

DataRobot MLOps 6.0 is Now GA and Packed with New Capabilities
Deploying models into production remains a critical challenge for organizations adopting AI. For many custom-built models, deployment requires extensive data science knowledge and coding expertise to promote those models from development to production. With varied languages and frameworks across AI teams and projects, deployment becomes even more challenging and specialized, depleting critical resources from data science and IT teams alike.
With deployment being such a challenge, it is no surprise that many organizations struggle to operationalize their models and realize ROI. To compound the situation, even those organizations who are lucky enough to get models up and running, still face serious challenges. This is because the entire process is incredibly resource-intensive, and comes at the expense of other critical needs like effective monitoring and governance. Quite often the sheer complexity associated with consistent monitoring and governance across a variety of model types and alternative runtime environments seems like an impossible challenge to overcome.
DataRobot MLOps 6.0 has been specifically designed to address these challenges. It simplifies the deployment and monitoring of models built in a variety of languages across many different runtime environments.
Unified Model Registry for Enterprise AI
In Release 6.0, MLOps provides a single place to register all your models regardless of their origin or deployment location. The Model Registry provides a unified deployment experience for your machine learning models across the entire enterprise. This allows you to deploy, replace and manage models in a single place.
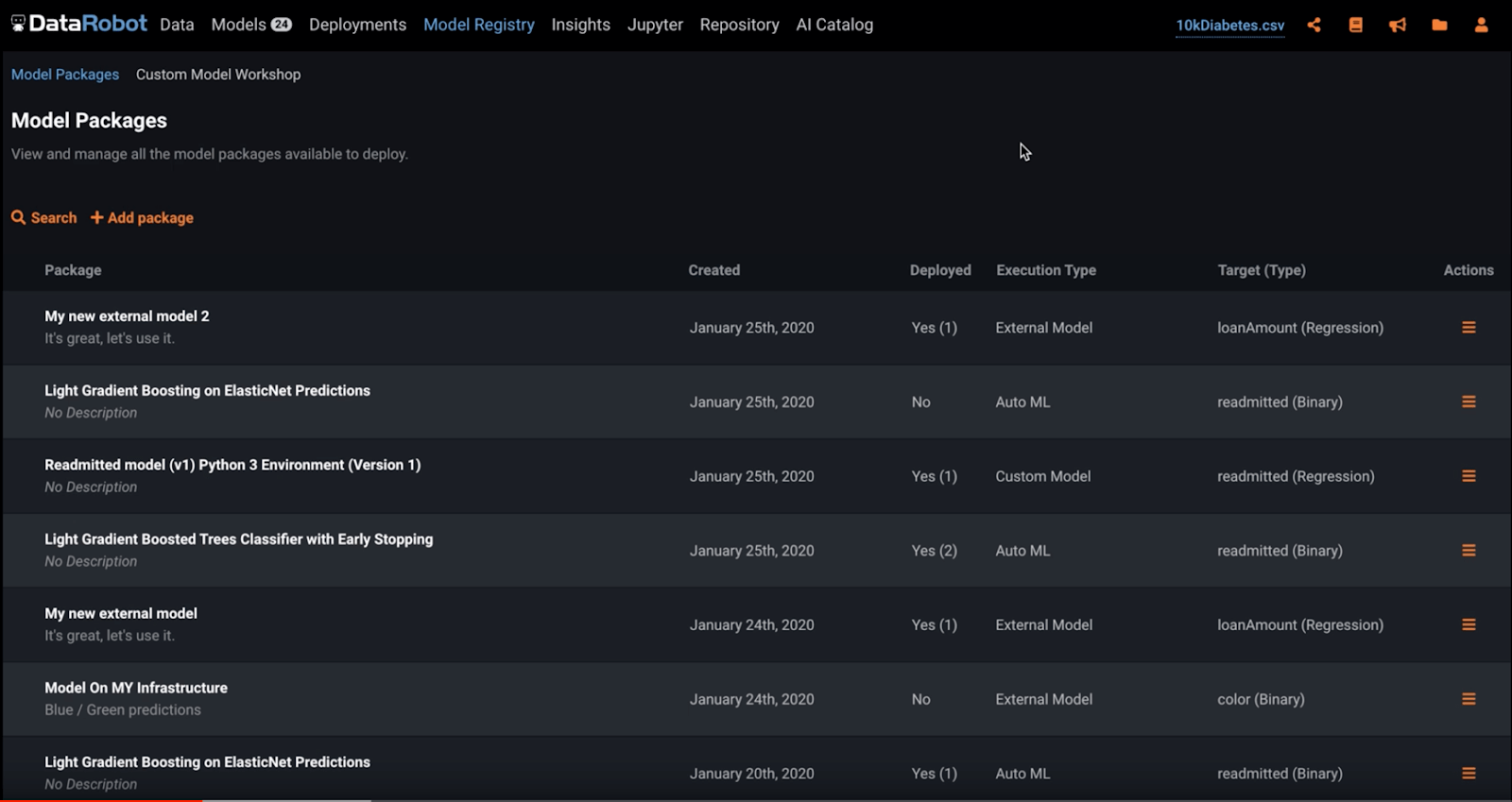
Model packages are automatically added to the registry when a deployment is created or you can manually add a new package to the list. Model packages are available for custom models (i.e. not built with DataRobot), remote models (i.e. deployed outside DataRobot), imported AutoML models (as .mlpkg files), and local AutoML/TS models right from the Leaderboard. This provides a consistent and streamlined user experience once models are registered, regardless of where they were trained or where they are deployed.
