一般化加法モデルと格付表
DataRobotのデータサイエンティスト中野高文です。
近年非線形モデル(ツリー系のモデル、カーネルを用いたSVM、K近傍、ニューラルネットなど)の機械学習のモデルは多くのデータにおいて精度が高くなる事が多く、頻繁に用いられていますが昔ながらの線形モデルが好まれるケースも未だに存在します。
例えば、規制の強い金融、保険などの業界でははっきりと係数がわかるアルゴリズムである必要がある場合もありますし、デプロイする際に直接SQLで書ける必要があるなどといった制約のために線形モデルを利用する必要が生じる場合もあります。
今回はそこで上記のような線形モデルの利点を全て保ったまま、多くのデータセットで機械学習のモデルと同レベルの精度の予測が可能と言われている一般化加法モデル (Generalized Additive Model, GAM)を紹介します。DataRobotでも一般化加法モデルの中でも2項間の相互作用も含まれているGeneralized Additive 2 Model (GA2M)*1が数ヶ月前に利用可能となりました。
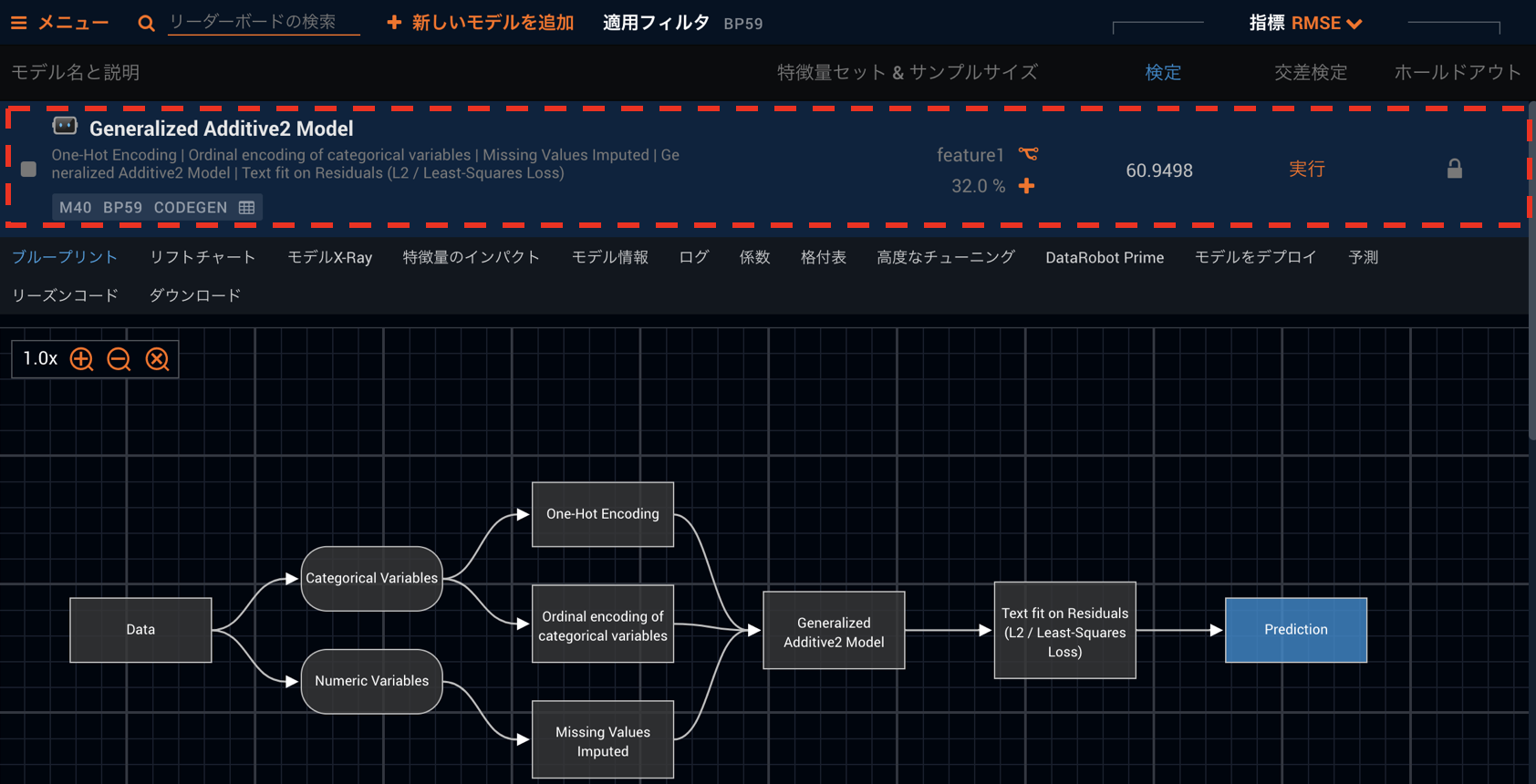
今回はGA2Mモデルの紹介を以下のように行なって行きます。
- 対比のために一般化線形モデルを簡単に紹介
- 一般化加法モデルのコンセプト
- GA2Mの係数「格付表」のアウトプットと見方
一般化線形モデルとは
一般線形モデルとはyの値を特徴量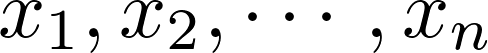 に重みをつけて組み合わせた値でyを説明しようとするモデルです。式で表すと係数
に重みをつけて組み合わせた値でyを説明しようとするモデルです。式で表すと係数 を用いて
を用いて
![]()
と書くことができます。簡単に言うと、yの値をの値を組み合わせて説明を行って、説明できない部分(ノイズ)を と表していると言うことですね。期待値を取ってとノイズを取り除いて表す(感覚的には何度も繰り返して行えば、ノイズはゼロと見なせる)と
と表していると言うことですね。期待値を取ってとノイズを取り除いて表す(感覚的には何度も繰り返して行えば、ノイズはゼロと見なせる)と
![]()
と表されます。yが正規分布と言われるバランスの取れた分布である時には一般線形モデルを用いるのですが、yの分布が歪曲している際にはそれを発展させた一般「化」線形モデルが使われます。数式で持って書くと、
![]()
