

Explaining Challenger Models in DataRobot
This post was originally part of the DataRobot Community. Visit now to browse discussions and ask questions about DataRobot, AI Platform, data science, and more.
Almost certainly, your deployed model will degrade over time. Inevitably, as the data used to train your model looks increasingly different from the incoming prediction data, prediction quality declines and becomes less reliable. Challenger models provide a framework to compare alternative models to the current production model. You can submit challenger models that shadow a deployed model, and then replay predictions already made to analyze the performance of each. This allows you to compare the predictions made by the challenger models to the currently deployed model (also called the “champion” model) to determine if there is a superior DataRobot model that would be a better fit. By leveraging the DataRobot MLOps Agent this capability is available for any production model—no matter where it is running and regardless of the framework or language in which it was built.
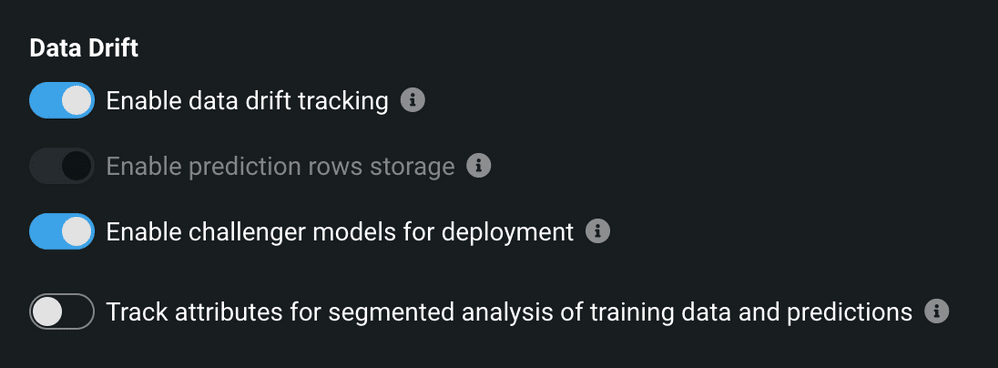
To support Challenger models for a deployment, you enable the Challengers option with prediction row storage. To do so, adjust the deployment’s data drift settings either when creating a deployment (from the Data Drift tab) or from the Settings > Data tab for an existing deployment. Prediction row storage instructs DataRobot to store prediction request data at the row level for deployments. DataRobot will use these predictions to compare the champion and challenger models.
Before adding a challenger model to a deployment, you first build and select the model to be added as a challenger. You can choose a model from the Leaderboard, or you can use your own custom model deployed within MLOps. In either case, the challenger models are referenced as model packages from the Model Registry and must have the same target type as the champion.
Feature lists for the current champion and the challenger models do not need to match exactly. However, to replay predictions the data passed at prediction time should be a superset of all features required for both the champion and challenger models. For example, if the training dataset for the champion was target, feature 1, feature 2, feature 3, and the training dataset for the challenger was target, feature 1, feature 2, feature 4, then the prediction request for replaying predictions should be: target, feature 1, feature 2, feature 4.
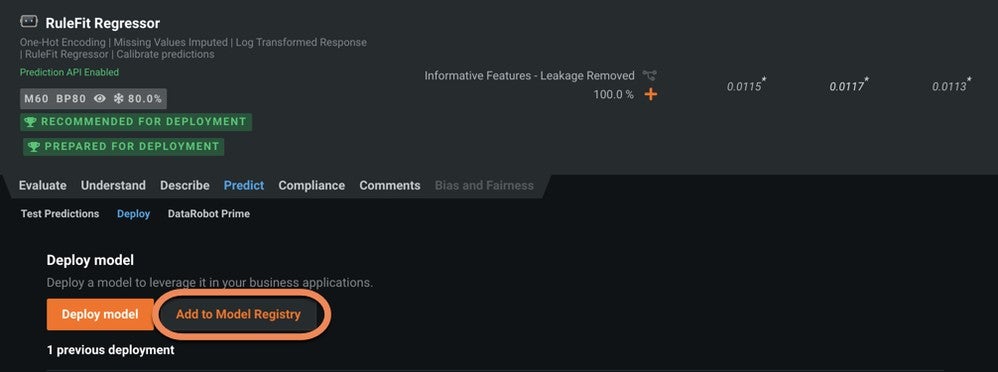
When you have selected a model to serve as a challenger, from the Leaderboard navigate to Predict > Deploy and select Add to Model Registry. This creates a model package for the selected model in the Model Registry, which enables you to add the model to a deployment as a challenger.
