

Handling Text Data with State-of- the-Art Natural Language Processing Tools
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about the DataRobot AI Platform, data science, and more.
This article summarizes how DataRobot handles text features using state of the art Natural Language Processing (NLP) tools such as Matrix of Word N-gram, Auto-Tuned Word N-gram Text Modelers, Word2Vec, Fasttext, cosine similarity, and Vowpal Wabbit. It also covers NLP visualization techniques such as frequency value table and word clouds.
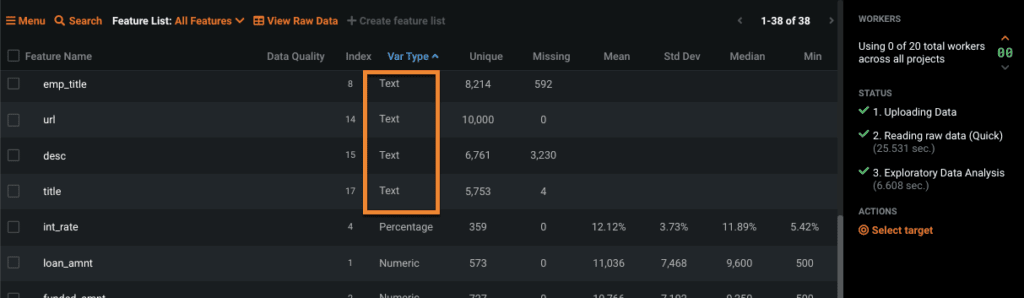
If your dataset contains one or more text variables, as shown in Figure 1, you may wonder whether DataRobot can incorporate this information into the modeling process. This article will show you just how it can.
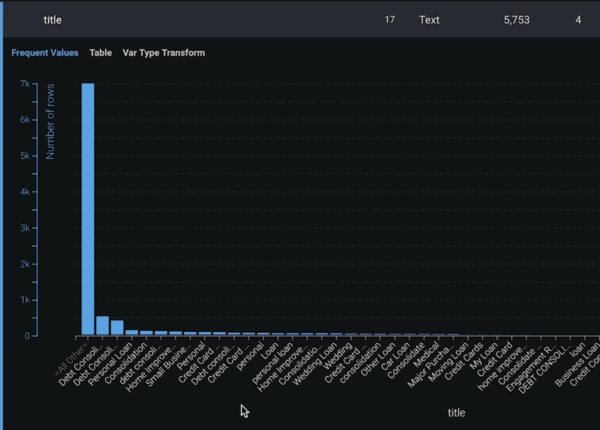
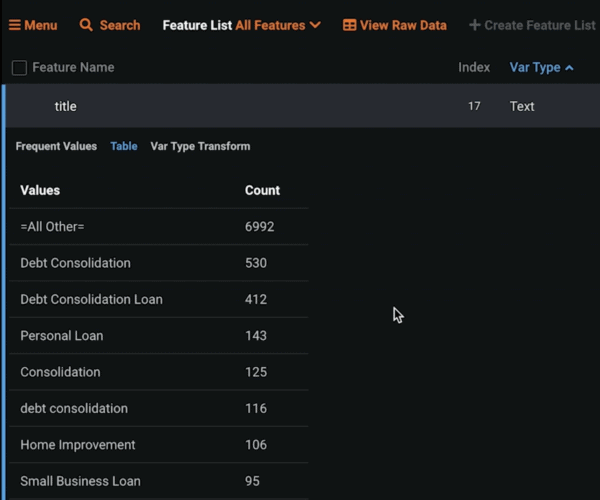
DataRobot lets you explore the frequency of the words by giving you a frequency value table, which is the histogram of the most frequent terms in your data and a general table where you can see the same information in a tabular format (Figure 2).
