

DataRobot’s Automated Deep Learning for Tabular Data
At DataRobot, we meticulously test all the models we build on thousands of real-world datasets to ensure they meet our customers high expectations across performance, generalization, and reliability. There’s no denying that tree-based methods — especially boosting models — have dominated our leaderboards when it comes to traditional data types in rows and columns, aka tabular data. This has begun to change.
DataRobot is known for its enterprise AI platform which democratizes data science with end-to-end automation for building, deploying, and managing machine learning models. It also provides powerful automated insights to provide transparency under the hood. Given the wide variety of algorithms and modeling approaches already in the DataRobot repository, we asked ourselves the question: “Can deep learning models beat boosted trees on real-world business data?”
DataRobot 6.0 Makes Deep Learning Practical
DataRobot runs a wide variety of modeling techniques, using different types of models, with different approaches to preprocessing and ensembling. This works well for different use cases and datasets (remember the no free lunch theorem). Now in our latest release we have supercharged our automated deep learning capabilities to take your AI to the next level.

In DataRobot 6.0, building successful and reliable deep learning models couldn’t be easier.
With the help of open source projects such as Keras and Tensorflow, DataRobot has delivered a new suite of deep learning approaches that are 100% ready to deploy into production. We built them from the ground up using a novel architecture to improve performance and accuracy, and we’ve managed to improve top-model accuracy on 8% of datasets in our repository of internal benchmarks. These models are applicable to a variety of problems, but perform especially well on datasets with text as a major component.
One example of a tabular dataset that we’ve seen out-of-the-box neural networks perform poorly on in the past is Micro Mass Mixed, mass-spectrometry data which presents a multiclass classification problem of identifying microorganisms. On OpenML, the task with the most evaluated models (64) shows neural networks consistently under-performing, achieving between 30-50% accuracy. Up until now, with no manual feature engineering, our out-of-the-box MLP achieved a cross-validation balanced accuracy of ~76%, while a gradient-boosted tree with 500 estimators achieved 96.5% cross-validation balanced accuracy. Our new default Keras model, which will run as part of autopilot, achieves 96.6% cross-validation balanced accuracy, topping our leaderboard. Neural networks still don’t consistently top the leaderboards on tabular datasets, but with our recent work, they have become much more competitive.