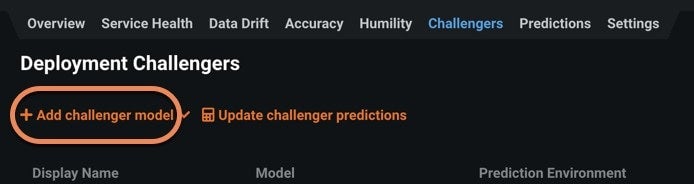
Now navigate to the deployment for the champion model, select Challengers, and click Add challenger model to add any challenger model. Choose the model you want from the Model Registry and click Select model package.
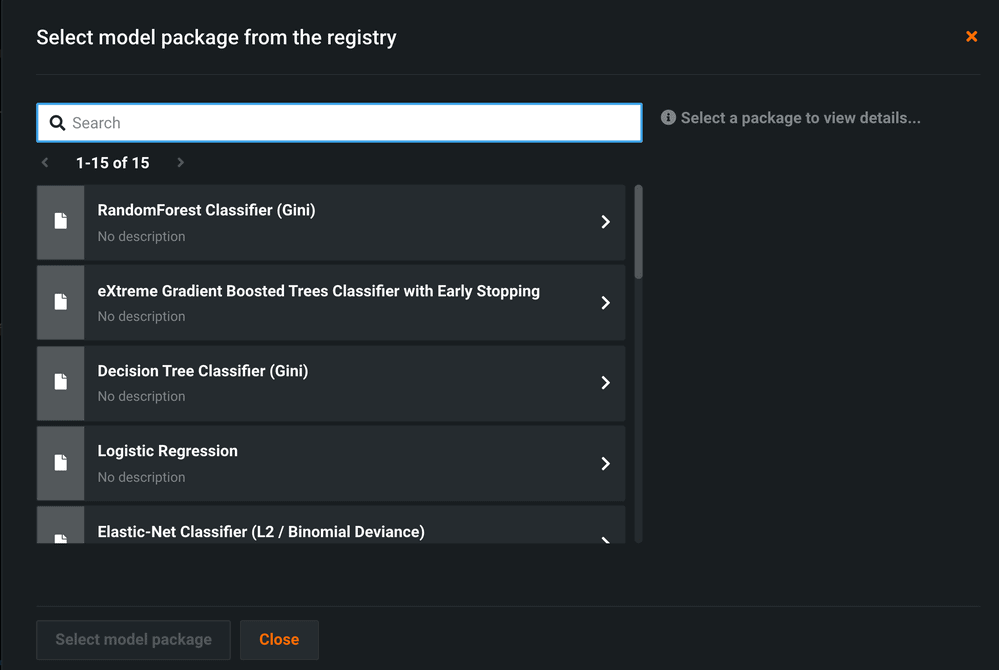
As the final step you assign a Prediction Environment for the challenger model, which specifies the resources to use for replay predictions. This allows DataRobot MLOps to avoid impacting production performance by replay predictions in an environment other than where the model is hosted.
