


Running Code and Failing Models
Machine learning is a glass cannon. When used correctly, it can be a truly transformative technology, but just a small oversight can cause it to become misleading and even actively harmful. Even if all the code runs and the model seems to be spitting out reasonable answers, it’s possible for a model to encode fundamental data science mistakes that invalidate its results. These errors might seem small, but the effects can be disastrous when the model is used to make decisions in the real world.
The promise and power of AI lead many researchers to gloss over the ways in which things can go wrong when building and operationalizing machine learning models. As a data scientist, one of my passions is to reproduce research papers as a learning exercise. Along the way, I have uncovered cases where the research was published with faulty methodologies. My hope is that this analysis can increase awareness about data science mistakes and raise the standards for machine learning in research. For example, last year I shared an analysis of a project by Harvard and Google researchers that contained fundamental errors. The researchers refused to fix their mistake even when confronted with it directly.
Over the holidays, I used DataRobot to reproduce a few machine learning benchmarks. I found many examples of machine learning code that ran without errors but that were built using flawed data science practices. The examples I share in this post come from the world’s best data scientists and affect hundreds of peer-reviewed research publications. As these examples show, errors in machine learning can be subtle. The key to finding these errors is to work with a tool that offers guardrails and insights along the way.
Target Leakage in a fast.ai Example
Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD by Jeremy Howard and Sylvain Gugger is a hands-on guide that helps people with little math background understand and use deep learning quickly. In the section about tabular datasets, the authors use the Blue Book for Bulldozers problem, the goal of which is to predict the sale price for heavy equipment at auction. I tried to replicate their machine learning model and wasn’t able to beat their model’s predictive performance, which piqued my interest.
After carefully inspecting their code, I found a mistake in their validation dataset. Their code attempted to create a validation test set based on a prediction point of November 1, 2011. The goal was to split the data at this point so that you could train on the data known at prediction time. The performance of the model is then analyzed on a test set, which is located after the prediction point. Unfortunately, the code was not written correctly; there was contamination from the future in the training data.
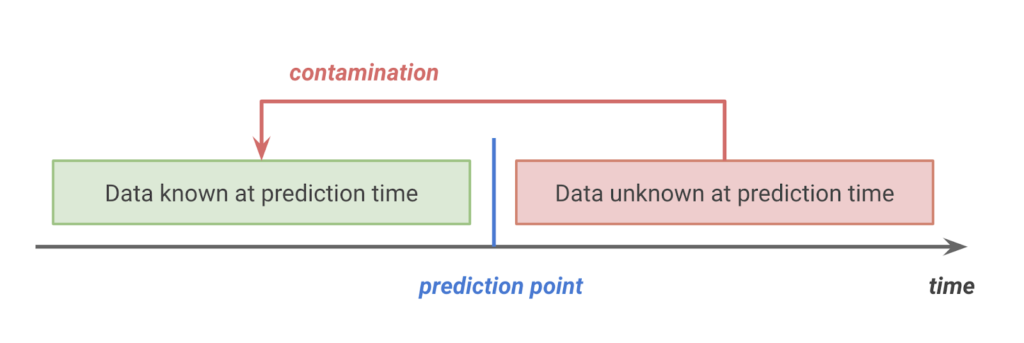
The code below might at first look like it separates data before and after November 1, 2011, but there’s a subtle mistake that includes future dates. The use of information in the model training process that would not be expected at prediction time is known as target leakage, and it led to an over-optimistic accuracy. Because I used DataRobot, which requires and validates a date when creating a validation dataset based on time, I was able to find the mistake in the fast.ai book.
The following figure shows the Python code and how it led to data after November 2011. (See the source for this graphic.)
After the target leakage was fixed, the fast.ai scores dropped, and I was able to reproduce the results outside of fast.ai. This simple coding mistake led to a notebook and model that appeared valid. If this model were put into production, the results would have been much worse on new data. After I identified this issue, Jeremy Howard agreed to add a note in the course materials.

SARCOS Dataset Failure
The SARCOS dataset is a widely used benchmark dataset in machine learning. Based on predicting the movement of a robotic arm, SARCOS appears in more than one hundred academic papers. I tested this dataset because it appears in various benchmarks by Google and fast.ai.