となります。感覚としてはE(y)が歪曲しているので、それをある関数gを持って歪みを取り除く(正規化させる)と考えていただいても良いかもしれません。例えばyがポワソン分布の場合にはgとしてlog関数が使われます。
一般化線形モデルは数式(3)の形を持っているため、係数の値を見ることで明確に理解できるモデルとなっています。
一般化加法モデルとは
一般化加法モデルとは一般化線形モデルのそれぞれの特徴量に重みをつけるだけでなく、もっと複雑な形を持った関数とする事で複雑な現象も表す事ができるようにしたモデルです。
![]()
 を係数との掛け算に限ると数式(3)となる事がわかると思いますが、一般化加法モデルは単純な比例関係で無い物をを説明できるため、多くのデータで一般化線形モデルより精度がよくなることが多くみられます。
を係数との掛け算に限ると数式(3)となる事がわかると思いますが、一般化加法モデルは単純な比例関係で無い物をを説明できるため、多くのデータで一般化線形モデルより精度がよくなることが多くみられます。
しかし世の中にある一般のプロセスはいくつかの特徴量がお互いに相互に影響を及ぼす場合も多く見られます。例えばある商品の世界の国々(特徴量1)での年齢別(特徴量2)の売上を見てみると、日本ではお年寄りによく売れているがアメリカでは若い人によく売れるといった事が見受けられるかもしれません。そこでそのような相互作用を上手く説明するために一般化加法モデルに2項間の相互作用を含めたものが「GA2M」モデルとなります。
格付表の見方
一般化線形モデルではリーダーボードの係数タブより係数を確認する事ができますが、一般化加法モデルの係数はその横にある「格付表」タブで確認する事ができます。こちらではこのモデル内で用いられている変換と変換後の値に対する係数、さらにはそれぞれの特徴量の強さを表す「Feature Strength」といったものを全てが一目でわかるようになっています。
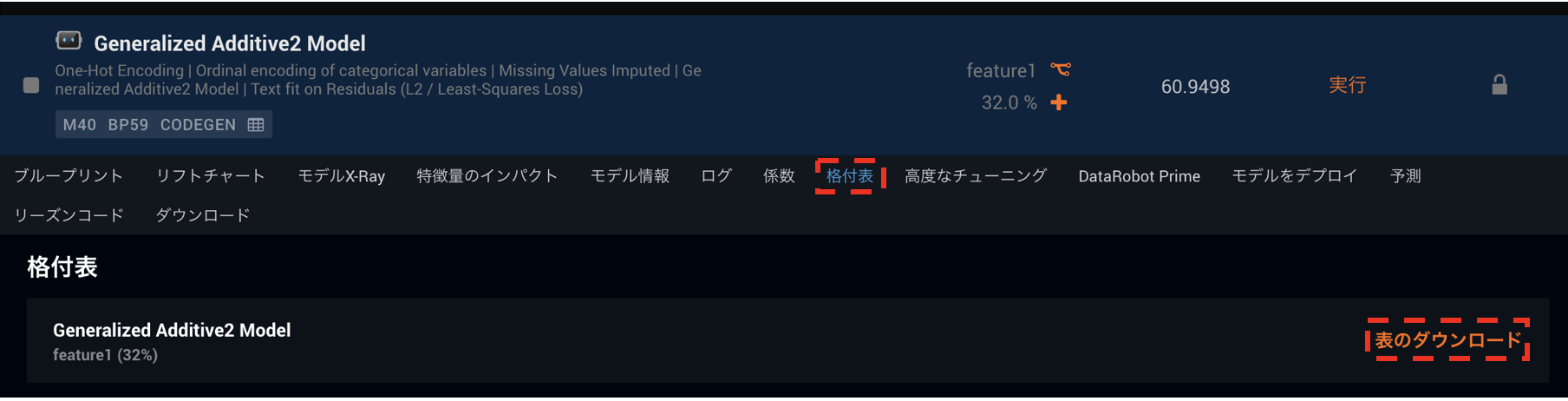
「表のダウンロード」よりCSVをダウンロードしてその中身を確認していきます。見ていただくとわかるように、大きく分けて⑴モデル全体の情報、⑵個々の係数情報の2つの部分にわかれています。
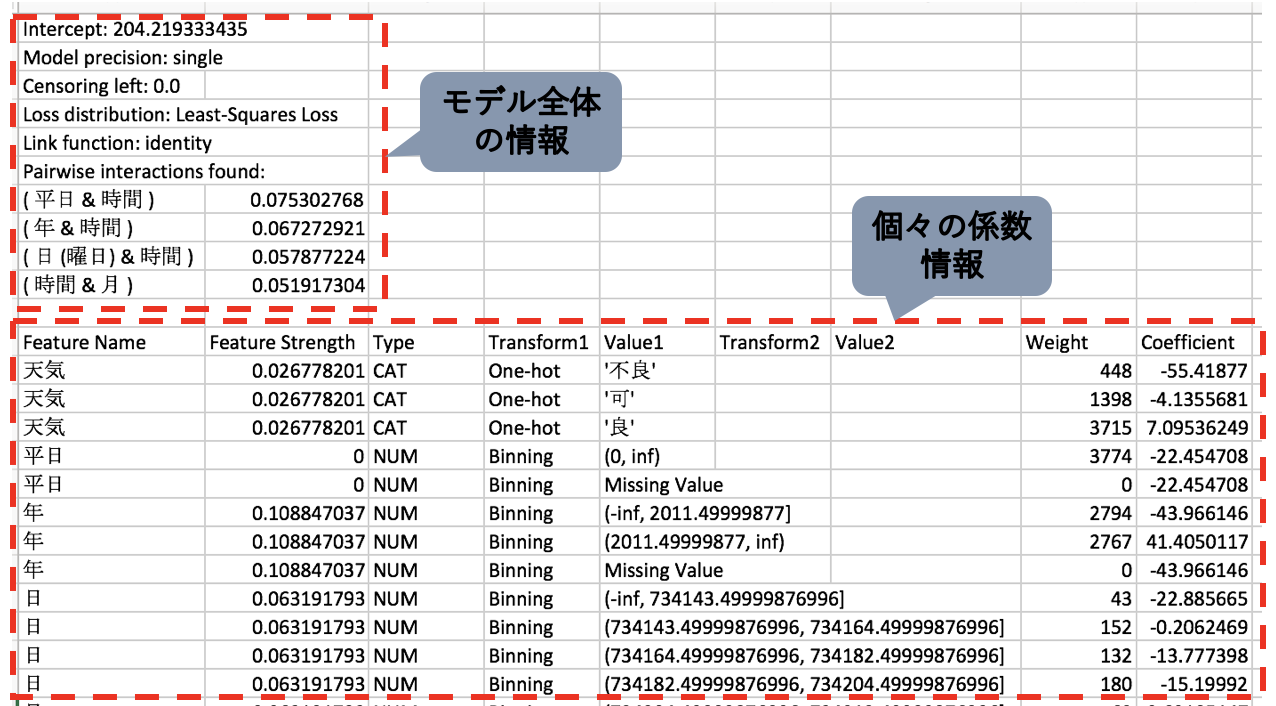
モデル全体の情報
モデル全体の情報としては⑴全てのモデルに共通の項目と⑵モデルごとに特有の項目があります。モデルごとに特有の項目としては前処理の情報(例えばword-gramの情報など)があり、全てのモデルに共通の項目としては以下のようなものがあります。
