


AI Use Cases for Cyber and Malware Analysts
Introduction
Cyber and malware analysts have a critical role in detecting and mitigating cyberattacks. These professions are highly skilled in programming, complex tools, and investigations. They are termed unicorns because they are so rare. Experienced ones are hard to find and retain, and typically swarmed with ad-hoc requests.
A reliable partner for cybersecurity analysts is AI and machine learning. There is a long history of identifying malicious software. It’s possible to use this history to build models that allow for an integrated automation pipeline to detect, understand, and remove cyber threats with minimum human intervention.
In this post, we show you how to build a malware detection model using the largest known dataset, SOREL-20M (Sophos/ReversingLabs-20 Million). SOREL-20M is a large-scale dataset of 20 million files. The full size is eight terabytes and can be challenging to work with. We show how to use DataRobot’s AutoML to build models on this dataset.
Background on Cybersecurity
Generally, AI and machine learning (e.g., classification, anomaly detection, time series anomaly detection) can help cyber and malware analysts’ everyday work through the following types of use cases:
- Malicious Software or File (Malware) — Analyze if a given software is malware, why, and what malware family it belongs to
- Address or Domain — Identify anomalies for incoming and outgoing connections, made to a specific address or domain that appears to be malicious
- Email or Message — Evaluate content and/or attachments within an email or a message and can identify if this is likely a part of a phishing or spam campaign
- Protocol — Predict if there is anything unusual about network traffic monitored
- Alert — Identify alerts that are related within the massive volume of alerts being processed by the cyber solutions
- Insider Threat — Detect and predict personnel who require enhanced monitoring or evaluation to prevent insider threat
- Hacker — Finding topics and trends from the knowledge and assets that hackers share with each other
Malware Use Case
Let’s do a deeper dive on a malware use case, starting with a quick introduction to malware and malware analysis:
- Malware’s purpose is to damage data and systems, and steal information including data, credentials, crypto-wallets, and so on
- Static malware analysis collects information about malware without running it
- Dynamic malware analysis collects information about malware after running it in a sandbox
AI and machine learning can use in-house and/or external training data and outcomes. They are collected from static and dynamic malware analysis (e.g., SoReL-20M, YARA, Cuckoo Sandbox, VirusTotal etc), to build models and make predictions on whether a software is malicious or not. Classification and anomaly detection models can be trained to find more of what is already known.
SoReL-20M Malware Data
Several important, publicly available, malware benchmark datasets exist. The largest and most recent is SoReL-20M.1 Comprising both malicious and benign Windows files, SoReL-20M has about 12.7 million training, 2.5 million validation, and 4.2 million test samples, where around 60%, 40%, and 30%, respectively, are malicious.
Each SoReL-20M sample has close to 2.4K features. It has labels (malicious, benign, or unlabelled), parsed values, and format-agnostic histograms that are extracted using static malware analysis.
Before modeling, we prepared SoReL-20M data (specifically EMBER-v2 features2) on a commercial cloud. Using bash and Python scripts, we did the following:
- Converted the npz file to csv.
- Combined training and validation samples together as a single train dataset.
- Subsetted both train and test datasets using reservoir sampling.
SoReL-20M AutoML Results
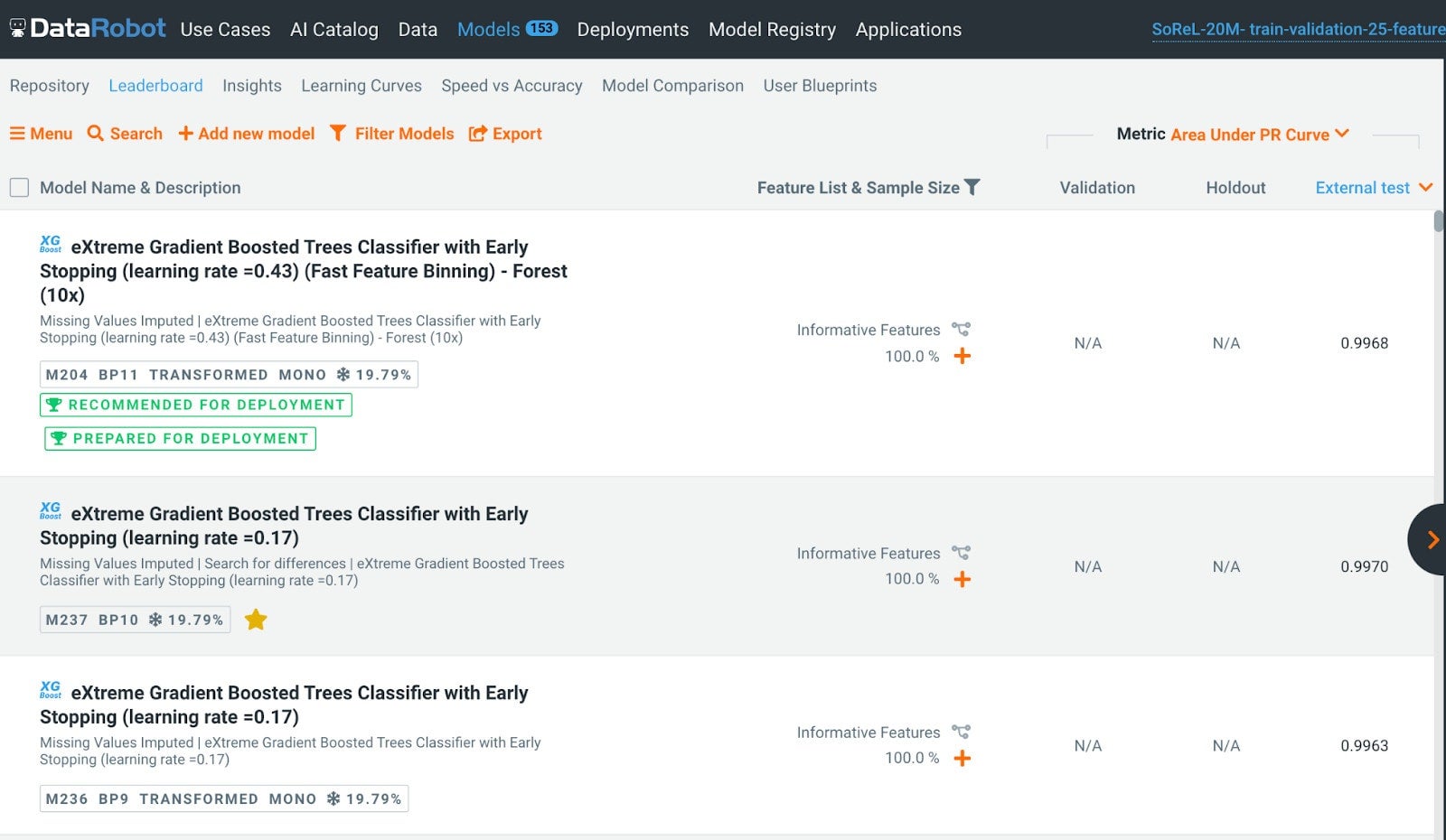
Using DataRobot’s AutoML product, we conducted initial binary classification experiments with several hundred models. With reference to the results table below, our XGBoost and lightGBM models achieved near-perfect accuracy. This is about the same AUC accuracy level (0.997-0.998) as in the SoReL-20M paper.1 The table below shows the results using both Area Under ROC Curve (AUC) and Area Under Precision-Recall Curve (AUPRC) on 1% of the test set.
When working with large datasets, starting with small samples saves time, can yield good accuracy, and helps to determine the best features. After that, we can use the entire train dataset with only the best features, and in the case of SoReL-20M, it does give the best accuracy at a much faster speed. The table here shows how the final model started by building a model on 1% of the data and identifying the best set of features. The final step was then to train a model on all the data for those features. This technique saves a lot of time, but still builds a state-of-the-art malware model.

