


Winning with accurate and actionable information in banking
The Situation
In todays information-driven economy nowhere is clean, connected and trustworthy information more vital than in banking where information is the lifeblood of the business. In banking accurate, timely and actionable information is the difference between market leaders and also-ran. The banking business model is based on the concept of leverage. Banks raise capital through deposits, borrowings and sale of financial instruments and turn around and invest that capital to make loans and mortgages. Bank earnings are driven by the interest spread between interest earned on loans and interest paid out on deposits and borrowings. This is an overly simplistic generalization but is the crux of how the banking business model works.
The Opportunity
The wrinkle in the banking model is the need for reserve capital. Turns out that for everyone to have trust and confidence in the system and for the model to work, banks should maintain reserve capital to meet financial obligations incase the depositors or borrowers come looking for their money. The actual level of reserve capital is determined by government regulations but for current purposes its fair to assume that for every dollar banks raise they are required to keep up to 10 cents in reserves. Imagine what happens if the banks have dirty data like multiple instances of a single depositor or the single liability – the reserve capital requirements go up at the expense of deployed capital. Banks get hit with idle interest bearing deposits or borrowings and lower deployed capital resulting in increased cost, reduced revenues and lower margins. So, how do banks address these data quality issues? Simple – have IT use their classic, rule-based data quality tools to clean up the data, remove duplicates, standardize and everyone’s happy. Not so fast!
The case for business analyst-friendly, smart, enterprise-grade data preparation