- Intercept : 切片の値(数式(4)の
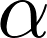 に該当)
に該当) - Loss distribution : Least-Square Loss, Binomial Deviance, Poisson Deviance, Gamma Deviance, Tweedie Devianceの4種があります。これは最適化する指標で選択したものに対応します。
- Link function : 数式(4)の変換gに対応します。この変換は最適化する指標によって以下のように決められています。
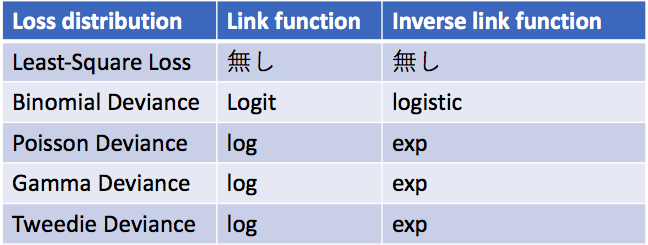 この表にあるInverse link functionとは数式(4)をE(y)をアウトプットするように書き換えた以下の数式の
この表にあるInverse link functionとは数式(4)をE(y)をアウトプットするように書き換えた以下の数式の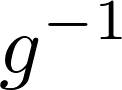 に当たります。
に当たります。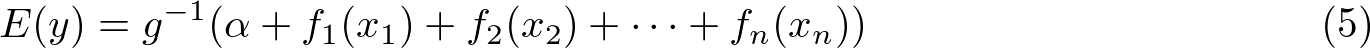
- Pairwise interactions found : 2項間の相互作用は実際にモデルの作成に有効な物のみ使われます。その有効な相互作用のリストがこちらにリストアップされています。その横には後から説明する「Feature Strength」が表示されています。
個々の係数情報
このリストでは1行1行の情報が、ある特徴量に対する条件文に相当し、その係数 (Coefficient)や重み (Weight)をリスト化しています。
- Feature Name : 対応する特徴量名。相互作用の場合は (特徴量1 & 特徴量2)といったように括弧付けで表される。
- Feature Strength : その特徴量の影響度。それぞれの特徴量にCoefficientをWeightを用いた加重和を取り、和が1となるように正規化した値。
- Type : その特徴量の型。相互作用の場合「2W-INT」と表記。
- Transform1 : 特徴量(相互作用の場合は特徴量1)の変換方法
- Value1 : Transform1変換に対応する値/値域
- Transform2 : 相互作用の場合の特徴量2の変換方法