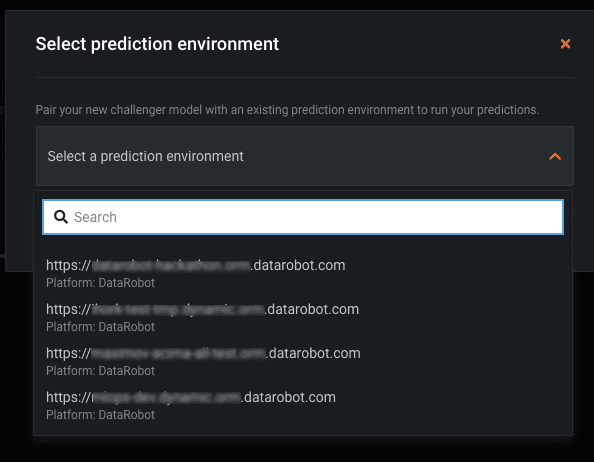
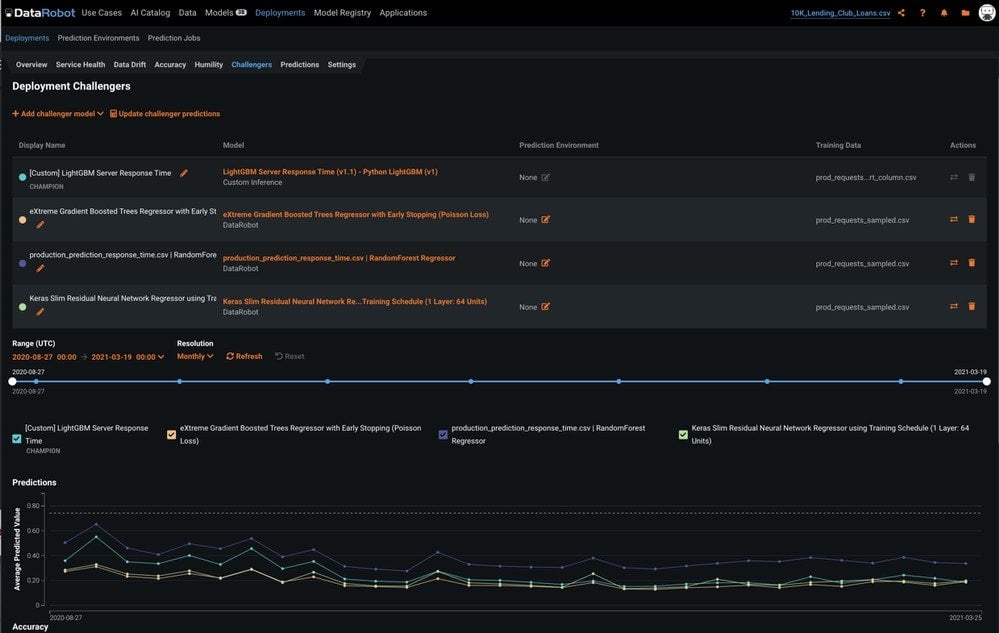
The Deployment Challengers tab shows the following information for the champion and challenger models:
- Model name
- Metadata for each model, such as the project name, model name, and the execution environment type
- Training data
- Actions menu to replace or delete the model
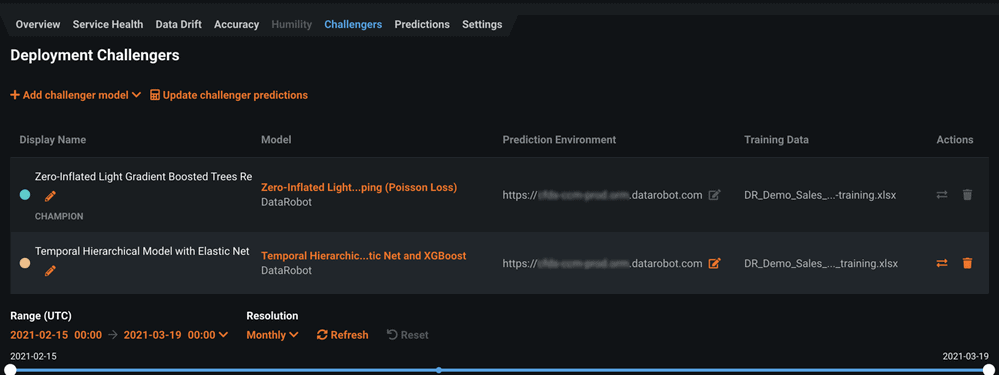
After adding challenger models, you can replay stored predictions made with the champion model. This allows you to compare performance metrics such as predicted values, accuracy, and data errors across each model. To replay predictions, select Update challenger predictions.

The prediction requests made within the time range specified by the date slider will be replayed for the challengers. After predictions are made, click Refresh on the time range selector to view an updated display of performance metrics for the models.