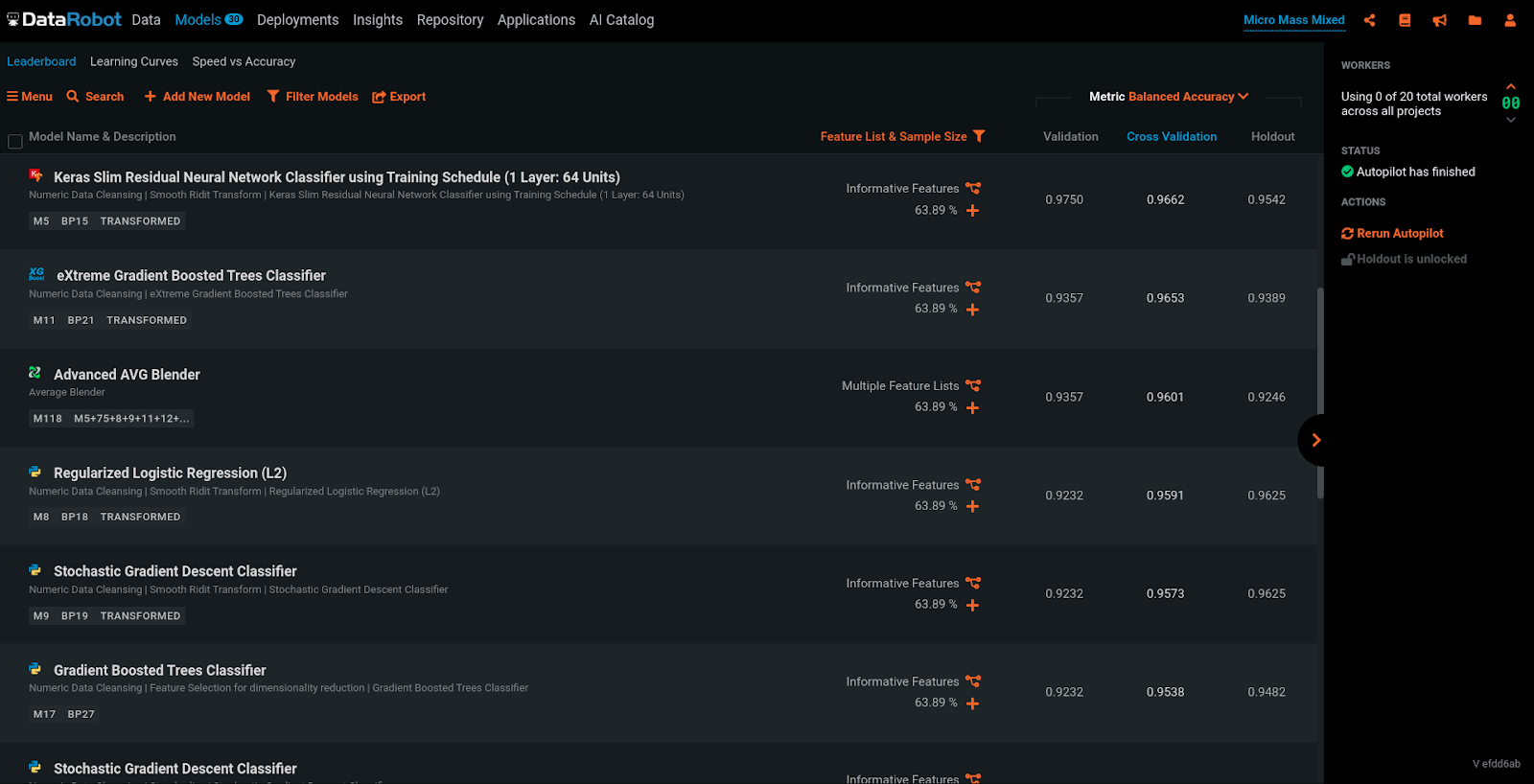
Every day we are iterating on our deep learning models, all made with heuristics automatically tailored for the user-provided dataset. We’re reading papers, exploring novel ideas, and implementing state-of-the-art techniques, such as the 1cycle learning rate policy, skip connections, and even some tricks we’ve come up with ourselves, like automatically determining which loss function, activation functions, learning rates, and batch sizes to use. At DataRobot, we are actively exploring and building ways to provide insight into deep learning models both during and after training, to help business users and data scientists alike get the tools they deserve for working with deep learning models.
Helping You Demystify Deep Learning
Understanding deep learning models is difficult. DataRobot makes it easy. Training deep learning models is expensive and time-consuming. DataRobot only needs commodity hardware and allows you to get started with way less effort compared to alternative tools. Deep learning shouldn’t be difficult. With DataRobot, it isn’t. It just takes a few clicks to find a fast and accurate model, ready to be deployed or tuned.
If you are not sure where to start with the plethora of hyperparameters or find yourself just using the last model you tuned for a new dataset, DataRobot will find a good starting point for you, and you can iterate from there. DataRobot makes tuning and optimizing hyperparameters easy. You can customize a learning rate schedule, batch size, the network architecture (layer count and size, activation functions, dropout, batch norm, initialization, etc.), the loss function, the optimizer, and the list goes on and on. And of course, leverage DataRobot’s automatic preprocessing (optimized for deep learning models), just like every other model built with DataRobot.
If you would rather not spend time finding benchmarks to compare your models against, DataRobot has a whole library of blueprints to provide competitive benchmarks ready for you. It also has all kinds of valuable and human-friendly insights that will assist with feature selection and generally gaining a better understanding of the potential of your data.