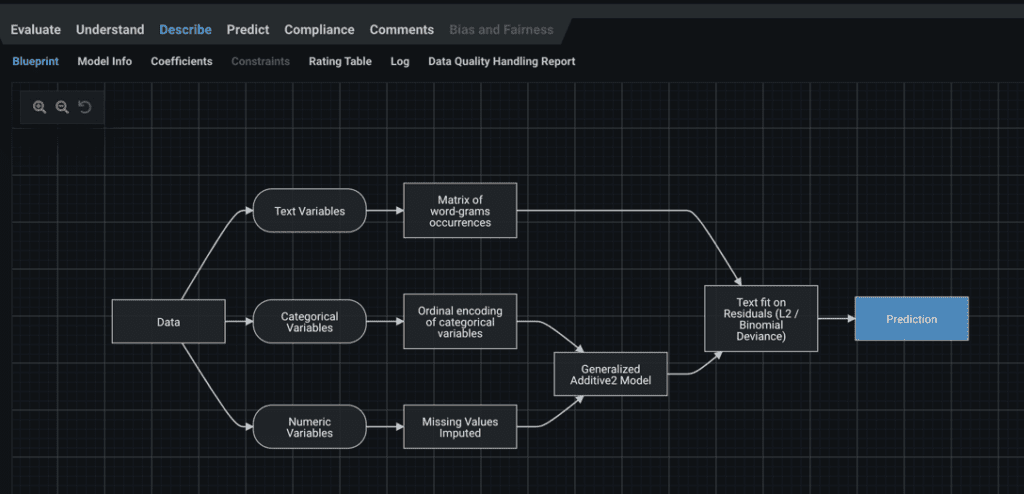
Let’s move on to modeling. DataRobot commonly incorporates the matrix of word-grams in blueprints (Figure 3). This is a matrix produced using a widely used technique, TF-IDF values, and combines multiple text columns.
For dense data, DataRobot offers the Auto-Tuned Word N-gram text modelers (Figure 4), which only looks at one individual text column at a time. The latter approach uses a single n-gram model to each text feature in the input dataset, and then uses the predictions from these models as inputs to other models.
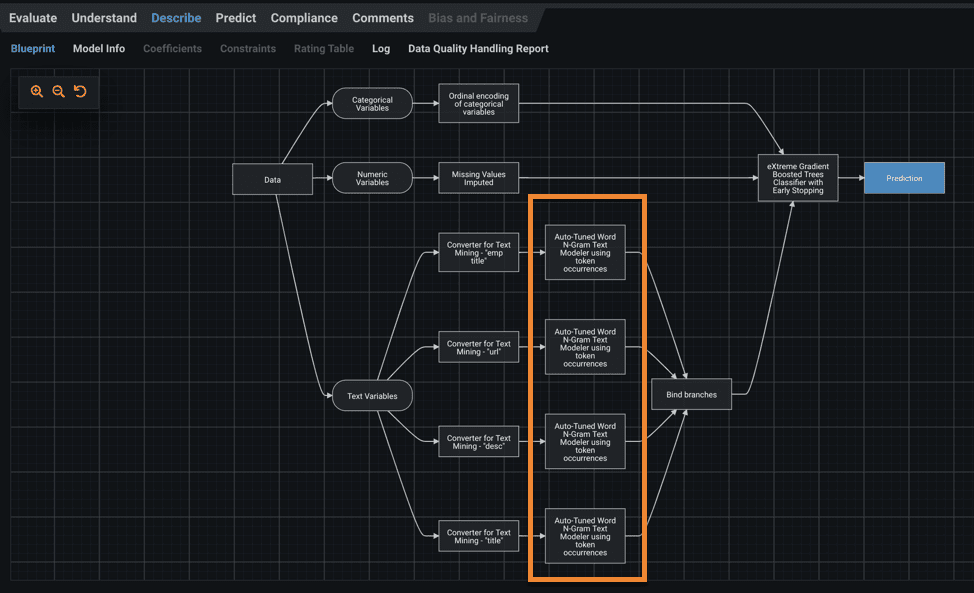
Auto-Tuned models for a given sample size are visualized as Word Clouds (Figure 5). These can be found in the Insights > Word Cloud tab. The top 200 terms with the highest coefficients are shown, along with the frequency with which each term appears in the text.
