

DataRobot and Project Wine: An Elegant Blend of Data Science
Getting started with the DataRobot Python API for multi-class classification

Recently, I had the opportunity to explore DataRobot. As a hardcore Pythonic data scientist, I was curious about its capabilities and wondered if it would help expedite my work. DataRobot promises automated machine learning wherein it chooses the most appropriate machine learning algorithms, automatically optimizes data preprocessing, applies feature engineering, and tunes parameters for each algorithm. It creates and ranks highly accurate models and recommends the best model to deploy for the data and prediction target. So, when the opportunity to use DataRobot presented itself, I decided to give it a try.
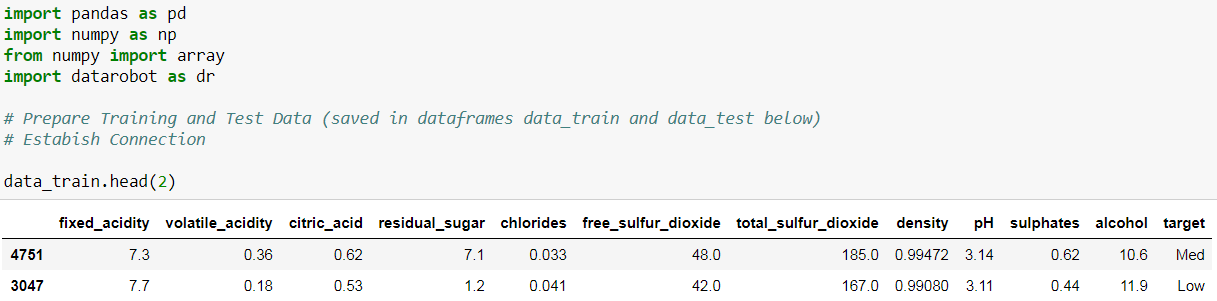
For this tutorial, I used the wine quality data set from the UCI Machine Learning Repository, a dataset that contains quality ratings (labels) for 4,898 white wine samples. These quality ratings range from 3 to 9, with 9 signifying the best quality for wine. With these distinct labels, I treated this as a multiclass classification problem. For simplicity, I transformed this into three distinct categories (Low = [3,4,5], Med = [6], High = [7,8,9]). The features are the wines’ physical and chemical properties (11 in total), and we used these physicochemical properties to predict the quality of the wine. Lastly, I split the data into two groups, a training dataset and a testing dataset, to demonstrate making predictions on new data. DataRobot expects training data in the form of a flat file. For the wine dataset used here, there was minimal preparation required and you can find the full code for this tutorial on github for the intermediate steps.
With the training data prepared and a connection established through my Python session, I created three different projects to showcase the three different modes DataRobot can work with on my data. The three modes are the full autopilot mode, the quick autopilot mode, and the manual mode. I called the three projects corresponding to the three modes: project_wine1, project_wine2, and project_wine3. Once the training process is complete, I will show how to retrieve the results from the various models and how to generate predictions on new data using a selected model.
Autopilot Mode
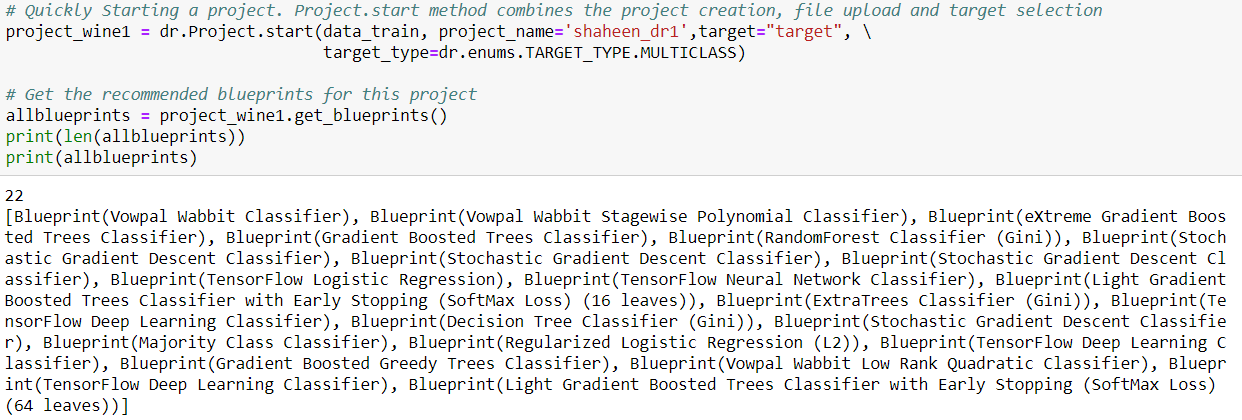
When given a dataset, DataRobot starts by recommending a set of blueprints that are appropriate for the task at hand. A blueprint is a series of steps or computation paths that a dataset will pass through before producing predictions from data. There can be multiple blueprints for the same algorithm depending on the underlying preprocessing steps, and you can leverage one or more models with their hyperparameters automatically tuned. A DataRobot model is defined by its blueprint, training data size, and set of features.
