Kaggle スキルのビジネス活用
はじめに
DataRobot のデータサイエンティスト、詹金(センキン)です。
近年機械学習の急速な進歩によって、AI 導入の技術面のハードルも下がり始めていることから、様々な企業が積極的に機械学習の活用を始めています。企業側は、機械学習モデルの精度を重視する一方で、コスト削減も重視しており、そのいずれもが重要です。もちろん妥協点を見出すことは一定程度必要となりますが、単純に妥協するのではなく、そのトレードオフの中で最適解を見出していくことこそが最大のビジネス価値を生み出すための重要なポイントです。
本稿では DataRobot のお客様の課題を解決する過程で実際に Kaggle で学んだ技術を活用して、高精度と低コストを同時に実現することができた事例を紹介します。
精度とコスト両立の最善策
筆者は DataRobot のデータサイエンティストとして、お客様のビジネス価値向上のため、チームメンバーと協働して様々なプロジェクトに携わってきましたが、当然のことながらその中では構築したモデルの精度以外にもビジネス指標、コスト、解釈性、継続運用適性などを考える必要がありました。そして、最終的には顧客ビジネスに成功を提供できるかどうかで評価がなされます。
一方、私が趣味として長年に渡って参加してきた Kaggle コンペティションでは、基本的にはデータ、評価指標が初めから揃えられていますので、基本的には精度向上にのみ集中すれば良い仕組みになっています。最先端技術の適用や斬新なアイディアを着想できるかどうかが多くの場合には勝負を左右しますが、課題の本質を理解した上でのシンプルな解法が優勝ソリューションとなることも少なくありません。
Kaggle とビジネスの間にはこのように多くの違いがありますが、共通点もあります。その共通点とは低コストかつ高精度の解法、すなわち卓越したアプローチが結果に大きなインパクトを与えうることです。本稿では、実際のテーマ中でノイズ除去が大きな効果を発揮した事例、強力な特徴量を得られた事例などについて紹介したいと思います。そのような優れた解法を見つけることは、Kaggleで勝つのに役に立つだけでなく、ビジネス価値を最大化することにも繋がるのです。
センサーデータの解析事例
機械学習モデルの精度は、学習データの品質に大きく依存します。高い品質のデータを得られなければ、どれだけ最先端のモデルを用いても良い結果を出すことはできないでしょう。実データはほとんどの場合でシグナル (予測の手がかり) とノイズ (雑音) が混在しており、そのノイズまでモデリングの対象にしてしまうと、シグナルを捉えることが難しくなってしまうのです。
特に時系列データ解析においては激しい変動が含まれることがあり、それに伴ってノイズが存在する場面が非常に多くみられます。例えばセンサーで測定されたデータには、センサーの誤作動、環境の変化などに起因するあらゆるノイズが含まれており、予測誤差が大きくなる原因となります。他の例としては、ウェブサイトのアクセスデータであれば、スパム行為、検索エンジンのクローラなどの存在によって、一般ユーザーの行為分析が難しくなります。シグナルとノイズの見分け方は機械学習のモデル改善における一つの重要なポイントです。モデル精度向上のためには、シグナルとノイズの比率(SNR: signal-to-noise ratio)を高める必要があり、多くの手間をかけて特徴量エンジンニアリングやモデリングの工夫を行うことでより多くシグナルを抽出しようと試みるのが通常ですが、一筋縄ではいかないこともよくあります。シグナルを大きくするアプローチとノイズを除去するアプローチの両者を比較すると、ノイズの除去の方がより手軽であり、また効果が大きい場面も多いといえます。
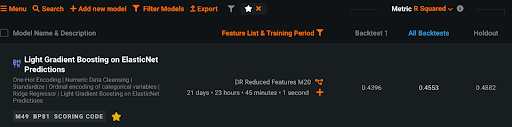
筆者が実務においてノイズを除去する手法を用いることで大幅な精度改善に成功した事例を以下に紹介します。お客様の課題としては、とある材料の製造プロセスにおける予兆を検知したいというもので、装置内のセンサーで測定した種々の観測値を予測することができれば、製造パラメータの制御によって燃料費の削減が可能になります。ここでネックになったのがデータの品質がとても低いという点で、安定操業期間と操業停止期間などを含む、非常にノイジーなものでした。当初、お客様は統計手法を用いて、例えば移動平均などの典型的な特徴量を作ってモデリングを試みたとのことでしたが、評価指標の決定係数 (R2乗) は0.5以下にしかなりませんでした。R2乗は通常0から1の範囲の値をとり、値が大きいほどモデルが適切にデータを表現できていることを意味し、小さいほど表現できていないことを意味します。ですので、0.5以下では精度が高いとはとても言えず、実際そのモデルは実用に足るものではありませんでした。移動平均特徴量は一定程度ノイズを軽減することができますが、ノイズが非常に大きかったために不十分だったのです。