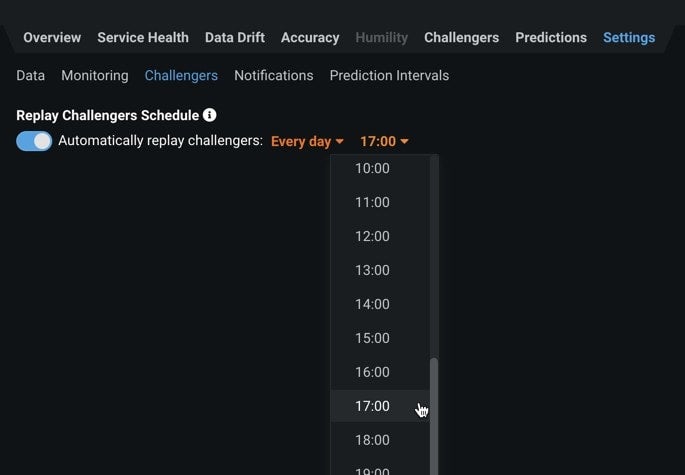
You can also replay predictions on a periodic schedule instead of doing so manually. Navigate to a deployment’s Settings > Challengers tab. Turn on the toggle to Automatically replay challengers, and set when you want to replay on predictions (such as every hour or every Sunday at 18:00, etc.).
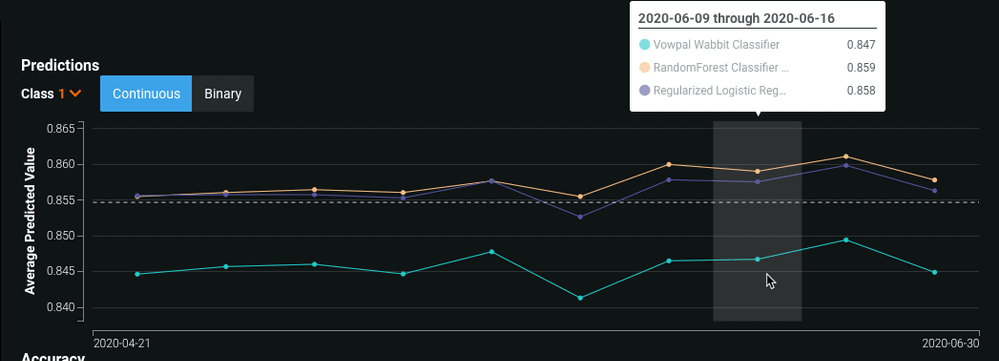
Once you have replayed the predictions, you can analyze and compare the results. The Predictions chart (under the Challengers tab) records the average predicted value of the target for each model over time. Hover over a point to compare the average value for each model at the specific point in time. For binary classification projects, use the Class dropdown to select the class for which you want to analyze the average predicted values. The chart also includes a toggle that allows you to switch between continuous and binary modes.
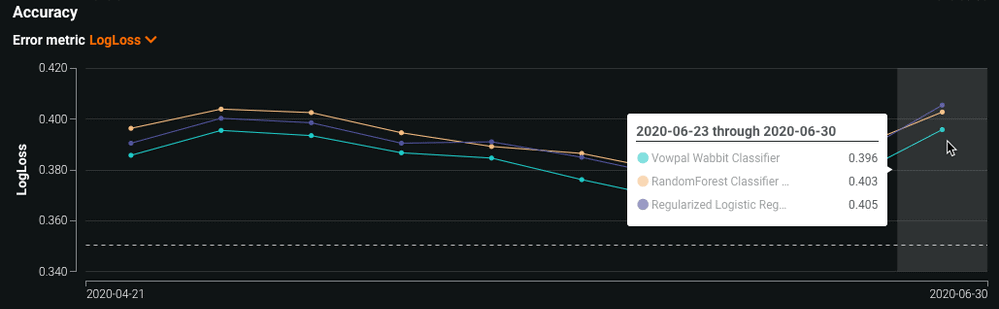
The Accuracy chart records the change in a selected accuracy metric value (LogLoss, in this example) over time. These metrics are identical to those used for the evaluation of the model before deployment. Use the dropdown to change accuracy metrics.
The Data Errors chart records the data error rate for each model over time. Data error rate measures the percentage of requests that result in an HTTP error (i.e., problems with the prediction request submission).
For more information on the MLOps suite of tools, visit the DataRobot Community for a variety of additional videos, articles, webinars and more.
More Information
See the DataRobot Public Platform Documentation for Challengers tab.
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