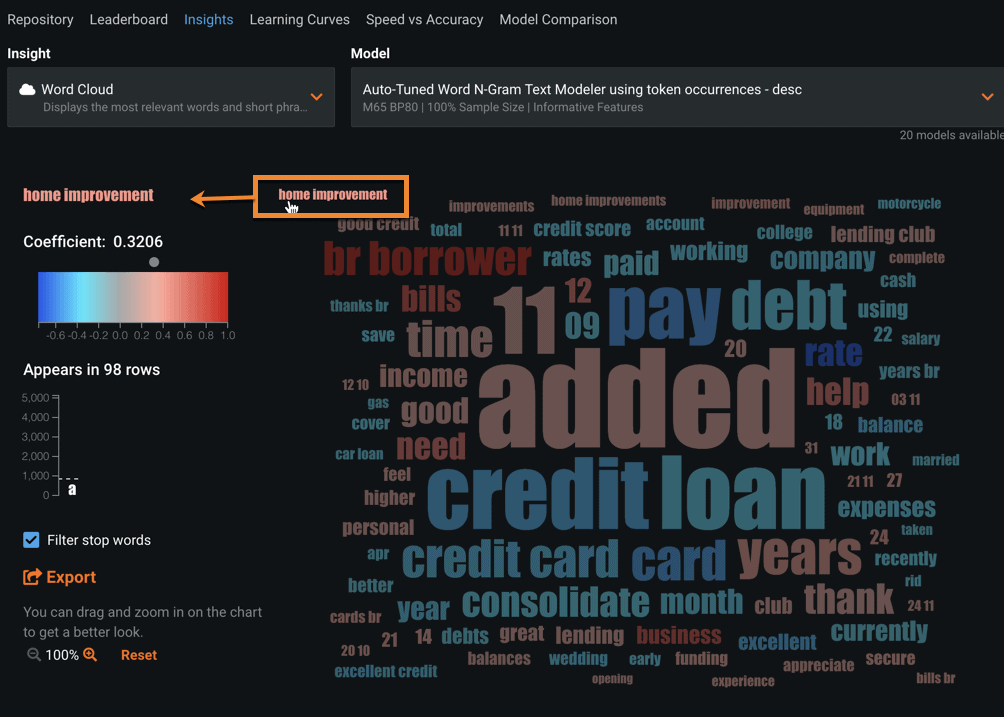
In Figure 5, terms are displayed in a color spectrum from blue to red with blue indicating a negative effect and red indicating a positive effect relative to the target values. Terms that appear more frequently are displayed in a larger font size, and those that appear less frequently are displayed in a smaller font size.
There are a number of things you can do to this display:
- View the coefficient value specific to a term by mousing over the term
- View the word cloud of another model by clicking the dropdown arrow above the word cloud
- View class-specific word clouds (for multiclass classification projects)
- Show or hide common stop words (the, for, was, etc.)
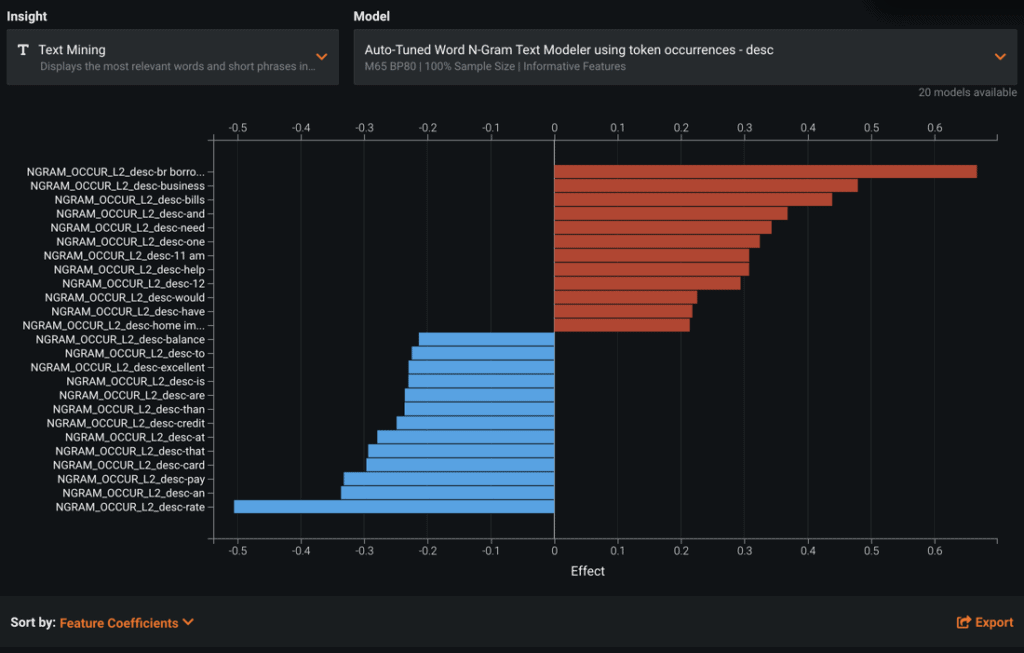
The coefficients for the Auto-Tuned Word N-gram text are available in the Insights > Text Mining tab (see Figure 6). It shows the most relevant terms in the text variable, and the strength of the coefficient. You can download all the coefficients in a spreadsheet by clicking Export.
