


Putting the Promise of the Data Lake in Reach
Agility, elastic scaling, and unlimited analytic potential. The promise of a data lake is very appealing to organizations that were thwarted and obstructed by legacy infrastructure in their quest to drive business via data. Regrettably, the reality of the actual journey needed to reach the promised land revealed to be quite daunting and led to countless failed initiatives or projects that fulfilled only a sliver of the anticipated ROI from the data lake investment.
So where do the dragons live that make so many data lake endeavors go up in flames?
The Three Big Impediments
- Limit user access to the data lake
If only a tiny fraction of your employees are able to access the data in the lake, you are just creating a new bottleneck. Self-service access points to your data lake provide incredible scaling potential when it comes to utilizing data as an asset. - The high cost of on-premise “elastic” scaling
One of the big benefits of a data lake is elastic compute, where resources can be repurposed from job to job and from use case to use case. The problem with an on-premise data lake is that the lead time to add new capacity can be 6 to 9 months and pre-buying capacity that is not yet needed is a non-starter for many organizations. This limitation is not an issue in the cloud; you can spin up new compute in minutes and spin it down when you are done and you only pay for what you use. - The complexity of managing layers in the data lake
Putting in Hadoop is only the starting point. You need to figure out how to prepare data and how to analyze it in a scalable, efficient way. With all of the tools in the market today, there is no universal handbook explaining how to plug A to B to C products together; moreover, not all of these products play nicely in the sandbox. The uncertainty around how all the pieces work together led many IT organizations to lock down their data lake infrastructure to such a degree that they ended up with the same old bottlenecks that led them down the data lake path in the first place.
CloudT30 to the rescue!
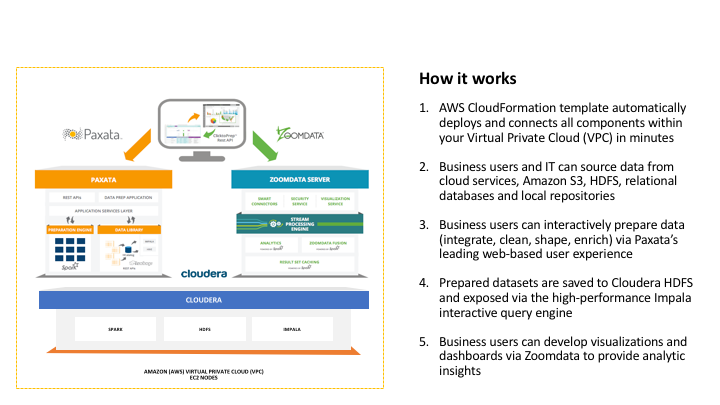
At Strata in New York this week, we are showcasing an answer to make the data lake vision a reality and drive business outcomes in record time. CloudT30 is a solution developed by our partner, Clarity Insights, which leverages AWS CloudFormation templates to provide a point-and-click way for anyone to stand up a fully-functional data lake – from data management to data preparation to interactive high-performance querying to visualization and analytics. CloudT30 comes with best-of-breed tools pre-installed and pre-configured to enable business users to solve business challenges immediately.
CloudT30 provides a data lake in the cloud in 30 minutes with the following industry-leading components:
- Cloudera – The modern platform for machine learning and analytics optimized for the cloud
- Data Prep – Self-service data preparation at scale with enterprise-grade security and governance
- Zoomdata – Cutting edge visualizations at scale
With CloudT30, business users can immediately load data into their data lake, prepare it, and visualize it without writing a single line of code.
To learn more about CloudT30 and how you can take it for a test drive, visit www.clarityinsights.com.
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read
Latest posts
