

Best Practices in Machine Learning Infrastructure
This article was originally published at Algorithimia’s website. The company was acquired by DataRobot in 2021. This article may not be entirely up-to-date or refer to products and offerings no longer in existence. Find out more about DataRobot MLOps here.

Developing processes for integrating machine learning within an organization’s existing computational infrastructure remains a challenge for which robust industry standards do not yet exist. But companies are increasingly realizing that the development of an infrastructure that supports the seamless training, testing, and deployment of models at enterprise scale is as important to long-term viability as the models themselves.
Small companies, however, struggle to compete against large organizations that have the resources to pour into the large, modular teams and processes of internal tool development that are often necessary to produce robust machine learning pipelines.
Luckily, there are some universal best practices for achieving successful machine learning model rollout for a company of any size and means.
The Typical Software Development Workflow
Although DevOps is a relatively new subfield of software development, accepted procedures have already begun to arise. A typical software development workflow usually looks something like this:
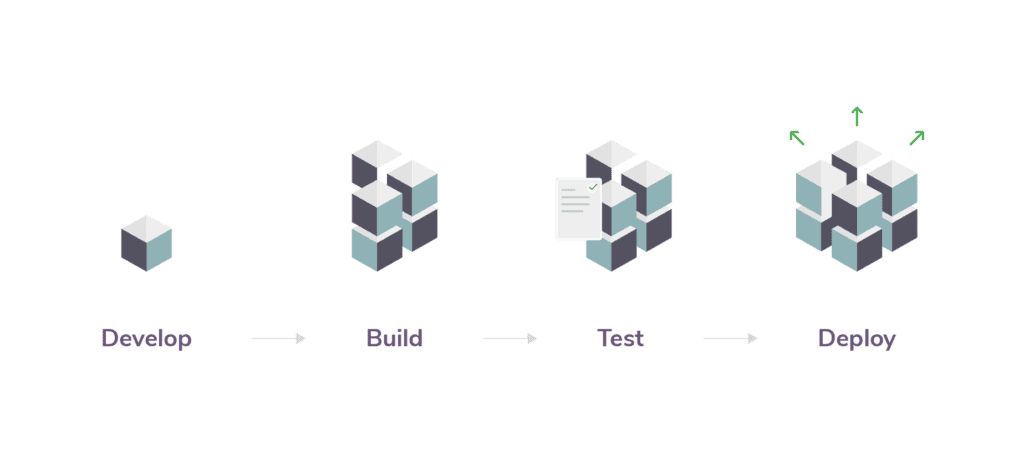
This is relatively straightforward and works quite well as a standard benchmark for the software development process. However, the multidisciplinary nature of machine learning introduces a unique set of challenges that traditional software development procedures weren’t designed to address.
Machine Learning Infrastructure Development
If you were to visualize the process of creating a machine learning model from conception to production, it might have multiple tracks and look something like these:
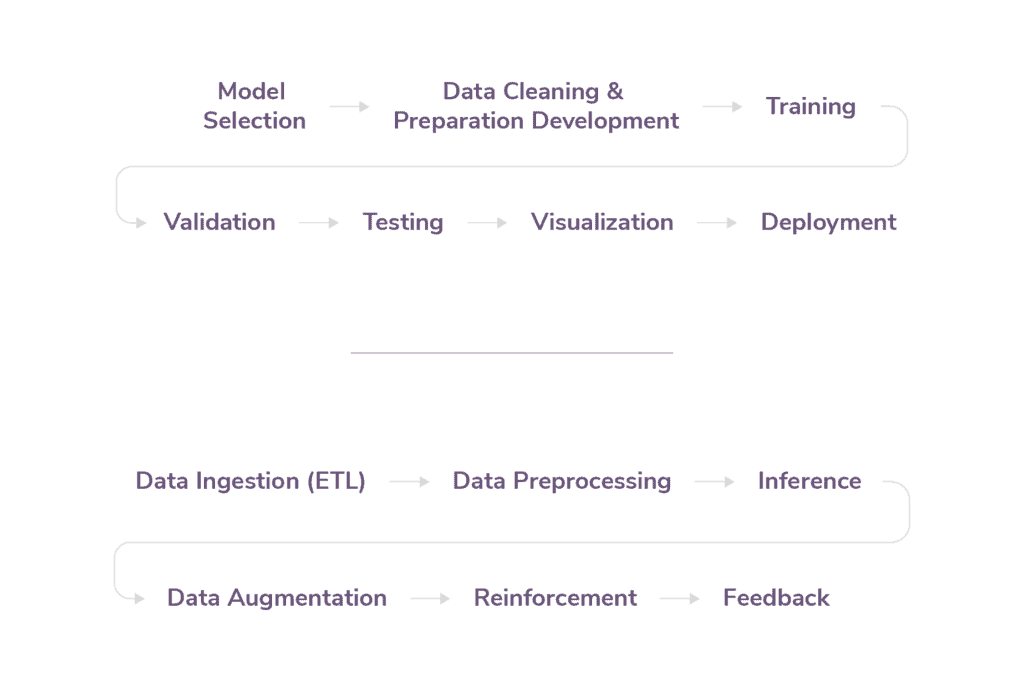
Data Ingestion
It all starts with data.
Even more important to a machine learning workflow’s success than the model itself is the quality of the data it ingests. For this reason, organizations that understand the importance of high-quality data put an incredible amount of effort into architecting their data platforms. First and foremost, they invest in scalable storage solutions, be they on the cloud or in local databases. Popular options include Azure Blob, Amazon S3, DynamoDB, Cassandra, and Hadoop.
