものであるか確認することができます。例えば下図では、物件写真のどの部分に着目して物件価格を予測しているかがわかります。これが人間の着目する箇所と類似していれば、そのモデルの信頼性も高まるでしょう。
まとめ
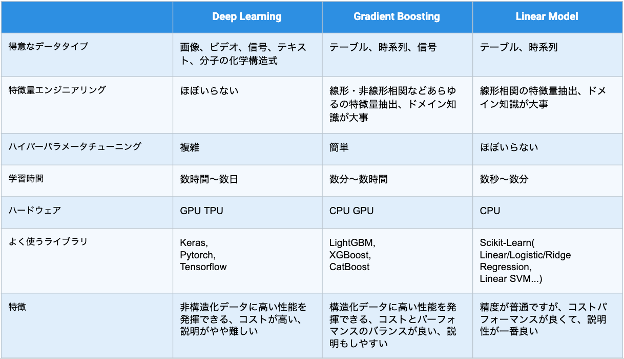
ここまで Kaggle コンペティションと産業界の事例に基づいて、ディープラーニングの優れているところ、優れてないところについて説明をしてきました。AI についても「適材適所」で使い分けていく必要があります。また、AI においては、精度、コスト、説明性を高い位置でバランスすることが重要です。DataRobot Visual AI ではこれらを高度に満たしつつ、誰でも、簡単に、短時間でディープラーニングをご活用頂けますので、是非ご活用頂ければと思います。最後にディープラーニングと勾配ブースティング、線形モデルについて様々な角度から比較した表を作りましたので参考にして頂けますと幸いです。
参考Kaggleコンペ
- https://www.kaggle.com/c/bengaliai-cv19
- https://www.kaggle.com/c/deepfake-detection-challenge
- https://www.kaggle.com/c/google-quest-challenge
- https://www.kaggle.com/c/tensorflow2-question-answering
- https://www.kaggle.com/c/data-science-bowl-2019
- https://www.kaggle.com/c/pku-autonomous-driving
- https://www.kaggle.com/c/nfl-big-data-bowl-2020
- https://www.kaggle.com/c/rsna-intracranial-hemorrhage-detection
- https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles
- https://www.kaggle.com/c/understanding_cloud_organization
- https://www.kaggle.com/c/severstal-steel-defect-detection
- https://www.kaggle.com/c/ieee-fraud-detection
- https://www.kaggle.com/c/open-images-2019-instance-segmentation
- https://www.kaggle.com/c/generative-dog-images
- https://www.kaggle.com/c/aptos2019-blindness-detection
- https://www.kaggle.com/c/recursion-cellular-image-classification
- https://www.kaggle.com/c/youtube8m-2019
- https://www.kaggle.com/c/siim-acr-pneumothorax-segmentation
- https://www.kaggle.com/c/open-images-2019-object-detection
- https://www.kaggle.com/c/open-images-2019-visual-relationship
- https://www.kaggle.com/c/champs-scalar-coupling
- https://www.kaggle.com/c/instant-gratification
- https://www.kaggle.com/c/imaterialist-fashion-2019-FGVC6
- https://www.kaggle.com/c/landmark-recognition-2019
- https://www.kaggle.com/c/landmark-retrieval-2019
- https://www.kaggle.com/c/freesound-audio-tagging-2019
- https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification
- https://www.kaggle.com/c/imet-2019-fgvc6
- https://www.kaggle.com/c/santander-customer-transaction-prediction
- https://www.kaggle.com/c/gendered-pronoun-resolution
- https://www.kaggle.com/c/LANL-Earthquake-Prediction
- https://www.kaggle.com/c/petfinder-adoption-prediction
- https://www.kaggle.com/c/vsb-power-line-fault-detection
- https://www.kaggle.com/c/humpback-whale-identification
- https://www.kaggle.com/c/elo-merchant-category-recommendation
- https://www.kaggle.com/c/quora-insincere-questions-classification
- https://www.kaggle.com/c/human-protein-atlas-image-classification
- https://www.kaggle.com/c/PLAsTiCC-2018
- https://www.kaggle.com/c/quickdraw-doodle-recognition
- https://www.kaggle.com/c/ga-customer-revenue-prediction
- https://www.kaggle.com/c/inclusive-images-challenge/overview
- https://www.kaggle.com/c/rsna-pneumonia-detection-challenge
- https://www.kaggle.com/c/airbus-ship-detection
- https://www.kaggle.com/c/tgs-salt-identification-challenge
- https://www.kaggle.com/c/google-ai-open-images-visual-relationship-track
- https://www.kaggle.com/c/google-ai-open-images-object-detection-track
- https://www.kaggle.com/c/youtube8m-2018
- https://www.kaggle.com/c/home-credit-default-risk
- https://www.kaggle.com/c/avito-demand-prediction
- https://www.kaggle.com/c/talkingdata-adtracking-fraud-detection
- https://www.kaggle.com/c/landmark-retrieval-challenge
- https://www.kaggle.com/c/landmark-recognition-challenge
- https://www.kaggle.com/c/data-science-bowl-2018
- https://www.kaggle.com/c/sp-society-camera-model-identification
- https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
- https://www.kaggle.com/c/recruit-restaurant-visitor-forecasting
- https://www.kaggle.com/c/mercari-price-suggestion-challenge
- https://www.kaggle.com/c/tensorflow-speech-recognition-challenge
- https://www.kaggle.com/c/statoil-iceberg-classifier-challenge
- https://www.kaggle.com/c/favorita-grocery-sales-forecasting
- https://www.kaggle.com/c/porto-seguro-safe-driver-prediction
- https://www.kaggle.com/c/cdiscount-image-classification-challenge
- https://www.kaggle.com/c/text-normalization-challenge-russian-language
- https://www.kaggle.com/c/text-normalization-challenge-english-language
- https://www.kaggle.com/c/carvana-image-masking-challenge
- https://www.kaggle.com/c/web-traffic-time-series-forecasting
- https://www.kaggle.com/c/nips-2017-defense-against-adversarial-attack
- https://www.kaggle.com/c/nips-2017-targeted-adversarial-attack
- https://www.kaggle.com/c/nips-2017-non-targeted-adversarial-attack
- https://www.kaggle.com/c/passenger-screening-algorithm-challenge
- https://www.kaggle.com/c/zillow-prize-1
- https://www.kaggle.com/c/instacart-market-basket-analysis
- https://www.kaggle.com/c/sberbank-russian-housing-market
- https://www.kaggle.com/c/planet-understanding-the-amazon-from-space
- https://www.kaggle.com/c/noaa-fisheries-steller-sea-lion-population-count
- https://www.kaggle.com/c/quora-question-pairs
- https://www.kaggle.com/c/intel-mobileodt-cervical-cancer-screening
- https://www.kaggle.com/c/youtube8m
- https://www.kaggle.com/c/two-sigma-connect-rental-listing-inquiries
- https://www.kaggle.com/c/data-science-bowl-2017
- https://www.kaggle.com/c/two-sigma-financial-modeling