データドリブンと AI 活用
– 品質改善活動の深化を例に –
はじめに
DataRobot でヘルスケア分野のお客様を担当しているデータサイエンティストの伊地知です。最近、ネット記事などで『データドリブン(Data Driven)』『データドリブン企業』なる言葉を見る機会が増えたように思います。一方、筆者が’90年代に製造業系の企業で全社的品質改善活動に携わっていた頃を思い出してみると、当時から、データドリブンという言葉は存在していました。では、データドリブンの本質は企業での AI 活用が進みつつある現在において、以前から変容したのでしょうか?
本稿では、『品質改善活動』の切り口からデータドリブンの本質とは何かを考察し、さらに、企業がデータドリブン組織として成功するためには何がポイントになるのかを考えてみます。
データドリブンとは?
最近データドリブンについて解説している記事をいくつか読んでみたのですが、多くの著者が「ビジネスにおいて様々なデータや事実に基づいて判断(意思決定)・アクションを行う」ことをデータドリブンと表現しているように感じました。このように書くと特に目新しさはない概念にも見えますが、2010年代以降のビッグデータ時代の到来と GAFA の台頭、そして昨今のデジタルトランスフォーメーション(DX)という IT 業界がリードするトレンドの文脈中で改めて脚光を浴び、再定義されているのかもしれません。
ベストセラーとなった書籍『統計学が最強の学問である(ダイヤモンド社)』の著者である統計学者の西内啓氏が「日本はデータ分析でとても儲けた国である」とある講演でおっしゃっていたのですが、具体的には高度経済成長期に製造業が中心となって品質管理活動を体系的に導入し、高品質の製品を低コストで大量に製造・販売することで成長したからとのご指摘で、氏の主張には個人的に非常に共感するものがありました。例えば、小集団(QC サークル)による品質管理・品質改善活動のために導入されたツール群『QC7つ道具(チェックシート、グラフ、ヒストグラム、パレート図、散布図、特性要因図、管理図)』はまさにデータと事実を可視化して意思決定に役立てるための手法と言えます。(特に「アクションする/しないを決めるための閾値」を管理限界線(Control Limit)として良不良の判定を行うためのスペックなどとは別に設定する『管理図(Control Chart)』の考え方は、データから意思決定を行うことの本質を示す好例と思います)
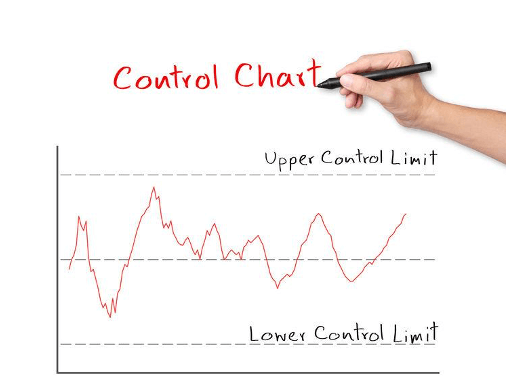
筆者(伊地知)はある製造業の会社で Six Sigma と呼ばれる全社的な品質改善活動を推進する役割を担っていた経験があるのですが、その頃(’90年代後半)社内では『データドリブン』あるいは『データと事実による意思決定』というような言葉が確かに使われていました。その頃の『データドリブン』と現在の『データドリブン』では何か違いがあるのでしょうか?本質的に何かが変わったのでしょうか?
