

Introducing DRUM Capabilities
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about DataRobot, AI Platform, data science, and more.
While data science education has always emphasized how to get the most from algorithms and data, it only recently began promoting the importance of model deployment. To get any value from your ML models, you need to get them deployed so that they can work with new data and make predictions.
Model deployment is at the core of getting value from your models. Traditionally, the tools and infrastructure for model deployment often required a new set of skills (like learning the Flask web framework) and had to be customized for every model. This added considerable pain to model deployment.
This article introduces DRUM, a platform-agnostic, open source framework (Apache 2.0 licensed) for deploying user and custom models. DRUM (DataRobot User Models) was built with the express intention of working with many different frameworks and platforms. This user model runner tool provides built-in support for testing and validating a wide set of machine learning models (R, Python, Keras, PMML, etc.) to ensure they’re ready for deployment.
For model deployment, DRUM provides a number of operations including:
- Performance testing to determine memory usage/loads
- Validation to determine if the model can handle missing values
- Batch scoring
- Creation of REST API endpoint for the deployment
- Creation of new model/environment templates
We’ll walk through an example process of using DRUM to deploy a simple model and provide us with a REST API endpoint for making predictions. We’ll see how to connect the endpoint to an app and how to use DataRobot MLOps to govern and monitor the deployment.
Using DRUM, we’re going to:
- Build the model.
- Test the model’s performance.
- Test that the model can handle missing value imputation.
- Perform batch scoring with the model.
- Deploy the model.
- Get a REST API endpoint for the deployment
We’ll connect the deployment to an app, and then remotely monitor and manage the deployment with DataRobot MLOps agent.
But First
- If you want to install DRUM, see requirements and usage documentation in GitHub or pypi. When ready, you can install DRUM with pip: pip install datarobot-drum.
- This article is written with the assumption that you’ll be following along by using the provided
- Also, the article explains how to use the DataRobot MLOps agent to manage and monitor the deployed model. If you are testing this workflow yourself and don’t already have a license for DataRobot, you can request a trial license here.
Building Your Model
You need to create your model. DRUM supports Regression and Classification models. Our example Main_Script notebook provides a process for building a very simple Scikit-Learn Regression model using the boston_housing prices dataset. The model exposes a predict method:

Since this is the model we want to use for deployment and predictions, we need to write it to disk. In our example, we use Pickle to serialize the model to disk.
Testing the Model
You can use the DRUM library to test how the model performs and get its latency times and memory usage for several different test case sizes.

Validating the Model
One more important step before scoring. You can validate the model to detect and address issues before deployment. It’s highly encouraged that you run these tests, which are the same ones that DataRobot performs automatically before deploying models.
For example, the following tests for null values imputation by setting each feature of the dataset to “missing” and then feeding those features to the model. (You can get test results from validation.log.)

Batch Scoring with DRUM
Now you’ll use DRUM to score the model artifact you just saved to disk. Batch scoring from DRUM is a useful technique for scoring data frequently or repeatedly; for example, if your process generates data each day, you can collect and score that data each night.
This sample batch scoring command:
drum score --code-dir /content/mlops-examples/'Custom Model Examples'/'Boston Housing'/src/custom_model --input /content/mlops-examples/'Custom Model Examples'/'Boston Housing'/data/boston_housing_inference.csv --output /content/mlops-examples/'Custom Model Examples'/'Boston Housing'/data/predictions.csv --target-type regressiontells DRUM to find the pickled model archive in /src/custom_model (code-dir) and use it to score the data provided at ./data/boston_housing_inference.csv (for target-type regression). Since this command loads DRUM with the model in addition to scoring the data, it takes a few moments to complete.
When finished, DRUM will output predictions to a new dataset, ../data/predictions.csv.
Note: You can use the command drum –help to see the arguments for DRUM and the supported syntax. Help is available for each of the arguments, for example drum score –help shows you supported arguments for supporting classification models, setting logging levels, view performance statistics, set to monitor predictions with DataRobot MLOps, etc.
When DRUM finishes, you’ll see predictions.csv in the specified output directory.
Deploy the Model and Get a REST API Endpoint
Now let’s use the new model to make predictions. For our purposes, we’ll host the model with DRUM and use it to set up the API endpoint. Then, we’ll spin up the server to host the model and make prediction requests.
By using subprocess.Popen to start the server, we can make requests to the server from this notebook.