Move AutoML and AutoTS Model Packages Between Environments
In addition to the unified Model Registry, if you are working with models built in DataRobot, in Release 6.0 you can also easily export and move model packages between DataRobot environments too. Users can easily transfer a “.mlpkg” between development, test, QA and production instances of DataRobot without sacrificing functionality. When you import a model package into MLOps, it is preconfigured with business critical MLOps capabilities like model monitoring, governance, and lifecycle management, and ready for Production. The Model Packages include all of the information needed to monitor the models in their new environment so no reconfiguration is needed.
Monitoring Agents for Remote Models
Monitoring Agents connect remote models to the MLOps ecosystem allowing you complete freedom to choose where you deploy your models. In Release 6.0 we have added new features and additional compatible model types to our Monitoring Agents. These include:
- DataRobot AutoML CodeGen deployments can now be instrumented with an embedded Monitoring Agent, which allows these types of deployments to be easily monitored and managed using MLOps. MLOps Monitoring Agents then collect metrics from their models and relay the information to the dashboard on the MLOps Server.
- The MLOps Agent Library is now expanded to include remote R models, in addition to Python and Java.
- To provide more flexibility for our AWS customers Monitoring Agents can now spool to Amazon’s Simple Queue Service (SQS).
New Batch Prediction API
Our new Batch Prediction API is an enterprise-grade service that can handle unlimited batch scoring at incredibly high scale (100GB+). It is pre-integrated with leading cloud storage options including Amazon S3 and also supports common customer databases like MSSQL and Oracle and cloud providers like AWS, Azure, GCP and Snowflake right out-of-the-box. The Batch Prediction API allows for bidirectional streaming of scoring data for inputs and outputs. For example, data can be pulled from Snowflake and then scores can be put into S3.
The Batch Prediction API integrates seamlessly with the DataRobot AI Catalog and can pull data based on an API call to trigger the batch scoring process. It is fully integrated with MLOps service monitoring, so as the batches are processing the service health monitoring dashboard updates in real-time. The Batch Prediction API also works with both DataRobot and Custom Models that are deployed on the DataRobot Prediction Server environment.
We know this will be a big deal for our customers. Other tools allow you to make predictions but MLOps is the only product that supports queuing of jobs so the service can run overnight and automatically scales out resources to process many jobs without intervention or oversight. Our robust engine handles exceptions without stopping, provides automatic retries, and logs issues for review once the job is completed.
These capabilities make the difference between a “neat demo” and a fully hardened system that’s ready for your production environment. Data scientists no longer have to rely on IT support to run large batch scoring jobs. This saves both data science and IT time so those resources can focus on other projects.
Even More MLOps Goodness in 6.0!
In addition to the new capabilities and enhancements already mentioned, in Release 6.0 of MLOps we have a whole host of new and improved features. Here are just a few of the highlights:
Enhancements to Custom Environments
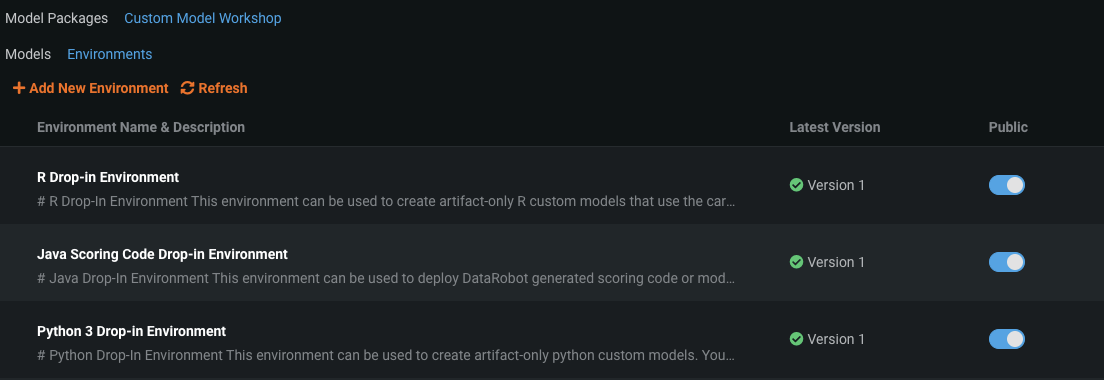
In Release 6.0 the user experience to register a custom model in MLOps is much simpler. We provide simplified, production-grade, and pre-configured environments right out-of-the-box. We also provide robust ‘drop-in’ custom environments for Python, R, and Java, that contain the necessary common libraries, packages, and dependencies to quickly and easily get your custom model deployed.