もちろん’90年代と比べて現在ではデジタル技術が格段に進歩しており、例えば顧客の購買履歴データのようなトランザクションデータがデジタル化されて大量に蓄積されるようになっています。(筆者が’90年代後半に間接業務プロセスの改善プロジェクトに関わったケースでは、例えば営業プロセスデータの多くがデジタル化されていなくて、エクセルのデータテーブルを作成するのに手入力で結構な時間をかけたりしていました)
また、ハードウエアには様々なセンサーが取り付けられて、大量のセンサーデータがものづくりの現場から、あるいは稼働中の製品から吸い上げられるようになってきています。センサーの小型化・低コスト化によりデータを安価に収集・蓄積できるようになったことと、コンピュータの処理能力が格段に向上したことが、2010年代からの第3次AIブームを牽引する大きな原動力になっていることはご承知の通りです。
それらのデータを活用するための方法論に注目すると、20世紀前半にフィッシャーらによって確立された推測統計の体系は品質管理の分野で大きな力を発揮し、科学的な意思決定アプローチとして産業界に定着しました。一方、『次元の呪い』のように、高次元ビッグデータを分析する際には推測統計のスキームだけでは歯が立たないケースが存在するものの、『データの中に隠れているパターンを発見してモデル化し、そのモデルを使って意思決定を助ける』という基本的なアプローチは20世紀の統計学者にとっても AI 時代のデータサイエンティストにとっても、本質的には全く変っていないのではないかと筆者は考えています。
全社的品質改善活動に見る『データドリブン』成功の秘訣
さて、それでは筆者が全社的品質改善活動の一つである『Six Sigma』に関わっていた頃の経験を思い出しながら、データドリブンを成功に導くカルチャーを組織に浸透・定着させるための要点を考察してみます。
当時、筆者の在籍企業内では明確に「データを分析した結果を利用して『根拠に基づく意思決定』を行うことが Six Sigma の本質である」と品質改善プロジェクトを推進するリーダー達に教えていました。つまり、まさにデータドリブン企業になることを目標に掲げて Six Sigma が推進されていたと言えます。
その企業での Six Sigma 活動には以下のような特徴がありました。
- ビジネスインパクトの明らかな業務改善課題を定義する:年間500万円以上の利益(またはコストダウン)を生むと見積もられたテーマが採用されていました。
- テーマを始める場合にはトップの承認が必要:定義された課題の出自はボトムアップ/トップダウン両方あったが、採用前に経営層が承認するプロセスが取られていました。
- テーマ推進者(Six Sigma ではブラックベルトと呼ばれる)は100%専任で、しかもその部門のトップパフォーマーをアサイン:CEO からの強い指示があり、各部門のリーダーはその指示に従いました。
- その会社で幹部になるには、ブラックベルトとして Six Sigma を推進した経験が必要、との人事方針導入:ブラックベルト卒業生には実際にビジネスリーダーとして大きなチャンスが与えられました。
- ROI の明確化とコミット:品質改善テーマから生み出された利益は経理部門が厳正にチェックし、実際に利益の総額がアニュアルレポートに記載され、株主に報告されていました。
上記はあくまである一企業で実践された例に過ぎず、その会社の企業風土に合わせて作られたフレームワークであったと言えるでしょう。(複数の Six Sigma 導入企業におけるフレームワークについてご興味のある方は、書籍『TQM・シックスシグマのエッセンス』(日科技連)を参照ください)
しかしながら、現在でも通用する「データドリブン企業として成功するために重要なポイント」が網羅されていたのではないかと筆者は感じています。それらのポイントを一般的な表現に改めると次の3点に集約できます。
- プロジェクトテーマの『定義』
- ビジネスインパクトの大きい業務改善課題を事前に明確にしているか?
- 経営層もテーマをレビューし、スポンサーとして承認しているか?
- プロジェクトリソースの確保(量・質とも)
- 経営層はプロジェクト推進者に部門のトップパフォーマーをアサインしているか?
- 分析プロジェクト推進者が正当に評価され、最も魅力的なキャリアパスとして認知されているか?
- 経営層の強いコミットメント
- データ分析に基づく改善活動は重要な経営戦略と位置付けられ、その活動の成果は社外のステークホルダーにも発信されているか?
上記は経営層の積極的な関与と責任をとる姿勢が極めて重大であることを示唆しているように思われます。『データドリブン』は重要な経営戦略であり、その推進には経営層のコミットメントが必要であるという当たり前の話ですが、この当たり前、がなかなか実現できず、『データドリブン』が定着していない企業は実は多いのではないでしょうか。
AI導入を成功/失敗させるには?
