

DataRobot Solution for the 2014 KDD Cup
Kaggle competitions are a great means of sharpening your data science skills by getting exposed to challenging problems and a variety of domains and datasets. At DataRobot we use Kaggle competitions not only to hone our skills, but also to test out the platform we’re building.
We’re excited to announce that team DataRobot placed 2nd out of 473 teams in one of the most prestigious data science competitions, the 2014 KDD Cup Challenge! This blog describes our solution and the insights that propelled us to the “in the money” position on the leaderboard.
The Competition
This year’s competition featured a very interesting data science problem, and for a great cause. DonorsChoose.org is an online charity that makes it easy for anyone to help students in need through school donations. At any time, thousands of teachers in public schools across the US propose projects requesting materials to enhance the education of their students. When a project reaches its funding goal, DonorsChoose.org ships the requested materials to the school. In return, donors get to see photos of the project being implemented, a letter from the teacher, and insight into how every dollar was spent.
The 2014 KDD Cup asked participants to help DonorsChoose.org identify projects that would be especially exciting to donors, at the time of project submission. Identifying exceptional projects early will help DonorsChoose.org improve funding outcomes.
In order to predict how exciting a project is, Kaggle provided data on projects, resources, donations to different projects and outcomes for projects, including whether a project was “exciting.” Projects posted until the end of 2013 were included in the training set, whereas the test set consisted of known outcomes from January through mid May 2014. Kaggle ignored “live” projects in the test set and did not disclose which projects were still live to avoid leakage regarding the funding status.
DataRobot Solution
We first used DataRobot to rank all applicable techniques and different subsets of features for the training dataset, and Gradient Boosting Machine floated to the top. We’ve built DataRobot exactly for this purpose, to be able to find the best algorithm to model the problem.
Based on this insight, we created our open-source solution on sklearn’s Gradient Boosting Regressor and the R Gradient Boosting Machine (gbm) package. We used both R and Python GBMs because they offer different tree building strategies.
We built 2 feature sets to feed our gradient boosting models: one that includes a lot of features on teachers’ past projects and donations where there is sufficient history, and one that we designed for teachers with low project history. This last set includes more features on the projects and more advanced techniques (regularized GLM with n-gram inputs) to extract information from the text posted by teachers and the name of the most expensive item in the project.
To build our history features, we sliced time into chunks of 4 months, computed statistics for each chunk and used as features the stats of the last 3 chunks prior to the time chunk of the project. The stats that we computed are based on past projects posted by teachers, donations received by teachers, donations made by teachers and donations made by the zip, city, state of the project.
Our first insight was that 2013 outcomes were enough to produce good models. This gave us significant gain in computation time without much loss in predictive accuracy.
Later in the competition, we observed that the time distribution of the Public and Private Leaderboard differed significantly and the most recent (April and May) projects were absent in the Private Leaderboard. Based on this insight, we knew we couldn’t base our solution only on the Public Leaderboard feedback but needed to build a solution that would perform well for both Private and Public Leaderboards.
We made the assumption that the mid-May cutoff in the test set produces a censoring effect on the response and we expected this effect to be much stronger for the most recent months. To reproduce the “assumed” time effect on the response in the training set, we censored the response before training our models and created 2 types of censored outcomes: exciting outcomes censored at 3 cutoffs drawn randomly, and exciting outcomes censored every week during the first 20 weeks.
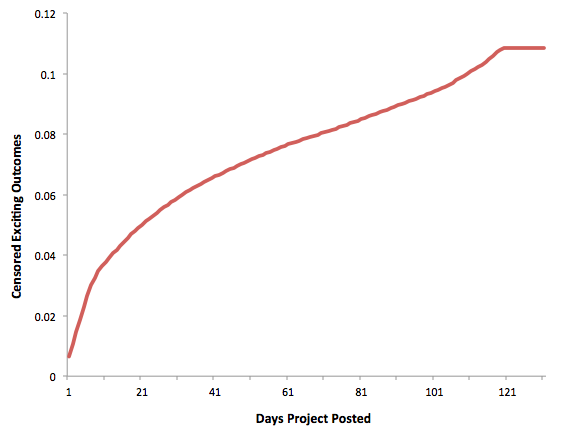
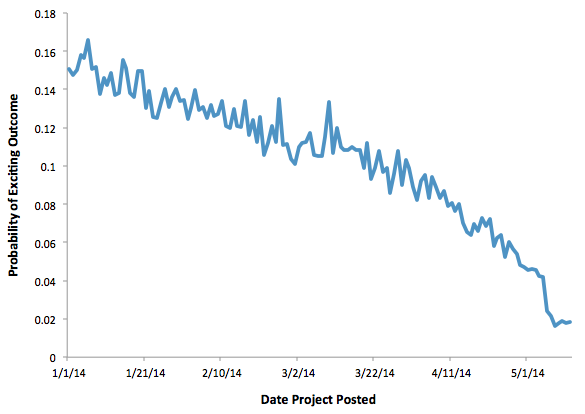
This second insight and the fact that we censored the response in the training set before training our models was key to our performance in the competition.
You can find more details of the feature engineering we did and specific tuning parameters for the models we used in the detailed write up and the code we provided to Kaggle.
As an Aside …
We were surprised by the fact that features based on donations made by teachers were more predictive than features based on donations received by them. In particular, we observed that when one teacher donates to exciting projects, she is more likely to post exciting projects herself. We hope DonorsChoose.org can use this insight in interesting ways, such as sharing insights on projects teachers donated for. This could help teachers learn more from other projects and improve the quality of their own submissions!
Conclusion
Kaggle competitions in general, and prestigious ones such as the KDD Cup in particular, are excellent opportunities to learn and improve your data science skills. These competitions also give us a phenomenal opportunity to put DataRobot into the mix and test its chops.
At the end of the day, the combination of our insights and the speed of DataRobot proved very powerful indeed. DataRobot gave us a very good head start in deciding on the optimal modeling method to use. (In fact, a blend of the best model created by DataRobot and the open source model we submitted yielded an even better score of 0.685 on the private leaderboard!) We also determined along the way that time created a strong bias in the dataset that you needed to account for in the model. These were the keys to our success in this competition.
We are making great progress in getting DataRobot ready for primetime, to give every Kaggler and data scientist an “unfair advantage.” Stop by and see us at KDD 2014 in New York, New York. Until then ..


As Data Science Engineering Architect at DataRobot, Mark designs and builds key components of automated machine learning infrastructure. He contributes both by leading large cross-functional project teams and tackling challenging data science problems. Before working at DataRobot and data science he was a physicist where he did data analysis and detector work for the Olympus experiment at MIT and DESY.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