Overall User Experience and Workflow Enhancements
In Release 6.0 we have given our user experience a major overhaul. This includes:
Add Deployments Enhancements
We have made significant user experience improvements to the ‘+Add deployment’ option from the Deployments tab. This includes workflow improvements, including creating deployments using inference data, creating deployments by browsing/uploading custom inference model code and model registry from the file system, creating deployment using a custom model image from the model registry, and creating deployments by uploading model packages from the local file system.
Enhancements to Custom Inference Models
Launching a Custom Inference Model is now significantly simpler, and faster (up to 33%) in 6.0! We also have more informative audit logs and error handling for MLOps users.
Accuracy Flow Improvements
Feeding actuals back into a deployment is a tricky problem and MLOps 6.0 has made it easier. We offer an improved user experience to configure accuracy monitoring. This makes it much easier to feed back the new actuals.
Enhancements and Polish for Model Monitoring
Our model monitoring has received a lot of love in 6.0. We now provide filtering on the deployment list, and deployment charts can now be exported as PNG and downloaded directly from the UI.
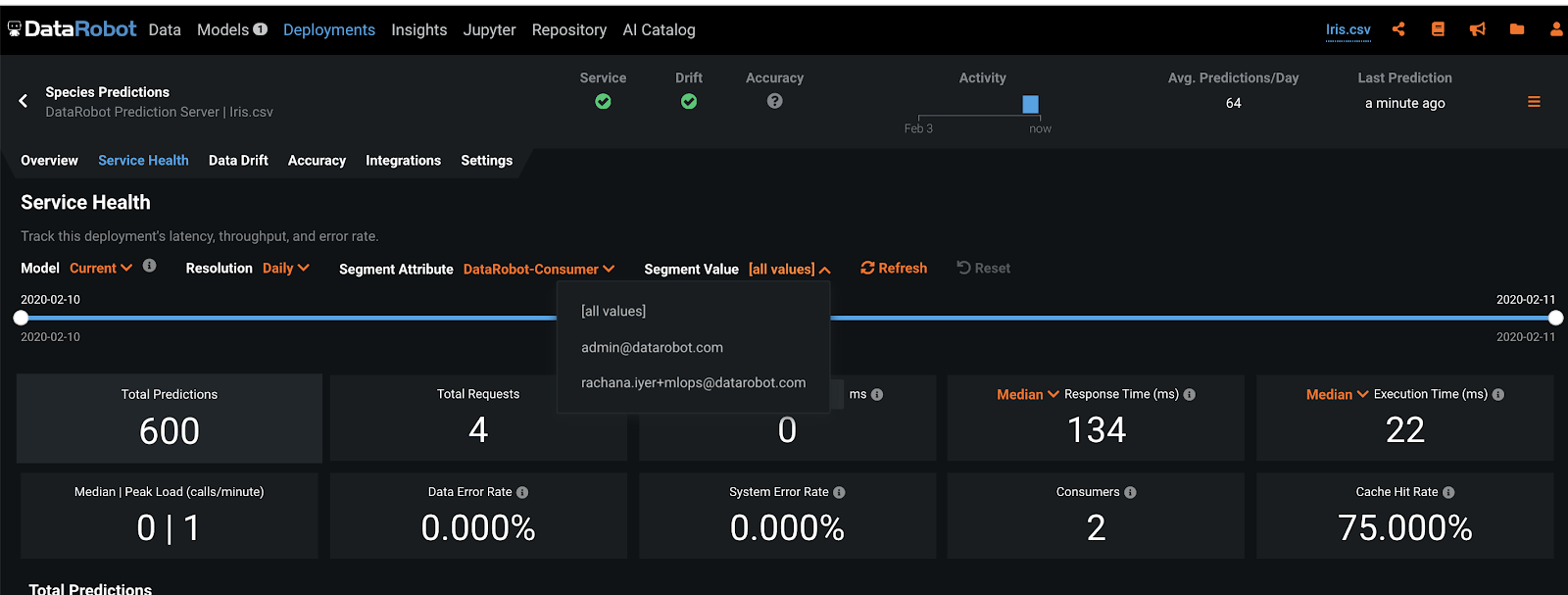
Segmented Analysis for Service Health
In 6.0 we introduce the ability to segment metrics based on Consumer, Remote IP, or Host IP. This provides for much deeper analysis of Service Health diagnostics. If a service alert is triggered it is much easier to troubleshoot the root cause of the issue and take appropriate action to mitigate risk and avoid downtime.