I ran the first project on full autopilot mode. In autopilot mode (which is also the default mode on DataRobot) and for this particular dataset, DataRobot generated 22 blueprints and made 28 models from these blueprints in less than half an hour!
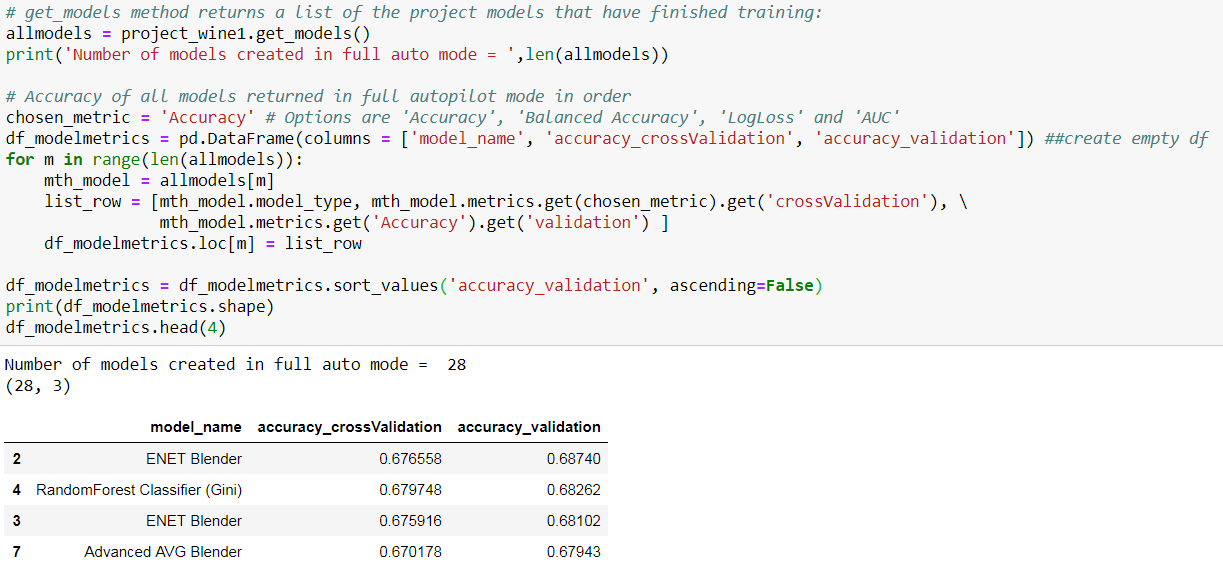
I compared all the models created using the Accuracy metric, then selected one model and examined its performance in detail. Then, I uploaded the test_data from above to get predictions using this model.