The SARCOS dataset is broken into two parts: a training dataset (sarcos_inv) and a test dataset (sarcos_inv_test). Following common data science practices, DataRobot broke the SARCOS training set into a training partition and a validation partition. I treated the SARCOS test set (sarcos_inv_test) as a holdout. When I looked at the results, I immediately noticed something suspicious. Do you see it?
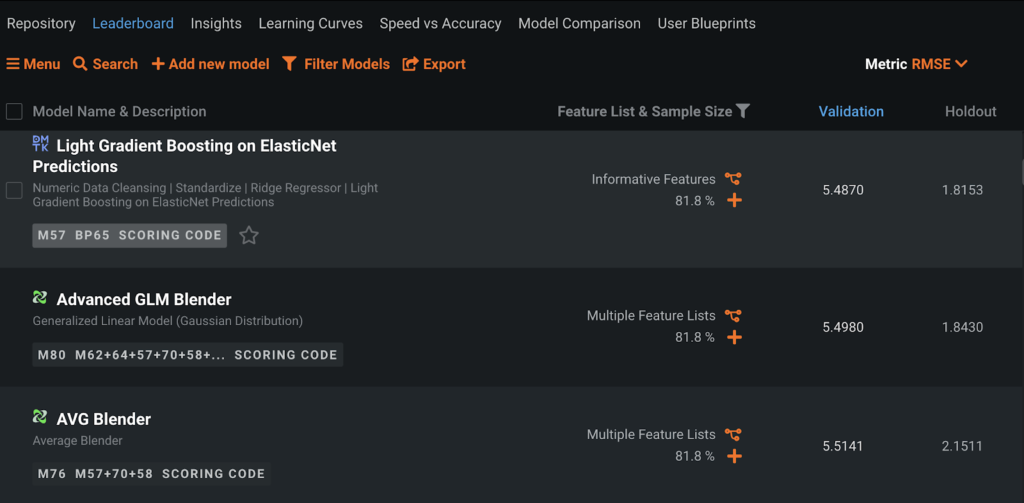
The large drop between the validation score and the holdout score indicates that something is very different between the validation and holdout datasets. When I examined the holdout dataset (the SARCOS test set), I found that every row in the test set was in the training data too. After some investigation, I discovered that the holdout dataset was built out of the training dataset. Of the 4,449 examples in the test set, 4,445 examples are present in the training set, too. The target leakage here is significant. By overfitting or memorizing the training dataset, it’s possible to get perfect results on the test set. Overfitting, a well-known issue in machine learning, is illustrated in the following figure. The test dataset should have used out-of-sample testing to prevent overfitting.
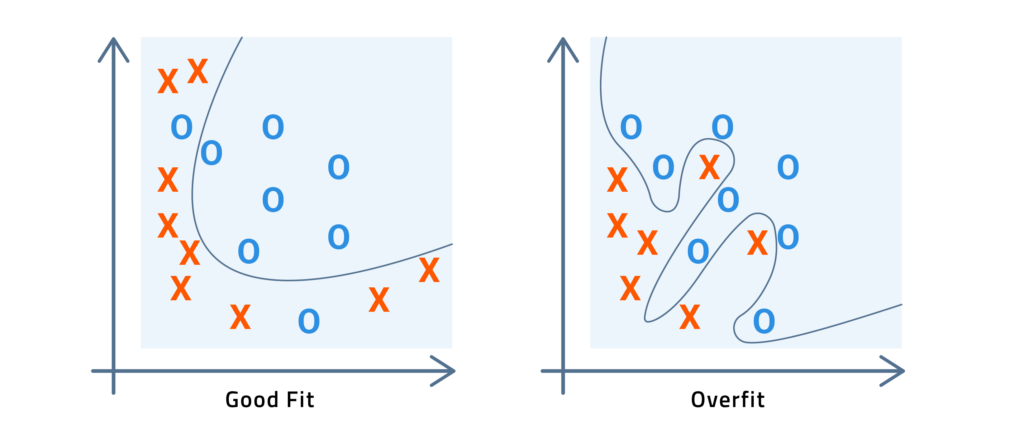
Target leakage helped to explain the very low scores of the deep learning models. For comparison, a random forest model achieves 2.38 mean squared error (MSE), while a deep learning model overfits and produces 0.038 MSE. Judging from the suspiciously large difference between the models, it appears that the deep learning model just memorized the training data, which is why it had such low error.