The command run_inference_server instructs DRUM to serve the model. You can use this command when running models intended for non-production use (like a local Flask server) or for robust, production-grade use (e.g., using Nginx and uwsgi).
To get a REST API endpoint to the hosted model, we execute the following:
inference_server = subprocess.Popen(run_inference_server, stdout=subprocess.PIPE)
Now we can now ping the model via REST using GET http://localhost:6789/ to ensure it’s running at the designated address/port. There are endpoints also for predict and shutdown, for example:
POST http://localhost:6789/predict/
POST http://localhost:6789/shutdown/
Score the Data
We’re going to use the predict endpoint to score our dataset, which is passed to the model as form data (b_buf).
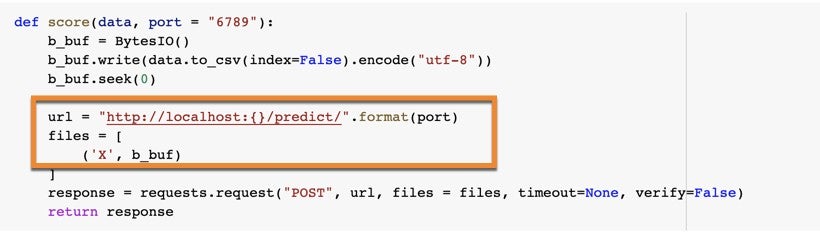
In the following example, the score function makes predictions using inference data from boston_housing_inference.csv.

The scored data, predictions, is returned as a JSON payload that can be used to request predictions and drive decisions and visualizations such as DataRobot MLOps monitoring tools.
Monitor the Deployment with DataRobot
Your job isn’t over once the model is deployed; so much can change that will affect your model’s ability to work effectively and make accurate predictions. Input data and data types may change such that the model doesn’t recognize the new data. Or maybe new variables arise that need to be included in scoring. Inevitably models go bad over time, resulting in unreliable predictions. Having the ability to monitor deployed models is essential.
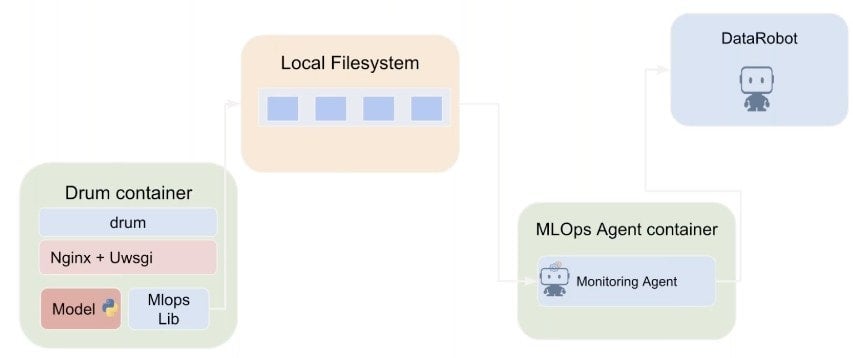
We can use DataRobot MLOps agent to keep track of the deployment and ensure it’s still providing value and making good predictions.
Note: JDK 11 or JDK 12 must be installed on the machine running the agent.
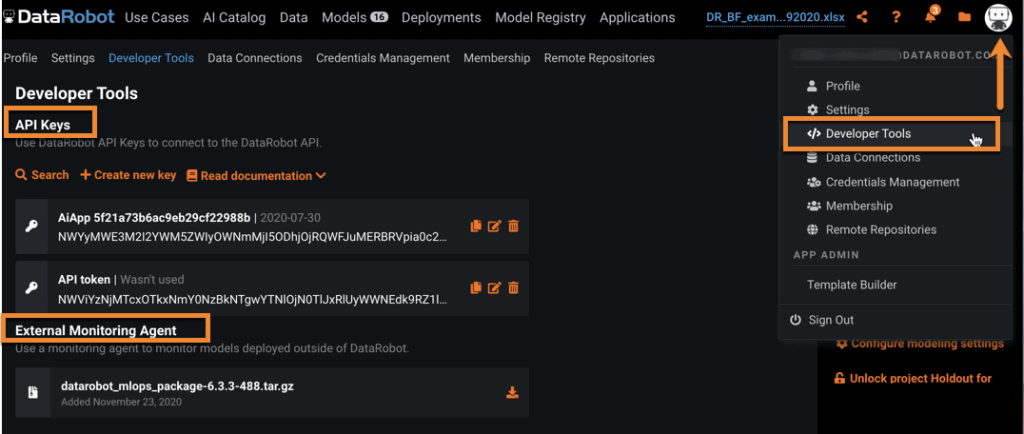
You download the MLOps agent and get your API key from the DataRobot UI. (If you don’t already have a license to DataRobot, you can request a license for AI Platform Trial.)
In the UI, navigate to Developer Tools (under your profile) and select to download the agent tar.gz. You also get your API key from this page.
Once the agent has been downloaded, upload the tarball to the Google Colab notebook environment.
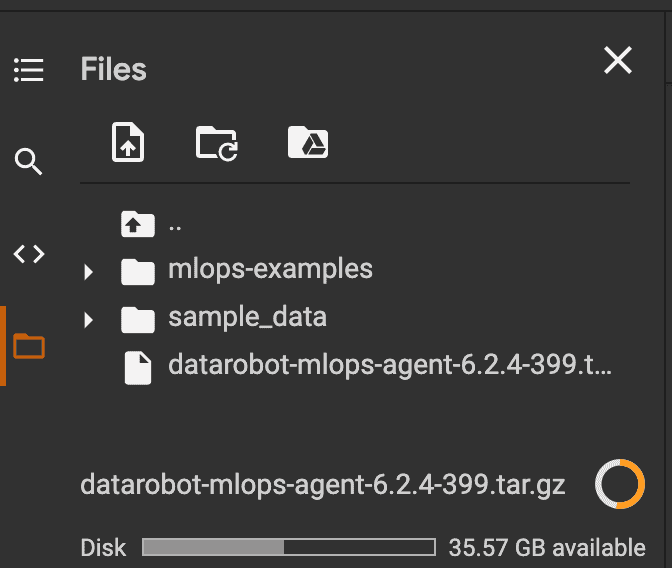