- Value2 : Transform2変換に対応する値/値域
- Weight : その特徴量の値域に存在するデータ行数
- Coefficient : その特徴量の値域への係数
- Relativity : exp(Coefficient)の値を表示。Inverse link functionがexpの時のみ表示。
具体例として以下の格付表の個々の係数情報をみていきましょう。

例えば上のテーブル2行目の「Feature Name = 平日」の行を見ていただくと、これは”平日という数値型の特徴量をグループにまとめる「Binning」という処理を行い、そしてその値が「(0, inf)」(0と無限大の間) の場合は係数-22.454798を割り当てます”といったプロセスに相当し、そのデータがトレーニングデータ中に3774行見受けられます、といった説明を行なっています。
上のテーブル2行目の「Feature Name = ( 平日 & 時間 )」の行の場合、相互作用を表し、”平日という特徴量が(0, inf)、かつ時間という特徴量が(-inf, 0.499・・・)の場合は係数-21.196061を割り当てます”というプロセスに相当し、そのようなデータが167行存在すると説明しています。

それでは上のような格付表で「平日 = 1, 時間 = 0.3」のデータ(個々の係数情報の3行の条件全てに当てはまっています)に対してどのような予測値が返されるのでしょうか?今回Link functionは”identity”つまり必要ないため、Inverse link functionも必要ありません。それを数式(5)に当てはめると

となります。
まとめ
今回は線形モデル同様に⑴モデルが係数の大きさで明確に判断でき、⑵係数で簡単にコード内に埋め込みも可能、⑶同時に多くのデータで精度も非常に良い、といった多くの利点を持った2項間の相互作用を含む一般化加法モデル(Generalized Additive 2 Model, GA2M) と格付表を紹介しました。
今後はダウンロードしたcsvの格付表の係数に手動で変更を加えてモデルを細かくチューニングすると言った機能も利用可能になる予定なので、完全にホワイトボックスであるモデルを使う必要がある場合には精度も同時に担保したこちらのモデルを注目してください。
*1 : Accurate Intelligible Models with Pairwise Interactionsの論文を参照