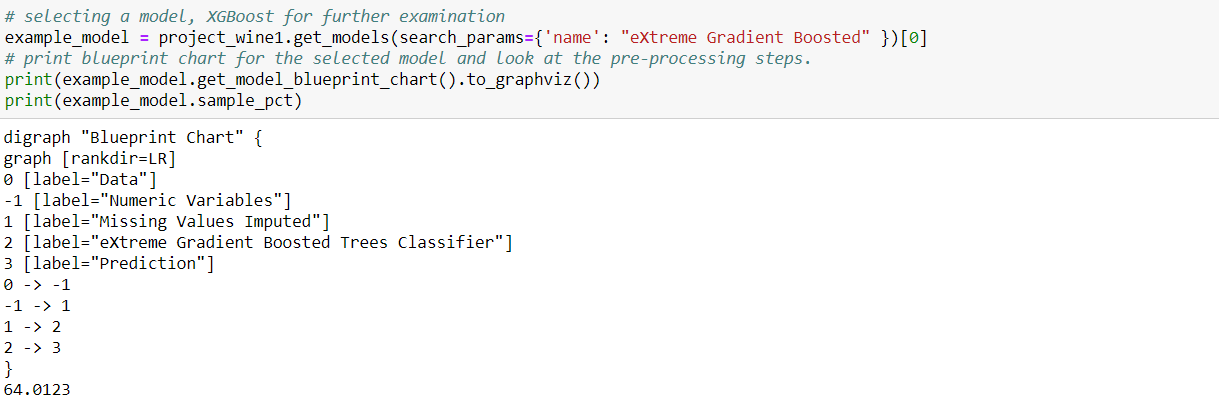
Next, I found an eXtreme Gradient Boosted model and examined the metrics of the model in detail and used it to predict for the test data.
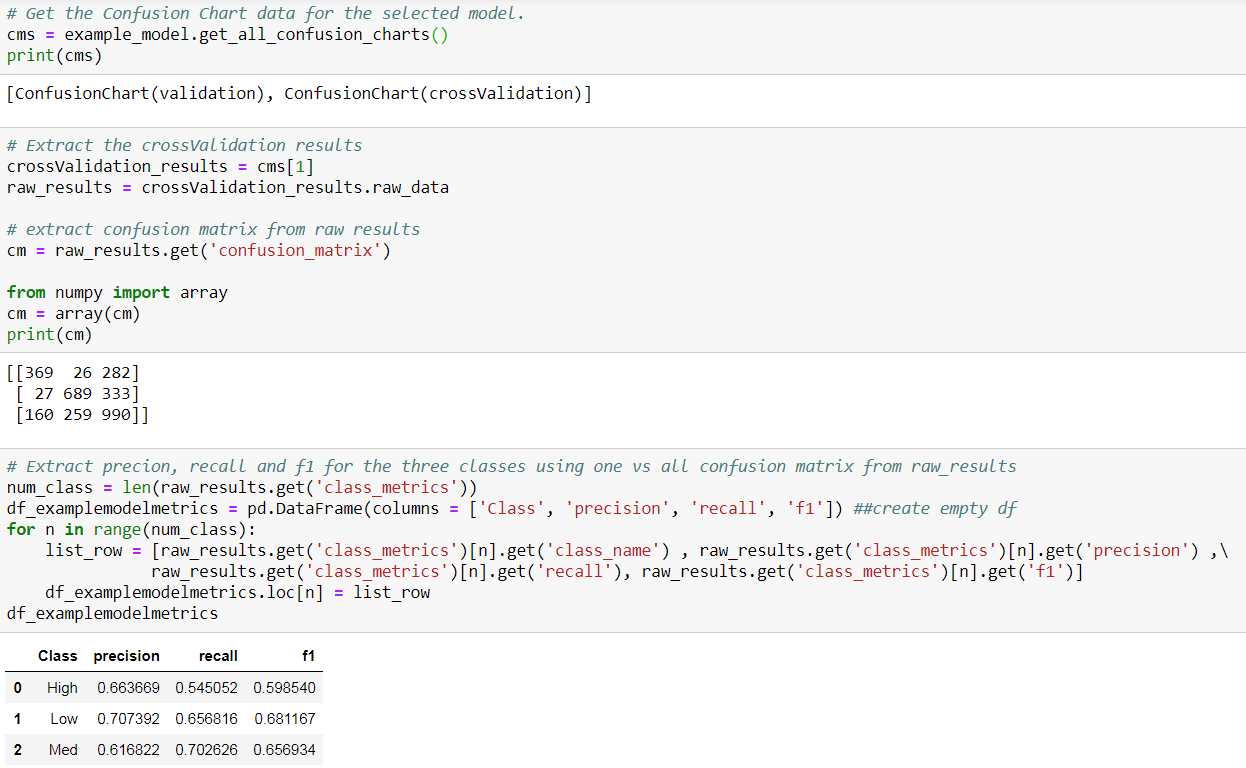
Performance on Training Data
I extracted the confusion matrix and retrieved accuracy, precision, and recall for the selected model. Note that DataRobot automatically partitions uploaded training data and reports out-of-sample performance as a good data science practice.