If you are connecting to the trial, you may need to update the name of agent tarball (for example, datarobot-mlops-agent-6.2.4-3999.tar.gz in this snippet) to match the name of the agent downloaded on your machine.
Then, configure the agent with the DataRobot MLOps location and your API key. By default, the agent expects the data to be spooled on the local file system in the location /tmp/ta. Since the notebook uses the default, you’ll want to make sure that location exists and create it if needed.
The following snippet shows how to configure the agent. Before starting it, make sure to replace endpoint with your MLOps instance and token with your API key. Also, as shown in the following code snippet our example is using version 6.2.4 of the agent; make sure you change this to the version you are using (from the agent download package).

Now you can start the agent service. To verify that it’s running and connected to DataRobot MLOps, you can review the mlops.agent.log.
To set up the external deployment on the platform, you need to install the DataRobot MLOps Python client that is included in the MLOps agent you download from DataRobot. You can install the client via pip install from within the notebook:

At this point you can define the deployment for DataRobot. This includes specifying the type of model, target name, description, etc. Using the specified model, the following code snippet will create a model package (along with the training data) in DataRobot MLOps and deploy it with data drift tracking enabled.
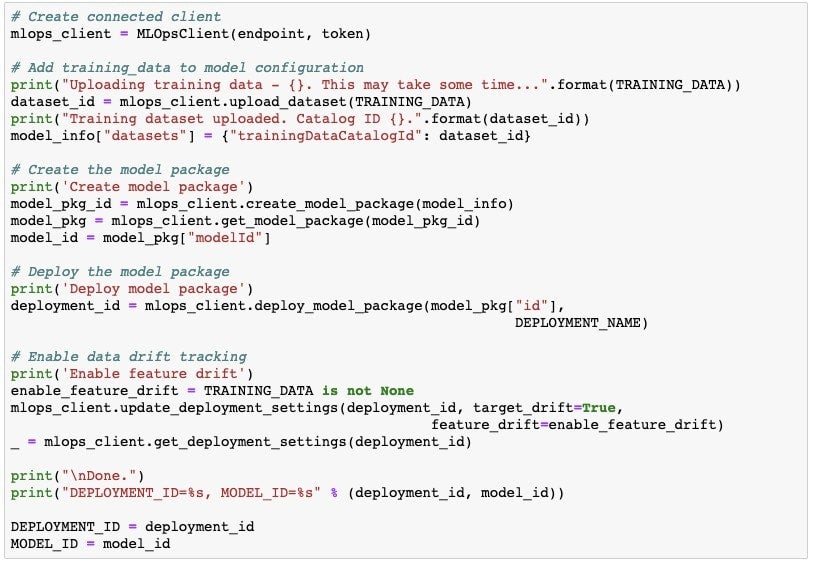
All information from the model and deployment is sent to DataRobot MLOps for monitoring. You can view this new, DRUM-hosted model in the DataRobot MLOps UI.