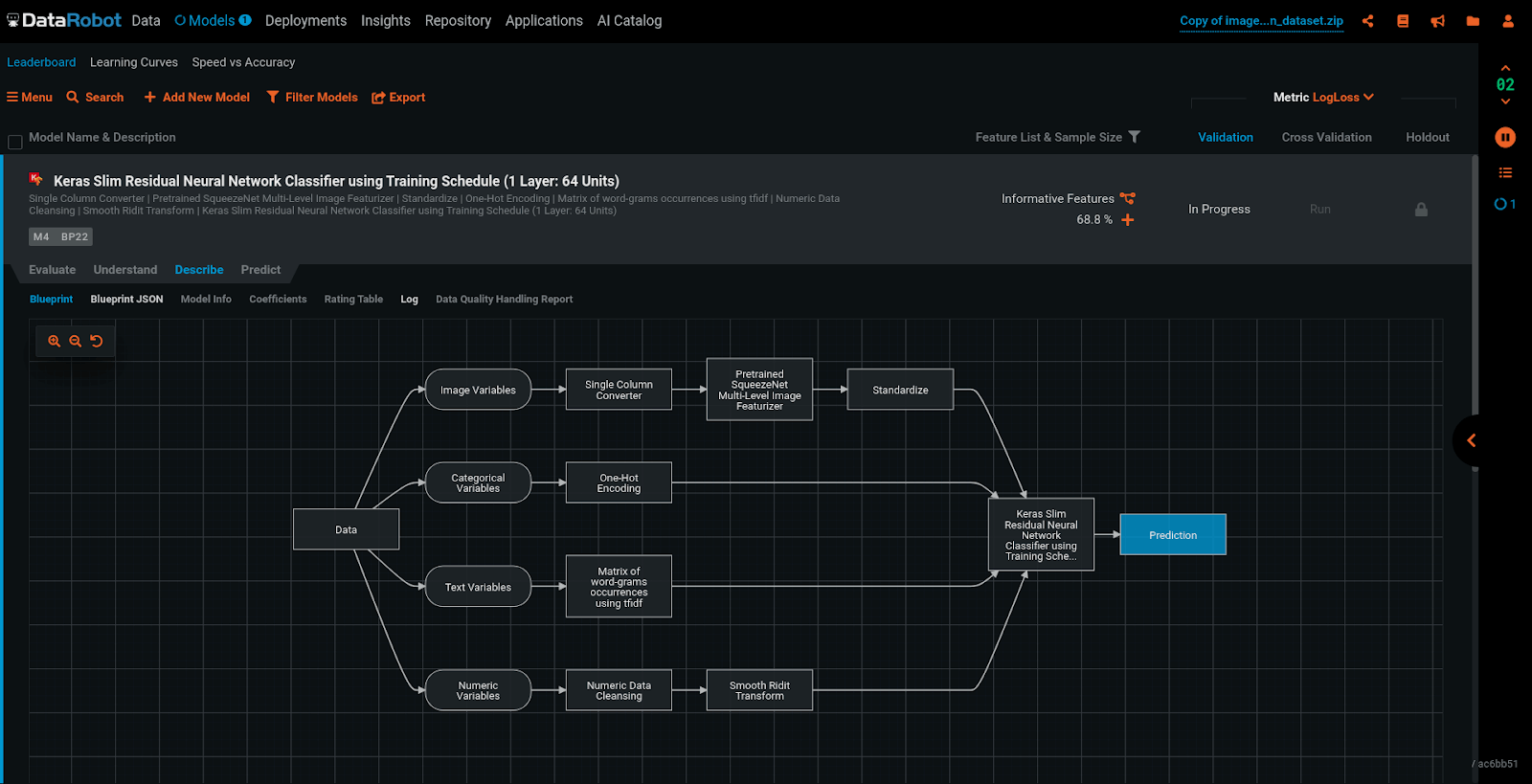
The Best Models. Blended
A deep learning model isn’t always the right tool for the job, so don’t force it. Pick the model that best fits your needs. An important thing to remember, however, is that a neural network can help diversify an ensemble model, so don’t dismiss it before seeing how the top model and your deep learning model perform together.
You don’t need to be an expert at building every type of model- DataRobot does the work for you. Just focus on tuning the most familiar models, either way, with a few clicks, make a fantastic ensemble.
Deep Learning, Ready for Production
As with any model in DataRobot, you’re able to compare the complexity, explainability, speed of inference, size, and heuristics across all models built to make sure the best model for your needs is deployed. You can look at lift charts, ROC curves, confusion matrices, feature impact, partial dependence, prediction explanations, a visualization of each neural network, and more to ensure the model is solving the right problem. You can specify a random seed, or let DataRobot specify one for you, to ensure your model provides consistent predictions. Once you’ve found the best model for the job, deploying and monitoring it is just a click (and if a user-interface isn’t right for you, DataRobot has a well-documented, actively developed API, and you can use it instead).
Production-ready Deep Learning has never been easier.