Performance on Test Data
Next, I wanted to investigate the performance of the selected model on test data. I uploaded the test data, started a prediction job, and retrieved the predictions.
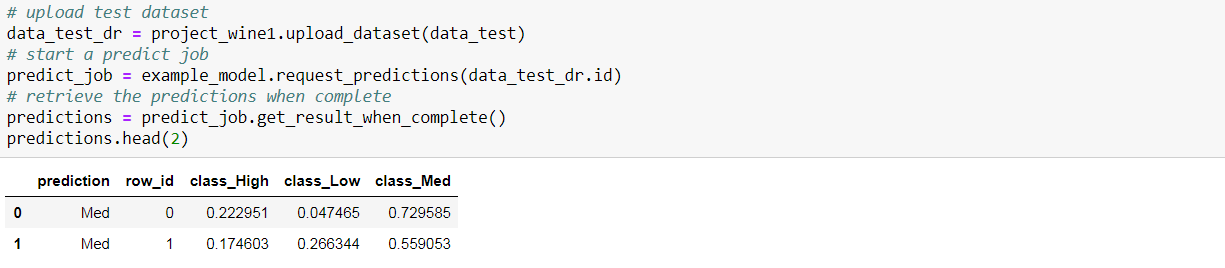
With the predictions retrieved as a data frame, the performance metrics could be easily calculated using scikit-learn.
Feature Impact
DataRobot also computes Feature Impact, a measure of the relevance of each feature in the model. A prerequisite to computing prediction explanations is that you need to compute the feature impact for your model (this only needs to be done once per model).
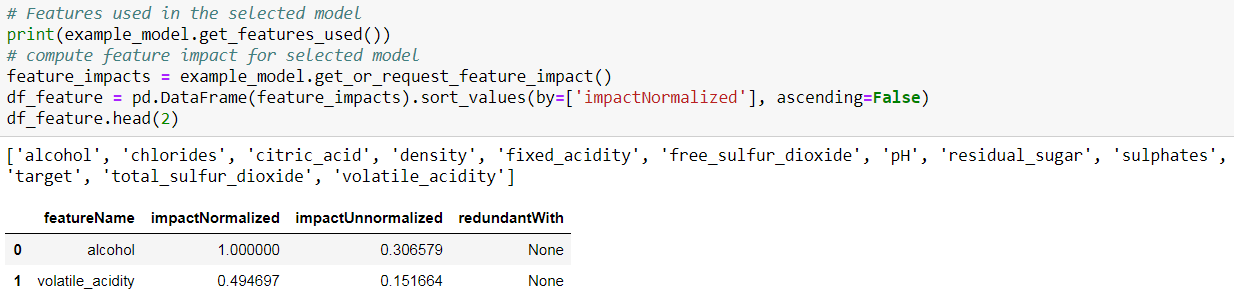
The ‘impactUnnormalized’ is how much worse the error metric score is when making predictions after randomly shuffling a given feature while keeping all others the same. The ‘impactNormalized’ is normalized so that the largest value is 1. In both cases, larger values indicate more important features. If a feature is judged to be redundant once other features are considered, then including it in the model doesn’t contribute much in terms of additional accuracy. The ‘redundantWith’ value is the name of a feature that has the highest correlation with this feature. Along with Feature Impact, DataRobot can also compute the prediction explanations for every row of the dataset.