Conclusions
Our initial SoReL-20M results are excellent, but we can do more. First, we emphasized building an accurate model quickly; however, with more time, it would be possible to conduct more experiments on the full train and test sets, and additional malware datasets.3 Second, EMBER-v2 feature names were not provided at experiment time, so it was not possible to understand why a software is classified as malware. Third, for future work, we can consider using anomaly detection on only the benign samples, and multi-classification on behavioral tags (e.g., adware, flooder, ransomware etc) as labels to predict malware types. Finally, to operationalize this model, we could now use DataRobot’s MLOps product, the models to deploy and monitor the model as part of a pipeline, for example, scan new files in a server or attachments in emails.
If you’re interested in using AutoML, tour the DataRobot AI Platform. To request a malware detection demo shown in the following screenshot, contact us, and we’ll explore a proof of value together.
References
- SoReL-20M: A Large Scale Benchmark Dataset for Malicious PE Detection, R Harang, EM Rudd – arXiv preprint arXiv:2012.07634, 2020.
- EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models, HS Anderson, P Roth – arXiv preprint arXiv:1804.04637, 2018.
- Free Malware Sample Sources for Researchers, Accessed on May 2, 2021.

Clifton is a Customer Facing Data Scientist (CFDS) at DataRobot working in Singapore and leads the Asia Pacific (APAC)’s CFDS team. His vertical domain expertise is in banking, insurance, government; and his horizontal domain expertise is in cybersecurity, fraud detection, and public safety. Clifton’s PhD and Bachelor’s degrees are from Clayton School of Information Technology, Monash University, Australia. In his free time, Clifton volunteers professional services to events, conferences, and journals. Was also part of teams which won some analytics competitions.

Eu Jin is a Data Scientist (CFDS) at DataRobot, and his role is to help customers solve complex data science problems and achieve value from DataRobot. He has a masters degree in Econometrics at Monash University, Australia. In his free time, Eu Jin competes in Data Science competition, whenever his 3 year old son allows him to.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