前章で『実は多いのではないだろうか』と申し上げた理由は、AI 技術を導入した企業の中で、本当に AI モデルが業務実装されて成果を生み出している企業の割合が極めて低いと思われるからです。AI を継続的に運用してビジネス成果を出し続けている企業は AI 導入企業の1%に過ぎないとの報告もあります。
筆者が DataRobot 社のデータサイエンティストとして様々な企業をご支援させていただいている経験から申し上げると、データドリブン企業であることは、AI 導入を成功させるための必要条件であると思われます。
ただし、データをデジタル化して集められているとか、データ基盤が整っているとか、分析ツールを全社導入した、というだけでは(それらが重要なピースであることに疑う余地はないものの)前章で考察した3つの要件を高いレベルで満たすことはできません。実際に、データ基盤や分析ツールを導入したにも関わらずデータドリブン企業に成り切れず、故に AI 導入が進まない、という悩みを抱えている企業が存在している事実があります。
筆者の見る限り、AI プロジェクトを社内で始めてみたものの「トライアル」「PoC」のフェーズをいつまでも抜け出せずビジネス成果に結び付けられていない企業には、下記のような課題を抱えているケースが多いと感じています。これらはまさに前章で考察した『データドリブン企業として成功するための3要件』を満たしていないケースとも解釈できます。
- 適切な業務課題を定義できていない・データがない
- 経営層はテーマ設定を現場任せにしている。
- 現場から上がってくるアドホックな分析テーマでスタートする。
- その業務課題が解決するとどの程度のビジネスインパクトが生まれるかの見積もりが曖昧か、あるいは計算ロジックが弱いまま AI プロジェクトを開始する。
- AI モデルを作成したらそれをどのように業務プロセスに実装して運用するのか、検討が無いまま AI プロジェクトを開始する。
- データはあるが、いざ利用しようとすると様々な課題(社内承認など)が判明し、AI プロジェクトをいつまでたっても始められない。
- プロジェクトリソースが確保されていない
- 現場の人が興味本位で試しに予測分析を始めてみるが、『本業』が忙しくなるとすぐ止めてしまう。(『自由研究系』テーマ)
- データ分析の心得のある人が機械学習モデリングを行ってみるが、コア業務としてアサインされているわけではなく業績評価にも直結していないので『本業』が忙しくなると止めてしまう。
- 深いドメイン知識を持つ部署のトップパフォーマーは予測分析業務から距離を置いており、極端なケースでは抵抗勢力になっている。
- AI導入の成果を経営層にアピールして認めてもらうようなアクションをチャンピオンがとっておらず、分析担当者になることが良いキャリアパスであると社内で認知されていない。
- 経営層がコミットしていない
- AI 導入やデータサイエンティスト育成自体が目的になっており、ビジネス成果を定量的に算出しようという意向が経営層にも希薄か、現場任せにしている。
- 『データと事実を元に意思決定を行う』が経営戦略として徹底されていない。
ここで「予測分析」を「要因分析」、「AI モデル」を「統計モデル」、「AI プロジェクト」を「品質改善プロジェクト」に置き換えると、実は筆者が’90年代 TQM(Total Quality Management)やSQC(Statistical Quality Control)を勉強した時に学んだ『改善活動を阻む問題点』と上記課題の多くが本質的には同じ内容だと気付きます。つまり、『データドリブン企業』になるための要件は昔から大きくは変わっておらず、普遍的なのではないかと考えられます。
上記課題とは逆に、もし皆さんの所属企業が3要件(テーマ定義、リソース確保、経営層のコミット)を理解している経営層のもと、COE(Centor of Excellence)チームが戦略的な経営課題としてデータドリブン活動を進めているならば、AI時代においての勝ち組になるための必要条件を満たしていると言えるでしょう。