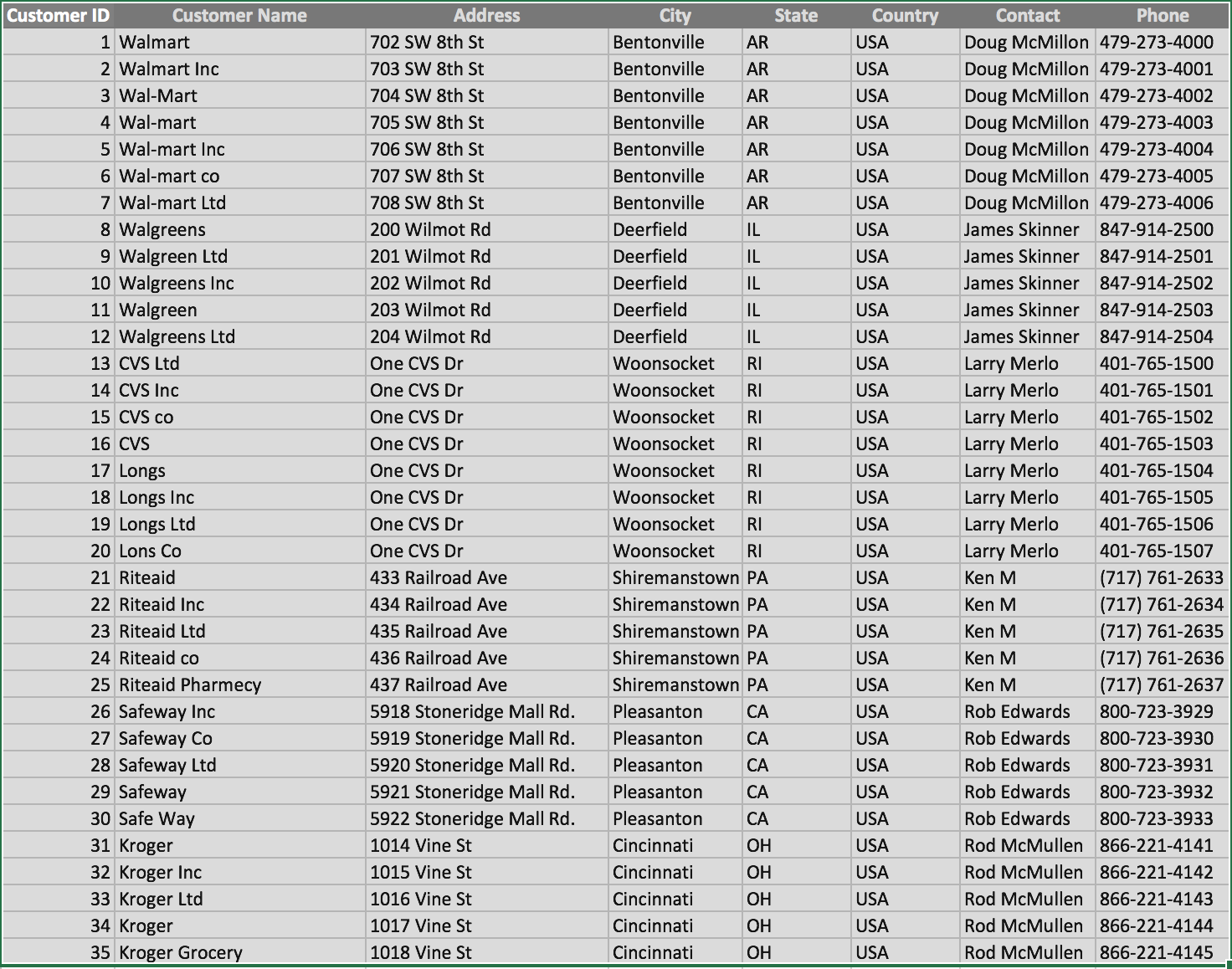 Look at the sample of depositor information on the right. The classic, rule-base data quality approach using traditional tools to clean, deduplicate and standardize data won’t work in this case since even after cleaning customer names different addresses or phone numbers might cause these records to be flagged as unique resulting in duplicate data. The massive volume, variety and velocity of human and machine generated data and the ever changing nature of data quality issues further complicate things. The classic, rule-based data quality systems simply can’t keep pace with the data deluge and unknowns. Enter business analyst-friendly, smart, self-service data preparation platform like Paxata. Here’s how a modern data prep solution like Paxata addresses these challenges:
Look at the sample of depositor information on the right. The classic, rule-base data quality approach using traditional tools to clean, deduplicate and standardize data won’t work in this case since even after cleaning customer names different addresses or phone numbers might cause these records to be flagged as unique resulting in duplicate data. The massive volume, variety and velocity of human and machine generated data and the ever changing nature of data quality issues further complicate things. The classic, rule-based data quality systems simply can’t keep pace with the data deluge and unknowns. Enter business analyst-friendly, smart, self-service data preparation platform like Paxata. Here’s how a modern data prep solution like Paxata addresses these challenges:
Business analyst-friendly, self-service solution: Paxata provides an Excel like interface for non technical business users to interactively and visually clean, combine and transform data without writing code, sampling data or building schemas. A banking analyst with the right business context and interactively working with the depositor information can quickly spot the issues and in a few clicks automatically clean, deduplicate and standardize data. Paxata balances business’s need for information with IT’s need for governance so business is empowered with self-service information creation and consumption within the guardrails of governance provided by IT.