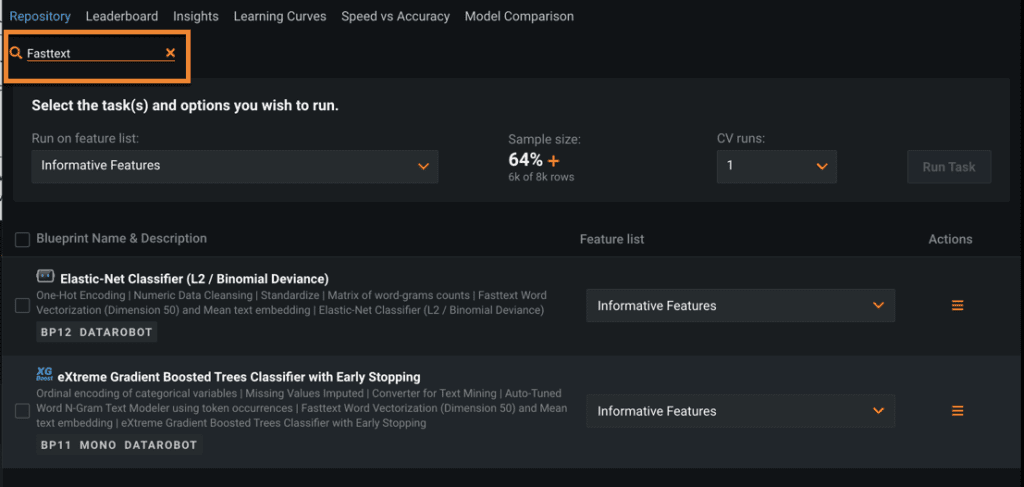
Finally, DataRobot also offers more NLP approaches in the Repository, such as Fasttext (Figure 7a). You can find those algorithms by typing ‘Fasttext’ in the search box; DataRobot will retrieve all blueprints that contain that preprocessing step.
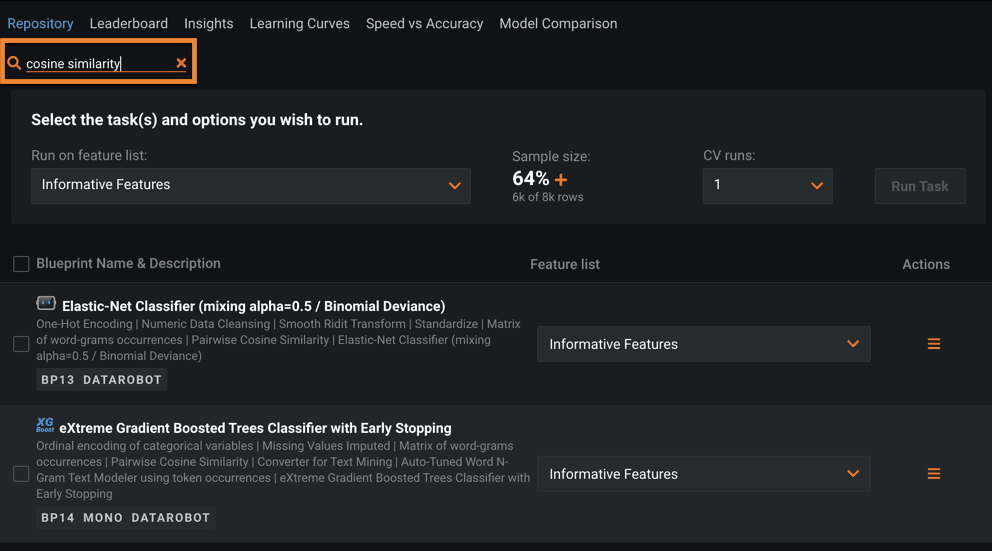
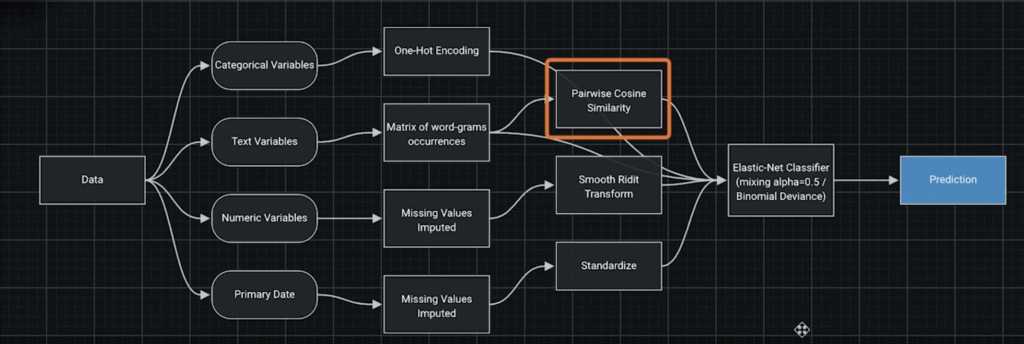