問題解決方法論とデータドリブン
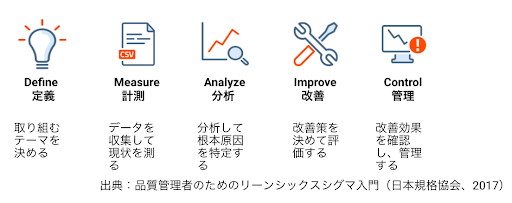
Six Sigma/TQM など全社的な品質改善活動を導入した企業では、DMAIC(上図2)、PPDAC、CRISP-DMなど『事実とデータに基づく科学的な課題解決方法論に則ったプロジェクト活動』が推進されます。筆者がかつて所属した企業で Six Sigma を推進していたときには全社員を対象とした集合研修が行われていましたが、その中では統計ツールの使い方を教えるのと同等かむしろそれ以上のウェイトを置いて、課題解決方法論(DMAIC)について解説し、DMAIC に忠実にプロジェクトを進めることが重要と教えていました。
このような、『方法論の徹底』によって生まれた成果の一つは、現場から上級管理職まであらゆるスタッフが自分の関わる業務の改善を同じやり方で効果的に進めることができるようなった点でした。Six Sigma のDMAIC(Define, Measure, Analyze, Improve, Control)を例に挙げれば、筆者が当時所属していた企業では特に Define フェーズが大事だと口を酸っぱくしてプロジェクトリーダー(ブラックベルト)達に話していました。
GE 出身の眞木和俊氏他による著書『品質管理者のためのリーンシックスシグマ入門(日本規格協会)』によれば、Six Sigma 課題解決方法論はモトローラ社が開発した当初は MAIC でしたが、これを GE 社が’98年に『Define』を加えて DMAIC 方法論として展開したところ、プロジェクトの成功率が大幅に上がり、大きな利益が生まれるようになった、とのことです。
筆者(伊地知)の当時の所属企業でも、プロジェクトチャーターテンプレートを使って、Six Sigma プロジェクトの定義をしっかり行い、その内容をチャンピオンが承認して初めてプロジェクトを開始できるルールで運用していました。(このように、プロジェクト定義を厳密に実施し、経営層の承認を以てプロジェクトを進めることがデータドリブン企業の必須要件であることは先に記述した通りです)
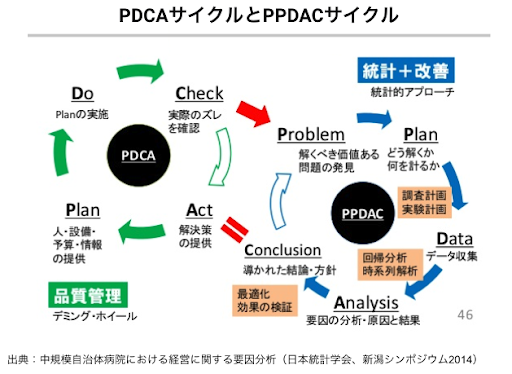
データ分析プロジェクトを進めるための方法論として開発された PPDAC サイクル(下図3の右側)においても、サイクルは『Problem(解くべき価値ある問題の発見)』からスタートしていることが分かります。
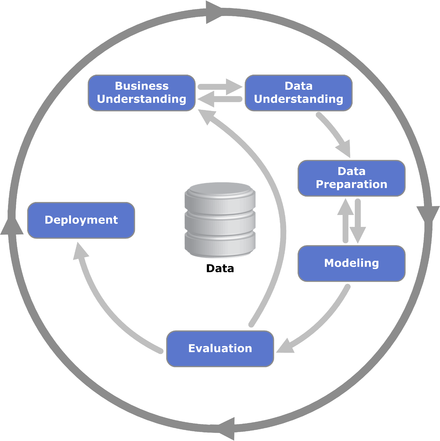
さらに例を挙げると、データ分析プロジェクトを進めるための方法論として開発された CRISP-DM(CRoss Industry Standard Process for Data Mining、下図4)においても、サイクルは『Business Understanding』からスタートしています。
以上、問題解決方法論の起点が『テーマ(プロジェクト)の定義』となっていて、非常に重要なステップであることを申し上げましたが、テーマ(プロジェクト)の定義が大事なのは、AI を利用した予測分析においても全く変わりません。そのため、例えば DataRobot 社では『テーマ定義シート』なるテンプレートを使って、顧客企業が本当にビジネスインパクトを生む AI プロジェクトを定義できるように支援しています。
テーマ定義シートは5つの観点『業務課題』『データ』『人』『モデル運用』『ROI』から予測分析テーマをレビューできるように構成されています。お客様自らがこのシートに記入していくことで、そのテーマ候補を本当に行うかどうかを判断するための情報が明確になります。
- 業務課題: AI/機械学習テーマとして成立する課題か