Quick Autopilot
The quick mode (AUTOPILOT_MODE.QUICK) is for quickrun wherein we can run on a more limited set of models rather than the full recommended set of blueprints to get insights faster. In the Quick Autopilot mode, DataRobot built eight models for my data from the 22 blueprints. I selected one of the models, as shown above, to look at the performance and used it to get predictions for the test data.

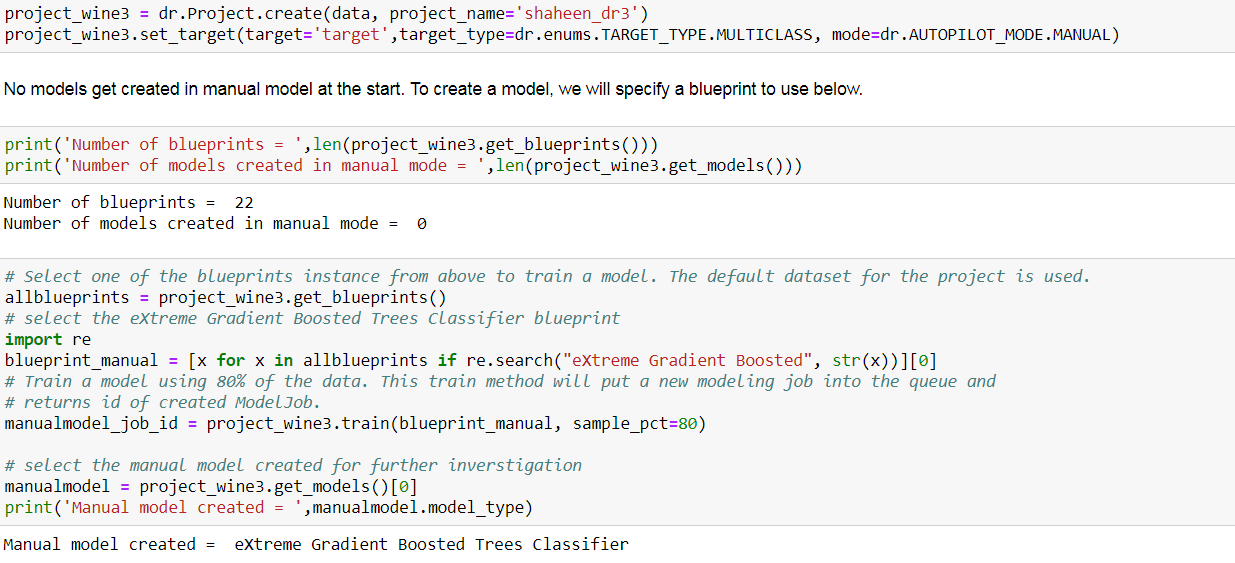
Manual Mode
In the manual mode (AUTOPILOT_MODE.MANUAL), we can select which models to execute before starting the modeling process rather than use the DataRobot autopilot. I selected the ‘eXtreme Gradient Boosted Trees Classifier’ blueprint and trained a model using this blueprint. I looked at the performance of the manual model in more detail, as I showed above, and used it for getting predictions for the test data.
Delete and Manage Projects
It is always good to clean up afterwards!

In this tutorial, I showed how to leverage DataRobot’s modeling engine and automated machine learning platform through Python API to expedite the modeling work. So far, I have been quite pleased with the functionality and was able to integrate it into my Pythonic workflow. I especially like how DataRobot internalizes all the complexity of automated machine learning and presents a clean and robust interface while maintaining transparency and explainability. I hope this was helpful in understanding how DataRobot works and facilitates in integrating its rich functionality in your Pythonic workflow.

Shaheen is an AI communicator, an intelligent solution enabler, and a data scientist by profession. She helps enterprises build and deploy predictive solutions to best leverage their data and empowers them to achieve more through technology and AI. She is a climate scientist and physicist by training and serves on the advisory board for Data Analytics at Tufts University Graduate School of Arts and Sciences. Find her on Twitter, @Shaheen_Gauher.
-
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read
Latest posts