DataRobot also has other techniques such as cosine similarity (Figure 7b) when there are multiple text features.
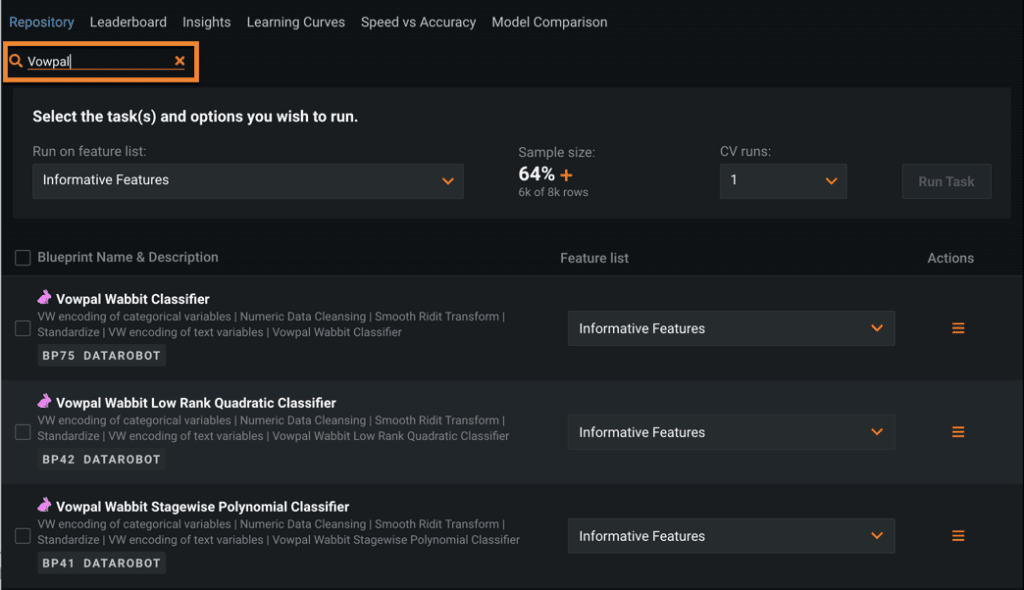
And Vowpal wabbit-based classifiers, which use use N-grams (Figure 8b).
Interested in learning more about DataRobot and its capabilities when it comes to text, as well as other data types? Reach out now for a personalised demo.

-
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read
Latest posts