- データ: データを準備できるか、そのデータにAI/機械学習を適用するべきか
- 人: 業務として分析担当者をアサインできるか
- モデル運用: 予測モデルを業務プロセスに実装して活用するイメージが明確か
- ROI: 予測分析プロジェクトを進めるために行う投資を短期に回収できるか
データドリブン企業での AI/機械学習の位置付け
データドリブン企業として全社的品質改善活動を推進してきた実績があり、データ分析リテラシーの高いスタッフが在籍する企業をご支援していると、しばしば「これまで行ってきた統計解析をAI/機械学習で置き換えられますか」というニュアンスのご質問をいただくことがあります。こうしたご質問に対しての筆者の回答は決まっていて、「探索的データ解析(EDA)と呼ばれる1〜2変数での分析やグラフ分析は機械学習を使った分析を行う前に必ずやっていただくことをお勧めします」と申し上げています。
書籍『TQM・シックスシグマのエッセンス(日科技連)』に記述がありますが、実は Six Sigma の DMAIC 方法論でも、以下のようにフェーズ毎に分析手法を使い分ける構成となっていて、例えば応答曲面法による統計モデル作成などを行うより前に、基本的な探索的データ解析やグラフ分析が必ず行われます。
Define :グラフなど
Measure :ヒストグラム、時系列グラフ、層別、測定システム分析
Analyze :相関分析、回帰分析(単回帰、重回帰)、統計的検定・推定、分散分析
Improve :実験計画法、応答曲面法、Taguchi Method
Control :管理図、ポカヨケ、FMEA/FTA
以上のように、AI/機械学習による予測分析プロジェクトでも、より一般的なデータ分析プロジェクトでも、分析プロセスのフェーズ毎に分析目的に沿った手法を適切に選択して分析を行う、が正解だと言えます。そして、「今このフェーズでこのデータに対して、この分析目的のために使うべき分析手法は何か」という『分析手法選択の目利き能力』が分析担当者には求められます。
なお、予測分析に機械学習技術を使う場合、手元のデータの分析にどの機械学習アルゴリズムを適用するのがベストなのかを理論的には決められないため、多くのアルゴリズムを使って自動で多数のモデルを作成して比較する DataRobot の機械学習自動化技術が効力を発揮します。
まとめ
最後に、本稿で考察した項目を箇条書きでまとめてみます。皆さんのご所属されている企業が『データドリブン企業』となって AI でビジネス成果を創出するには何が必要なのか、をお考えいただくためのヒントになれば幸いです。
- データと事実に基づく意思決定・アクションがデータドリブンの本質であり、品質管理分野では昔から推進されてきた
- データドリブンは重要な経営戦略であり、経営層のコミットなくして推進できない
- データドリブン企業であることは、AI 導入を成功させるための必要条件である
- 分析ツールを使いこなすのと同等かそれ以上に、プロジェクト推進者&分析担当者が課題解決方法論に忠実に進めるかどうかがデータドリブンの鍵の一つであり、AI でビジネス成果を出すためにも重要である
- 良いテーマ(業務課題)を定義できるかどうかがデータドリブンの鍵の一つであり、AIで成果を出すためにも決定的に重要である
- 既存の手法を高度な分析手法で置き換える、という発想ではなく、分析者は都度適切な分析手法を選択して使うのが良い
参考文献
眞木和俊ほか(2017):「品質管理者のためのリーンシックスシグマ入門」, 日本規格協会
Shearer C., The CRISP-DM model: the new blueprint for data mining, J Data Warehousing (2000); 5:13—22.
総務省統計局 Data StaRt ホームページ(2019):「PPDACサイクルとは?」
山田秀ほか(2004):「TQM・シックスシグマのエッセンス」, 日科技連