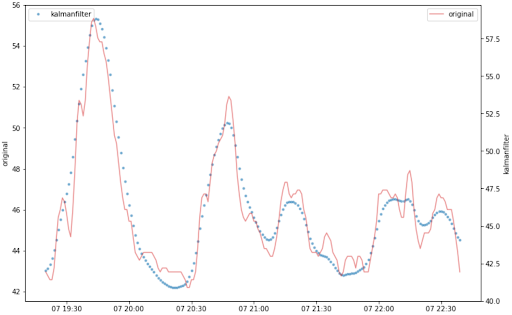
そのとき、筆者が思い浮かべたのが Web Traffic Time Series Forecasting という Kaggle コンペの上位チームのソリューションでした。そのコンペは Wikipedia の pageview を予測するコンテストだったのですが、とてもノイズの大きい時系列データに対する解析問題でした。優勝チームは RNN seq2seq を使って、ノイズが入ったデータであってもロバストにエンコード・デコードできるように学習することができており、素晴らしい解法でした。しかし、それよりさらに興味深かったのが8位チームの解法で、機械学習モデルではなく、カルマンフィルタ (kalman filter) でノイズを除去し、統計手法を加えることでロバストな予測モデルを構築するというもので、極めて簡潔かつ強力 (simple and powerful) であり、これこそが実務で追求するべき生産性の高い技術ではないかと当時とても感心した覚えがあります。
カルマンフィルタとは、状態空間モデルと呼ばれる数理モデルにおいて、内部の見えない「状態」を効率的に推定するための計算手法です。状態空間モデルでは、例えば、センサーなどから得られる情報を「観測値」として、そこから「状態」を推定し、これに基づいて制御を行います。「観測値」にノイズがあっても、「状態」がノイズを除去して、本来の正しい観測値になるでしょう。
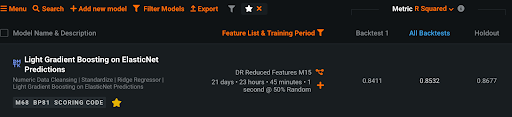
さっそくカルマンフィルタを用いて全ての観測値を処理した上で移動平均特徴量を作成してDataRobot でモデリングしてみたところ、従来手法では0.5以下だった R2乗が0.85以上に一気に向上し、魔法のような大幅改善を実現することができました。しかも数万行データに対して数十秒で処理は完了し、低コストで高精度な予測モデルを実現できたのです。
※カルマンフィルタ処理前後の比較
※ノイズ除去前の精度スコア
※ノイズ除去後の精度スコア
python でカルマンフィルタを扱える pykalman というライブラリがあり、使い方がシンプルなので便利です。
| from pykalman import KalmanFilter def Kalman1D(observations,damping=1): observation_covariance = damping initial_value_guess = observations[0] transition_matrix = 1 transition_covariance = 0.1 initial_value_guess kf = KalmanFilter( initial_state_mean=initial_value_guess, initial_state_covariance=observation_covariance, observation_covariance=observation_covariance, transition_covariance=transition_covariance, transition_matrices=transition_matrix ) pred_state, state_cov = kf.smooth(observations) return pred_state observation_covariance = 1 # <- Hyperparameter Tuning df[‘sensor_kf’] = Kalman1D(df[‘sensor’].values, observation_covariance) |
音声データの解析事例
機械学習モデルの精度は、学習データの品質により限界が決まりますが、特徴量エンジニアリングの技術を使いこなすことができれば、そのポテンシャルを最大限に引き出せます。特徴量の作成は機械学習モデルの構築プロセスの中で最も手間がかかる部分で、異なる特徴量の組み合わせを用いた実験に膨大な時間を費やしてしまうことも少なくありません。しかし、データの本質を理解して、業務知識を表現できる特徴量を抽出することができれば、少数の特徴量でも高精度のモデルを構築することができるのです。