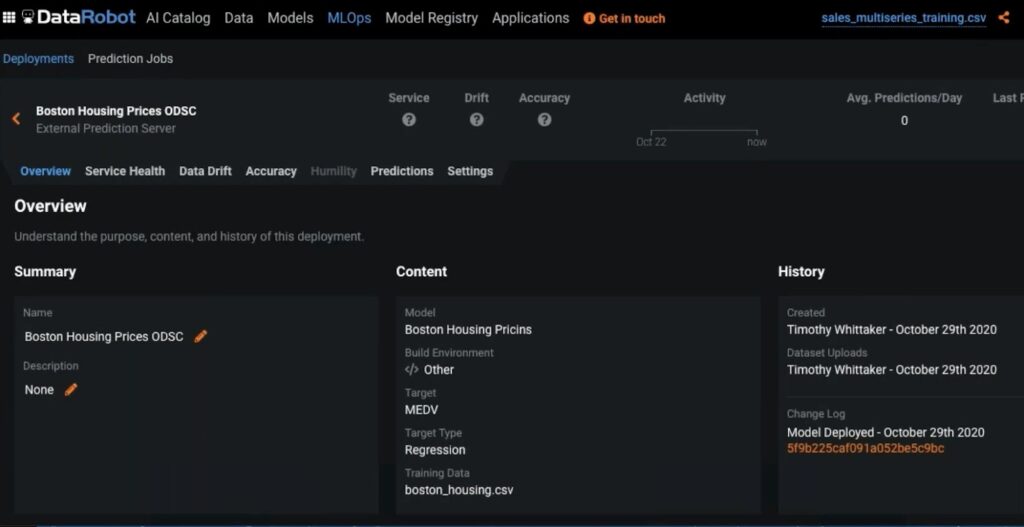
As new data arrives, the agent will process it and serve it up to DataRobot MLOps. As predictions are scored, you can use the monitoring tools to track for data drift.
Wrap Up
This post introduced you to the open source tool DRUM, which is key to ensuring models built outside of DataRobot (i.e., user and custom models) are ready to be deployed and can make predictions for your organization. You also learned how you can use DRUM to then get these models monitored via DataRobot MLOps.
Ready for More?
Once familiar with the basic DRUM workflow, you’ll want to check out what else you can do. As mentioned above DRUM supports several types of model artifacts out-of-the-box, including Python and R models based on the following libraries:
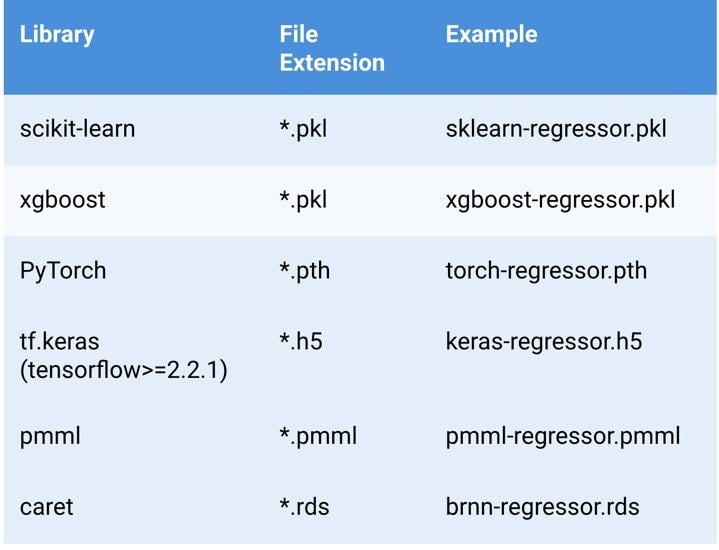
If your Python or R model was developed on a framework not shown in the table above, then DRUM also provides hooks for testing and validating custom models; instructions for this can be found in the DRUM GitHub README.
There are more features of DRUM for you to check out, including sophisticated model-loading features and support for model pre- and post-processing. You can find information and examples for using DRUM (and MLOps agent) in the DataRobot Community GitHub.
More Information
- GitHub has the instructions for installing and using DRUM.
- Using DRUM to deploy models was presented at this meetup, which is available as a YouTube recording.
- DataRobot Public Documentation > Custom Model Workshop

-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