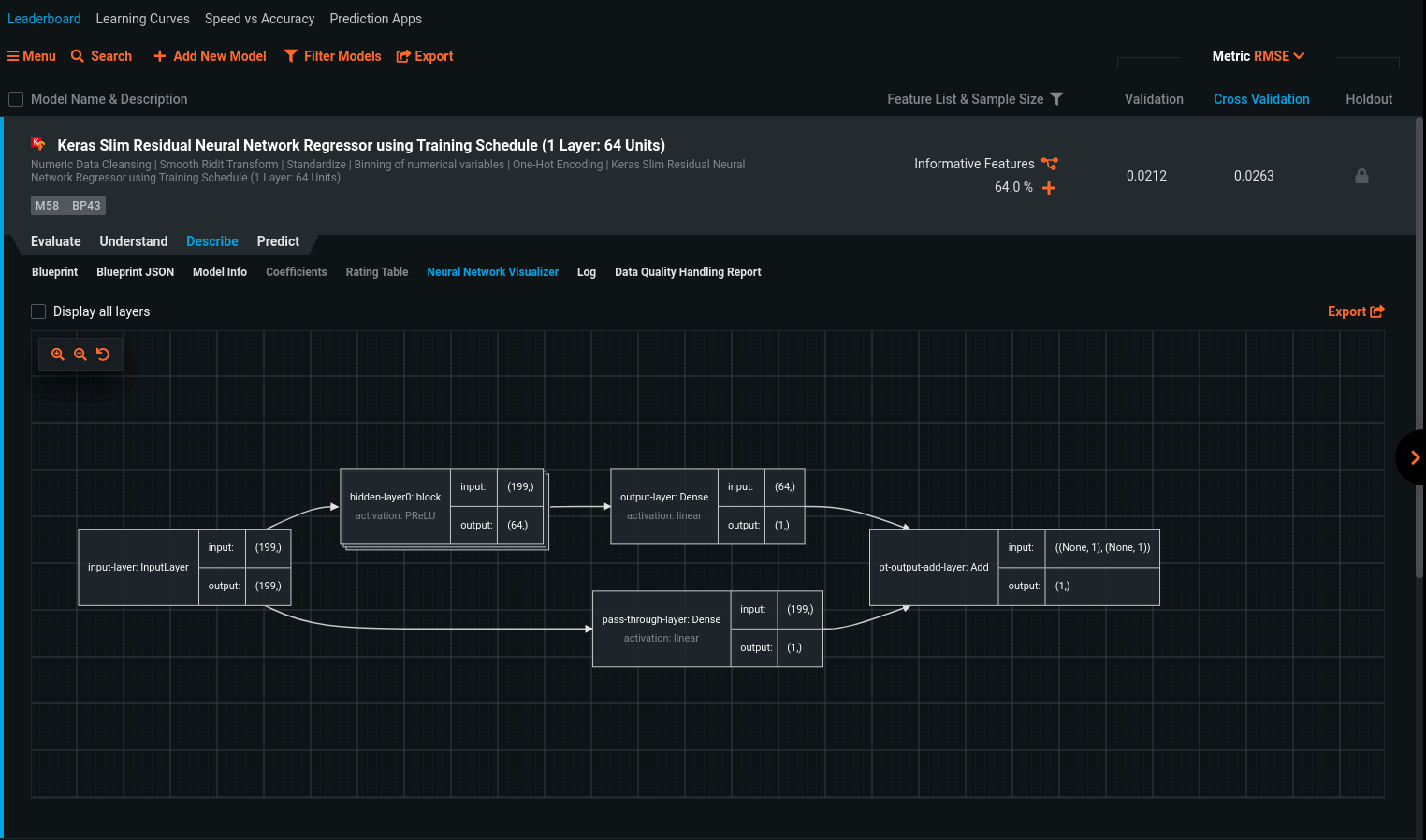
Conclusion
Neural networks are notoriously difficult to tune, which dissuades many practitioners from trying to utilize the value they can provide. At DataRobot, we’ve made significant progress in automating the training and design of neural networks in order to provide users with a powerful new tool in their machine learning arsenal.
We’ve conducted numerous experiments on a wide variety of datasets and found that neural network based approaches, if appropriately tuned, can be highly competitive with boosted tree models and other classical methods. Blending multiple approaches ensures the highest possible accuracy, and we’re excited about how diverse our ensembled models have become.
But we’re not stopping here. Each day, we work towards improving our approach to designing and training neural networks, and the insights and features we provide alongside them, in order to provide the best experience possible for DataRobot users. So stay tuned for even more automated deep learning innovation with every new release!


Jason McGhee is a Senior Machine Learning Engineer at DataRobot, primarily focused on neural networks and deep learning. Jason has a background in leading and building top quality products, previously co-founding Cursor, acquired by DataRobot, and serving as a Senior Software Engineer at Pandora Media. He has a computer science degree from UC Berkeley.
-
How to Choose the Right LMM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
