

Without Geography, You’re Nowhere
It has been said that the majority of insurance risk relates to geographic factors. With property insurance, hurricane, earthquake, flood, storm and fire risks are strongly influenced by weather, climate, and proximity to hazards. For auto/motor insurance, the risk of collisions and theft are affected by road and traffic conditions, weather, and the socioeconomic/behavioral environment. Similarly, casualty and liability risks are affected by the legal domains that apply, and by cultural norms.
Geographic rating has posed a challenge to actuaries. The complex patterns of geography don’t fit neatly into the tabular formats that actuaries use for pricing analysis. Back in the late 20th century, some of the world’s leading actuaries developed special smoothing techniques, such as “Geographic Premium Rating By Whittaker Spatial Smoothing.”

These spatial smoothing techniques were run as secondary analyses, smoothing the model errors from the main pricing models (which were based upon generalized linear models) across adjacent postcodes. Postcodes were organized into contiguous groups called “rating districts.” Then we would add the rating district into the main models as an extra rating factor, and refit the generalized linear model (GLM).
This spatial smoothing approach wowed me when I first saw it. Back then computing power was limited, and I had to manually code custom software in C++ to do the spatial smoothing. I read and reread the research papers, trying to engineer a practical approach that would work on my PC without overloading it. In the end, I hacked together a solution, but it took a long time to calculate the answers, and it felt clumsy because the geographic rating was a separate step to the other rating factors, and because it treated geography as an after-effect rather than a primary risk driver.
Other actuaries took a different approach. They added external data, collected by marketing agencies or government census surveys. Each insurance policy belonged to a statistical data collection region, and each statistical region had its own demographic characteristics, such as age profiles and household incomes. Actuaries used these characteristics as proxies for the insurance risk relativities. This data format was a more comfortable fit with the GLM model techniques that actuaries used. But it treated all risks the same within a postcode. And some postcodes are large, containing very different risk profiles within them. In particular, I was uncomfortable with models that treated buildings in large regional cities the same as remote farms located in the same postcode.
Fast forward to current times. Now I can run models on powerful computers and I have access to complex machine learning models that can capture the complexity of rating factors. I don’t have to model geographic effects separately to other rating factors.
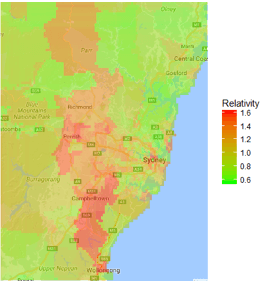
The map above shows the geographic rating relativities from an auto/motor pricing model that I built on demo data combining latitude/longitude with census data, and all the other usual rating factors. Even though my demo data contains only 50,000 insured vehicles, DataRobot faithfully reproduced the geographic relativities.
Unlike 20 years ago I could build a complete insurance pricing model with just one click of a button. DataRobot makes this easy for me, building dozens of different algorithms and finding the best one for my data. If only Sydney’s traffic jams were as easy to overcome as mapping its insurance risks!


Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