筆者が実務においてシンプルな特徴量で精度改善を実現した事例の一つを紹介したいと思います。お客様の課題は、自動車のエンジンノッキングを制御する工程で、従来はエンジンノッキングのレベルは熟練者の聴覚で判定されていましたが、これは特殊な訓練が必要な上に判定が難しく、またバラツキが発生してしまうのが悩みでした。このノックレベリングを自動化することができれば、大きなコスト削減になります。最初に作成したベースラインモデルは、音声波形データのスペクトログラム、統計特徴量、スペクトログラム画像などを利用しました。このアプローチによって R2乗が0.7までは到達したのですが、それ以上の改善がなかなか難しいという状況でした。
このとき、筆者が思い浮かべたのが Kaggle の LANL Earthquake Prediction コンペの上位チームのソリューションでした。このコンペは地震の研究で使用される実験装置から得られた「音響データ(acousticdata)」のみを使って、地震発生までの時間(timeto_failure) を予測するコンペだったのですが、優勝チームを含む多数の上位チームがメル周波数ケプストラム(MFCC)を含む非常に少数の特徴量に絞り込むことで過学習リスクを軽減し、ロバストなモデルを構築するアプローチを採用していました。
MFCC は、人の聴覚上重要な周波数成分が引き伸ばされてケプストラム全体における割合が増えることで、人が聞いた音の特徴をよく表すと考えられています。また、N 次のメルフィルタバンクを通すことにより、人の聴覚上重要な特徴を保ちながらケプストラムの次元を N まで減らすことができ、機械学習における計算負荷を減らせるメリットもあります。
エンジンノッキングのレベル判定のタスクに対して、この MFCC 特徴量は非常に適しており、このお客様のモデルに追加することで R2乗を0.8以上に大幅に改善することに成功しました。そして数百音声ファイルに対して数十秒で処理を完了することができ、ここでも低コストで高精度を実現することができました。
python で MFCC 特徴量を抽出できる librosa というライブラリがあり、以下にサンプルコードを記載しますのでご参考ください。
| import librosa fn = ‘audio file path’ y, sr = librosa.core.load(fn) mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20) mfcc_mean = mfcc.mean(axis=1) |
DataRobot における Custom Model
現在、DataRobot プラットフォーム上で pykalman、librosa などを利用することも実は可能になっています。Composable ML を使用することで、DataRobot にビルトインされた様々なタスクに加え、 Python または R でユーザーが設計したカスタムタスクを組み合わせることで、独自の機械学習パイプラインを簡単に構築することができるのです。また、タスク用のカスタムコンテナ環境を使用することで、依存関係の追加がいつでも可能です。
※カスタムコンテナ環境
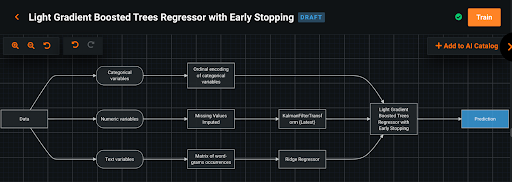
※KalmanFilterを組み合わせるカスタムタスク
まとめ
ここまで説明してきましたとおり、機械学習モデルの精度向上とコスト削減を両立するためには、単に妥協してしまうのではなく、最適解を見つけるのが重要なポイントです。DataRobot の実際の顧客事例に基づいて、Kaggle コンペから学んだ簡潔かつ強力な技術を応用することで、低コストでありながら高パフォーマンスな予測モデルを実現できたことを説明してきました。DataRobot Composable ML は Python または R でカスタム環境、タスクを構築することができ、DataRobot プラットフォームと連携して、最適なモデルを構築することができます。また、全自動化による高い生産性とカスタマイズ性を両立する新機能である Composable ML につきましても、是非ご活用頂ければと思います。
参考 Kaggle コンペ
- https://www.kaggle.com/c/web-traffic-time-series-forecasting
- https://www.kaggle.com/c/LANL-Earthquake-Prediction
メンバー募集
DataRobot では AI の民主化をさらに加速させ、金融、ヘルスケア、流通、製造業など様々な分野のお客様の課題解決貢献を志すメンバーを募集しています。AI サクセスマネージャ、データサイエンティスト、AI エンジニアからマーケティング、営業まで多くのポジションを募集していますので、興味を持たれた方はご連絡ください。