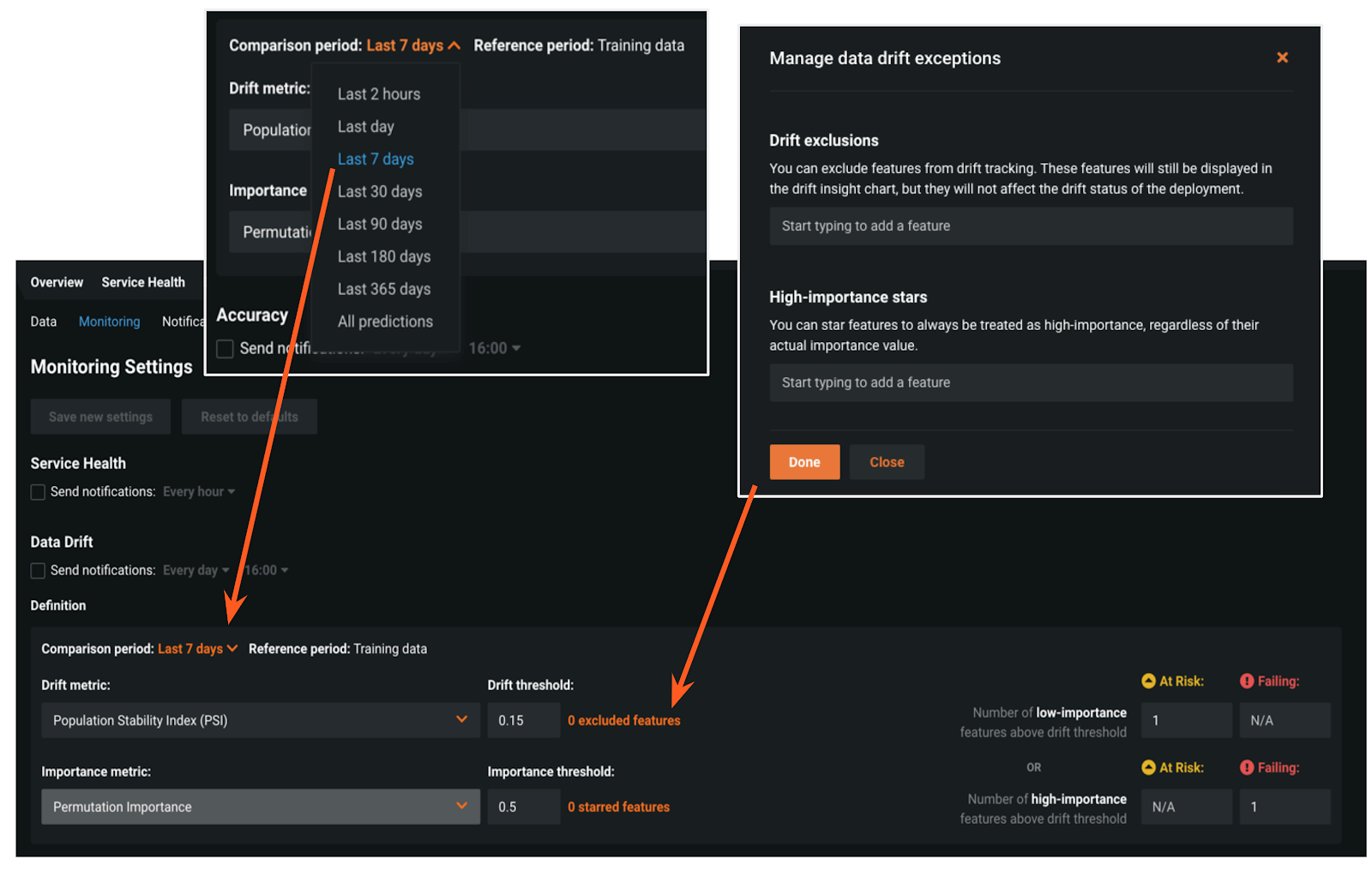
Customized Drift Status
With every release, we add more granular capabilities to create and manage custom notification policies for individual deployments. We already provide the ability to configure for accuracy thresholds, and in Release 6.0 we introduce customizable monitoring rules for drift status. Configurable from within the UI. You can manage data drift exceptions by choosing to manually exclude or include features for tracking, independent of their importance. From the familiar Monitoring UI, users can now pick from available metrics, set the reference period for alerts, and manage data drift exceptions.
Need More Info on MLOps 6.0?
If you would like to know more about MLOps 6.0 please visit our What’s New in 6.0 post in the DataRobot Community. There are tons of videos that highlight many of the new features described in this article.

DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