Smart: With the massive volume, variety and velocity of data confronting the banks, business analyst-friendliness isn’t enough. The analysts need an intelligent solution that can automatically spot and address known and unknown data quality issues at scale across multiple business units, geographic locations, customer segments and product categories. Enter Paxata’s smart data preparation solution that leverages machine learning, natural language processing (NLP), semantic analysis, in-memory processing and commodity hardware based distributed processing technologies such as Spa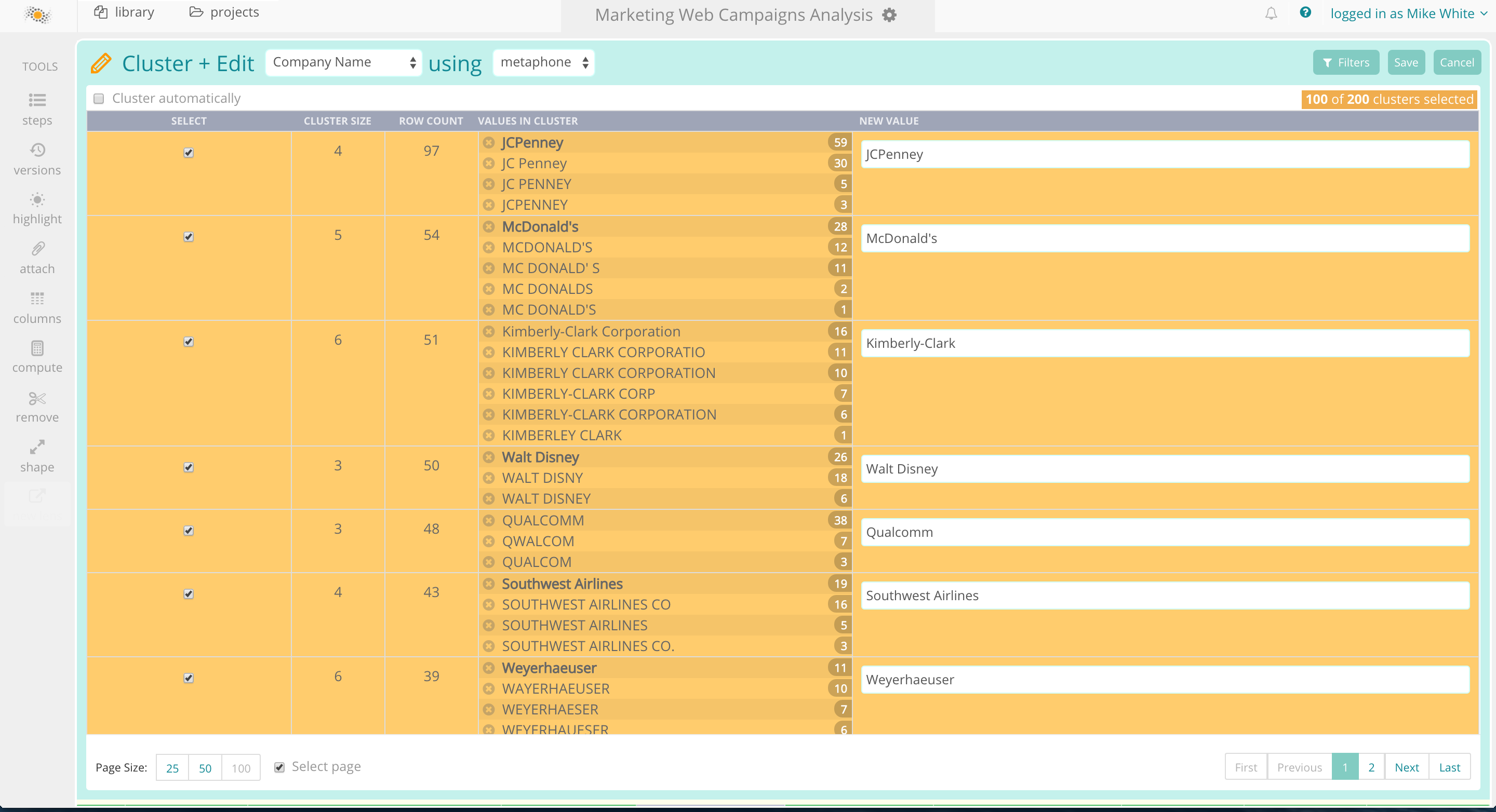 rk and Hadoop to clean, combine, shape, enrich and transform data and address known and unknown data quality issues. Paxata’s cluster and edit functionality uses NLP algorithms such as ngram, fingerprinting and metphone to automatically discover clusters of similar entity values and makes recommendations on combining them into a single golden record. In contrast to the classic rule-based approach, Paxata is continuously learning and evolving to automatically address known and unknown data quality issues.
rk and Hadoop to clean, combine, shape, enrich and transform data and address known and unknown data quality issues. Paxata’s cluster and edit functionality uses NLP algorithms such as ngram, fingerprinting and metphone to automatically discover clusters of similar entity values and makes recommendations on combining them into a single golden record. In contrast to the classic rule-based approach, Paxata is continuously learning and evolving to automatically address known and unknown data quality issues.
Enterprise-grade: Finally, as issues are uncovered and fixed, every change should be captured and tracked to address information security and governance requirements and give bankers the accurate and trustworthy information they need to confidently run the business. Paxata provides auditing, lineage, versioning, recording and reordering capabilities to track, undo and redo changes, operationalize and provide context on steps taken to prepare data.
In conclusion, accurate and actionable information is paramount to success in banking and Paxata is the fastest path to turn raw data into reliable information. You can learn more about Paxata here.
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