The consequences of this target leakage are far-reaching. More than one hundred journal articles relied on this dataset. Thousands of data scientists have used it to benchmark their machine learning code. Researcher Kai Arulkumaran has already acknowledged this issue and now the research community is dealing with the ramifications of the target leakage.
Why wasn’t this error discovered earlier? When I reproduced the SARCOS benchmarks, I used a tool that includes technical safeguards for proper validation splits and provides transparency in the display of the results of each split. DataRobot’s AutoML was designed by data scientists to prevent these sorts of issues. In contrast, working within code, it was quite easy to overlook this fundamental issue. After all, thousands of data scientists have rerun their code and published their results without a second thought.
Poker Hand Dataset
The Poker Hand dataset is another widely used benchmark dataset in machine learning. It’s used to predict poker hands (for example, a full house from five cards). The fast.ai and Google benchmarks for this model use the accuracy metric. Accuracy is a measurement for assessing the predictive performance of a model (basically, the percentage of predictions that are correct). Although it’s easy to get running code with the accuracy metric, it’s not good data science practice for this problem.
When DataRobot builds a model with the Poker Hand dataset, by default, it uses log loss as an optimization metric. Log loss is a measure of error for a model. At DataRobot, we believe that it isn’t good practice to use accuracy as your metric on a classification project with imbalanced classes. With imbalanced data, you can easily build a highly accurate model that’s useless.
To understand why accuracy isn’t the best metric when classifying unbalanced data, consider the following figure. Minesweeper is a popular game where the goal is to identify a few mines that are scattered across a board. Because there are a lot of squares with no mines, you could generate a very accurate model just by predicting that every square is safe. Although a 99% accurate model for Minesweeper sounds impressive, it’s not very useful.

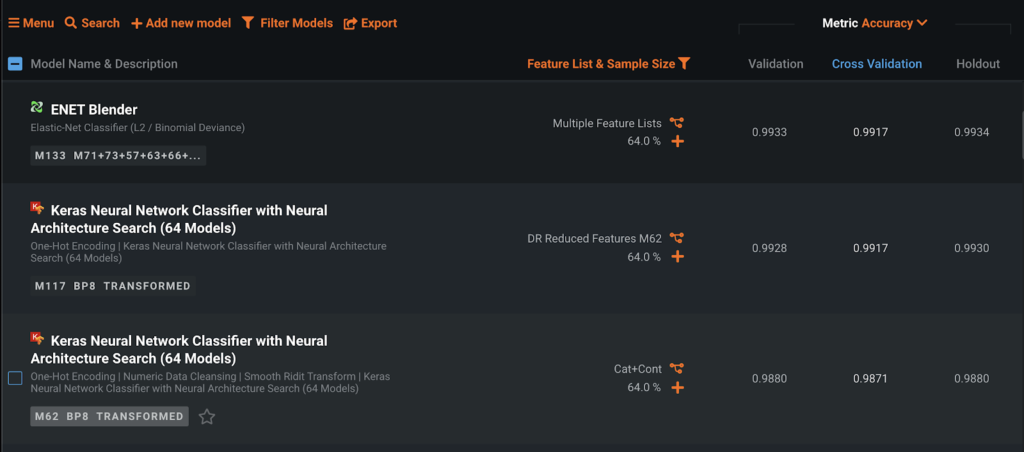
Automated feature selection in DataRobot provides a more parsimonious feature list. In the Poker Hand dataset, DataRobot created a DR Reduced Features list with only six features. The starting feature list for this dataset, Cat+Cont, contained 15 features. The leaderboard below shows that the simpler DR Reduced Features list performs better than the full Cat+Cont feature list. The model below was optimized on log loss, but I am viewing the accuracy metrics for comparison to the existing benchmarks.
Conclusion
I have shared simple examples of how data scientists can have running code, but failed models. After spending a week going through a half dozen datasets, I am even more convinced that automation with technical safeguards is a required part of building trusted AI. The mistakes I’ve shared here are not isolated incidents.
The issues go beyond the reproducibility crisis for machine learning research. It’s a great first step for researchers to publish their code and make the data available, but as these examples show, sharing code isn’t enough to validate models. So, what should you do about this?
In regulated industries, there are processes in place to validate running code (for example, building a challenger model using a different technical framework). For its safeguards and transparency, many organizations use DataRobot to validate models. Just rereading or rerunning a project isn’t enough to identify errors.
-
How to Choose the Right LMM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