Often finding data that conforms well to a given machine learning problem can be difficult. Sometimes datasets exist, but are not commercially licensed. In this case, companies will need to establish their own data curation pipelines whether by soliciting data through customer outreach or through a third-party service.
Once data has been cleaned, visualized, and selected for training, it needs to be transformed into a numerical representation so that it can be used as input for a model. This process is called vectorization. The selection process for determining what’s important in the dataset for training is called featurization. While featurization is more of an art then a science, many machine learning tasks possess associated featurization methods that are commonly used in practice.
Since common featurizations exist and generating these features for a given dataset takes time, it behooves organizations to implement their own feature stores as part of their machine learning pipelines. Simply put, a feature store is just a common library of featurizations that can be applied to data of a given type.
Having this library accessible across teams allows practitioners to set up their models in standardized ways, thus aiding reproducibility and sharing between groups.
Model Selection
Current guides to machine learning tend to focus on standard algorithms and model types and how they can best be applied to solve a given business problem.
Selecting the type of model to use when confronted with a business problem can often be a laborious task. Practitioners tend to make a choice informed by the existing literature and their first-hand experience about which models they’d like to try first.
There are some general rules of thumb that help guide this process. For example, Convolutional Neural Networks tend to perform quite well on image recognition and text classification, LSTMs and GRUs are among the go-to choices for sequence prediction and language modeling, and encoder-decoder architectures excel on translation tasks.
After a model has been selected, the practitioner must then decide which tool to implement the chosen model. The interoperability of different frameworks has improved greatly in recent years due to the introduction of universal model file formats such as the Open Neural Network eXchange (ONNX), which allow for the porting of models trained in one library to be exported for use in another.
What’s more, the advent of machine learning compilers such as Intel’s nGraph, Facebook’s Glow, or the University of Washington’s TVM promise the holy grail of being able to specify your model in a universal language of sorts and have it be compiled to seamlessly target a vast array of different platforms and hardware architectures.
Model Training
Model training constitutes one of the most time consuming and labor-intensive stages in any machine learning workflow. What’s more, the hardware and infrastructure used to train models depends greatly on the number of parameters in the model, the size of the dataset, the optimization method used, and other considerations.
In order to automate the quest for optimal hyperparameter settings, machine learning engineers often perform what’s called a grid search or hyperparameter search. This involves a sweep across parameter space that seeks to maximize some score function, often cross-validation accuracy.
Even more advanced methods exist that focus on using Bayesian optimization or reinforcement learning to tune hyperparameters. What’s more, the field has recently seen a surge in tools focusing on automated machine learning methods, which act as black boxes used to select a semi-optimal model and hyperparameter configuration.
After a model is trained, it should be evaluated based on performance metrics including cross-validation accuracy, precision, recall, F1 score, and AUC. This information is used to inform either further training of the same model or the next iterate in the model selection process. Like all other metrics, these should be logged in a database for future use.
Visualization
Model visualization can be integrated at any point in the machine learning pipeline, but proves especially valuable at the training and testing stages. As discussed, appropriate metrics should be visualized after each stage in the training process to ensure that the training procedure is tending towards convergence.
Many machine learning libraries are packaged with tools that allow users to debug and investigate each step in the training process. For example, TensorFlow comes bundled with TensorBoard, a utility that allows users to apply metrics to their model, view these quantities as a function of time as the model trains, and even view each node in a neural network’s computational graph.
Model Testing
Once a model has been trained, but before deployment, it should be thoroughly tested. This is often done as part of a CI/CD pipeline. Each model should be subjected to both qualitative and quantitative unit tests. Many training datasets have corresponding test sets which consist of hand-labeled examples against which the model’s performance can be measured. If a test set does not yet exist for a given dataset, it can often be beneficial for a team to curate one.
The model should also be applied to out-of-domain examples coming from a distribution outside of that on which the model was trained. Often, a qualitative check as to the model’s performance, obtained by cross-referencing a model’s predictions with what one would intuitively expect, can serve as a guide as to whether the model is working as hoped.
For example, if you trained a model for text classification, you might give it the sentence “the cat walked jauntily down the street, flaunting its shiny coat” and ensure that it categorizes this as “animals” or “sass.”
Deployment
After a model has been trained and tested, it needs to be deployed in production. Current practices often push for the deploying of models as microservices, or compartmentalized packages of code that can be queried through and interact via API calls.
Successful deployment often requires building utilities and software that data scientists can use to package their code and rapidly iterate on models in an organized and robust way such that the backend and data engineers can efficiently translate the results into properly architected models that are deployed at scale.
For traditional businesses, without sufficient in-house technological expertise, this can prove a herculean task. Even for large organizations with resources available, creating a scalable deployment solution is a dangerous, expensive commitment. Building an in-house solution like Uber’s Michelangelo just doesn’t make sense for any but a handful of companies with unique, cutting-edge ML needs that are fundamental to their business.
Fortunately, commercial tools exist to offload this burden, providing the benefits of an in-house platform without signing the organization up for a life sentence of proprietary software development and maintenance.
Algorithmia’s AI Layer allows users to deploy and serve models from any framework, language, or platform and connect to most all data sources. We scale model inference on multi-cloud infrastructures with high efficiency and enable users to continuously manage the machine learning life cycle with tools to iterate, audit, secure, and govern.
No matter where you are in the machine learning life cycle, understanding each stage at the start and what tools and practices will likely yield successful results will prime your ML program for sophistication. Challenges exist at each stage, and your team should also be primed to face them.
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
