


Building Paxata with Apache Spark
Shachar Harussi (a senior distributed systems engineer at Paxata) and I are happy and grateful that we got to share the lessons we learned while building the Apache Spark-based architecture for the Paxata platform today at Dataversity in Chicago. Thank you so much to the wonderful folks at Enterprise Dataversity!
I am excited to talk about this more next week at Strata NYC. Come by booth #301 to learn about how Paxata uses Spark and how we innovated and optimized Spark for data preparation. Here is a peek into what we talked about today:

How can a business analyst use Spark?
This was my favorite question during our talk. For context – Shachar and I described how the Paxata development team chose Spark from among other big data technologies, how we invested in Spark, and how we adapted Spark to create the interactive and scalable Paxata platform.
On top of the platform, the Paxata self-service data preparation app is where business analysts profile, manipulate transform, and cleanse data. In response to this question – every click, every action a business analysts takes in the Paxata app get compiled into Spark-specific transformations that are processed in the Spark layer, then the results are bubbled back up to the interface.
When a business analyst launches her browser and logs into the Paxata self-service data preparation app, she is interfacing with Spark! When she looks at 2 million transactions, or insurance claims, or leads, she is looking at the data like a spreadsheet.
This is what an analyst sees using Paxata data prep:
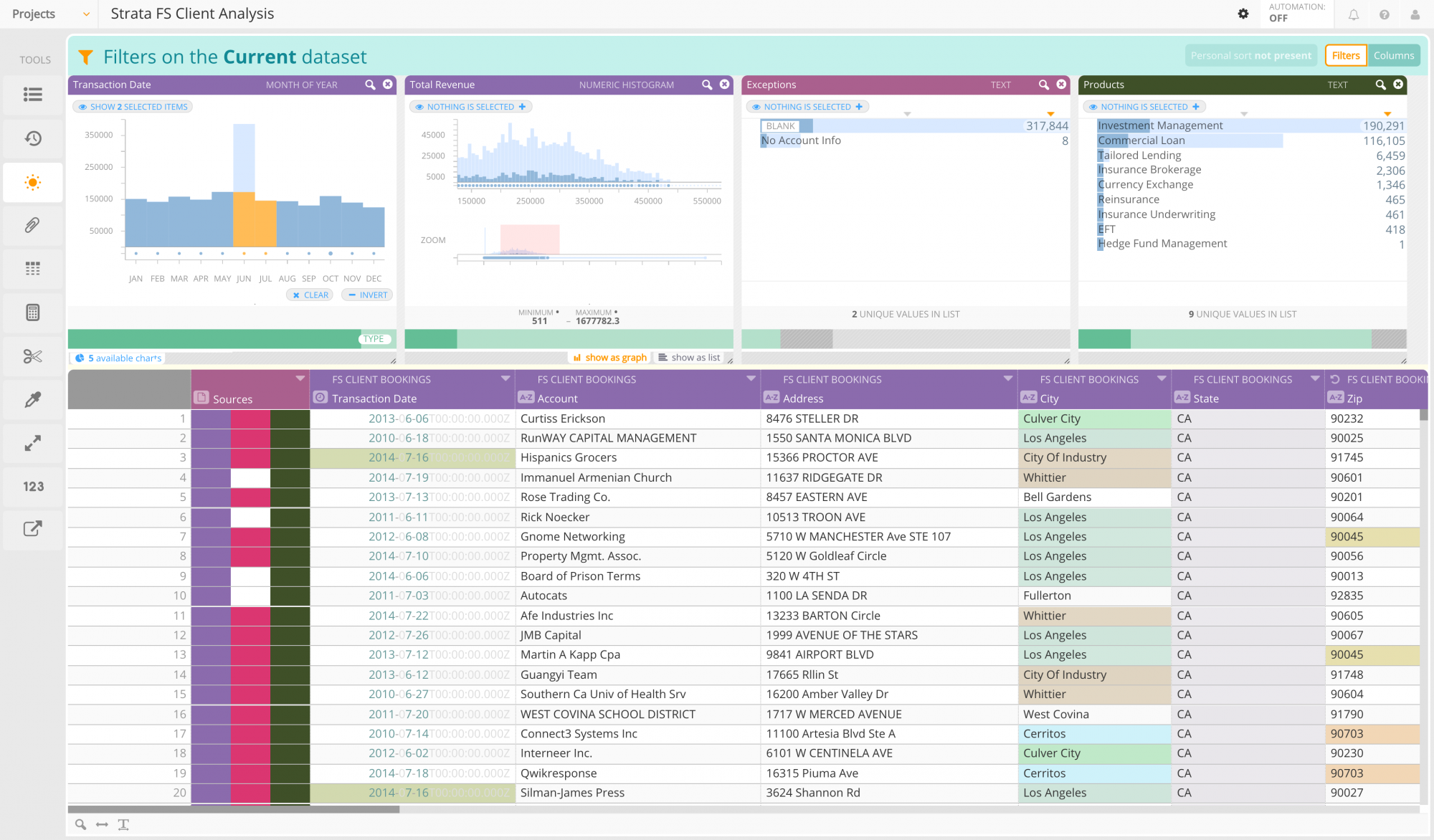
As she scrolls through her data, sorting, filtering, and reshaping it, she is actually using Spark. She isn’t using a commandline, she isn’t creating a script that she will then submit as a job somewhere (and wait, and wait). She is actively interfacing with her data, and her actions are being processed and understood with Spark. The Paxata platform enables business analysts to work with their data interactively and intelligently, thanks to a Spark-based computing layer and a spreadsheet-like user interface.
Paxata is built on Spark vs “Works with” Spark
We decided to build the Paxata platform on top of Spark — not compatible with Spark, but truly written for and with Spark — to provide a modern, dynamic, and experience for business analysts to see, explore, and fix all of their millions (and billions!) of rows of data. Spark is a crucial part of the powerful computing layer in the Paxata platform.
Sometimes companies advertise their “compatibility” with Spark. What does that mean? It could be that instead of producing direct results, they are producing a script, code, or a job that you will then have to execute and process somewhere separately. The Paxata platform is a unified solution – business analysts get all of their results immediately. Being compatible with Spark instead of being designed for and built with Spark means not taking advantage of the incredible distributed processing that Spark is designed for!
Thank you so much to the wonderful folks at Enterprise DataVersity!
Look for me at Booth #301 at Strata NYC – I look forward to talking to you about how we built our own system with Spark to accommodate the natural iterative and collaborative nature of true data preparation. Learn more about Paxata at this session with analysts from Citi, Standard Chartered Bank (SCB) and Polaris discussing how they use Paxata to analyze transactions and behaviors looking for indicators of money laundering, fraud and human trafficking.
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
