

AI Experience San Francisco: Highlights from Farmers Insurance Group, Airbnb, and Adobe
AI is one of the hottest topics in Silicon Valley (and beyond). On Tuesday, June 12 at the AI Experience roadshow, hundreds of curious Bay Area executives, analysts, and data scientists were on hand at the W Hotel San Francisco to see for themselves just what it means to be an AI-driven enterprise. And thanks to a trio of DataRobot users, those attendees were able to witness firsthand how automated machine learning is helping their organizations realize that AI-driven vision.

Yashar Mehdad (Airbnb), Scot Barton (Farmers Insurance), Gourab De (DataRobot), Rob Liebscher (Adobe)
Speaker 1: Scot Barton, Head of Business Insurance R&D at Farmers Insurance
Scot has always understood the potential for applying data science to the vast amount of available data within the insurance industry, and how that can yield powerful results for use cases like pricing, claims processing, and customer service. But there was always one important data source that eluded Scot and his data science team…until they started using DataRobot:
Text analysis.
Computers do a great job of processing numerical data, but when it comes to analyzing words and text — commonly found in insurance applications— they struggle. Scot warns that data science teams can’t even consider including text data, an untapped resource in building models, until they have the maturity to work with Ensemble Models, something DataRobot automatically generates.
For Scot and Farmers Insurance, DataRobot is a tool that even a junior data scientist on his team can use to make predictions, present findings, and accelerate the business conversation.
In his presentation, Scot dove into some of the complexities of text analysis — word order, context, punctuation, stemming, stop words— and shared his solutions for solving those issues. For example, text from surveys can be stemmed (i.e. “conference” and “conferences” treated the same) and stop words removed (i.e. words like “the” and “this”). The remaining words can then be tokenized — turned into a table containing 1s and 0s — and a vector created for each survey record. Using these approaches, Scot’s team can clean up and prepare text data, and then input that data into predictive models.
As Scot explained, text analysis typically takes many time-consuming steps, which turns it into a whole separate project. By using DataRobot’s automated machine learning platform, text analysis becomes just “an extra button to push”:
Typical Text Analytics Steps |
With DataRobot |
| Research R/Python Packages | Automated |
| Install and Config Packages | Automated |
| Get Vocabulary Dataset | Automated |
| Train Library / Vectors | Automated |
| Load Modeling Dataset | Manual |
| Cleanup – Stem words | Automated |
| Cleanup – Remove Stopwords | Automated |
| Decide which models to run | Automated |
| Run Models | Automated |
| Analyze Results | Manual |
| Consider Ensembles | Automated |
Automating the steps above with DataRobot means that a typical text analytics modeling project now takes Scot and his team days, rather than the weeks the manual approach demanded. The time and productivity savings over manual processes frees up his limited pool of data scientists to work on more challenging and creative data science projects.
DataRobot isn’t just useful for Scot in automating tedious manual processes. One of the helpful byproducts of using DataRobot is in communicating data science findings to a business audience. For example, by using DataRobot’s Word Cloud (sample below), Scot’s team can present findings that show how frequently a word appears in the dataset (indicated by the size of the word), and whether it is predictive or not (indicated by a red or blue coloring). The Word Cloud is a quick way to visualize how much impact certain words have on the predictive power of the model.
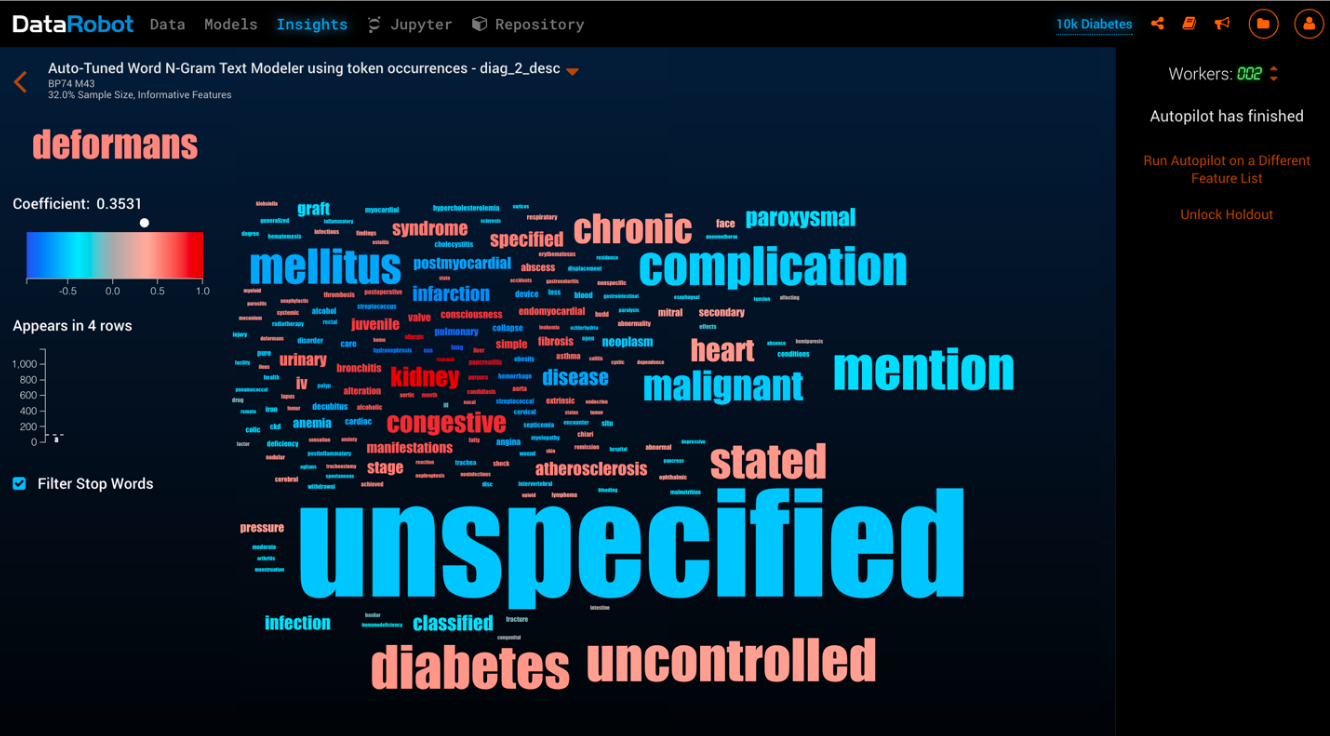
For Scot and Farmers Insurance, DataRobot is a tool that even a junior data scientist on his team can use to make predictions, present findings, and accelerate the business conversation.
Speaker 2: Yashar Mehdad, Data Science Manager at Airbnb
Yashar has been doing data science for, in his own words, “a long time.” Back when he was just getting started, automation was largely non-existent, which meant there were a lot of manual processes for Yashar to perform before he could get to production. This greatly limited his capacity to build and run a lot of models.
When he started using DataRobot’s automated machine learning platform, Yashar quickly discovered that his ability to define, develop, and complete machine learning projects greatly increased.
According to Yashar, he discovered that DataRobot was particularly good for:
- Increased productivity and time savings
- Setting baselines, a process that used to take him weeks, now takes just a few hours
- Parameter optimization experiments
- Offline analysis and evaluation
- Useful R & Python APIs
- Collaboration among his team of data scientists, as well as sharing results with business operators across his organization
Most critically, DataRobot helped address the unmet demand for truly talented data science resources by incorporating the expertise of top data scientists and automating much of the “grunt work” required by traditional processes.
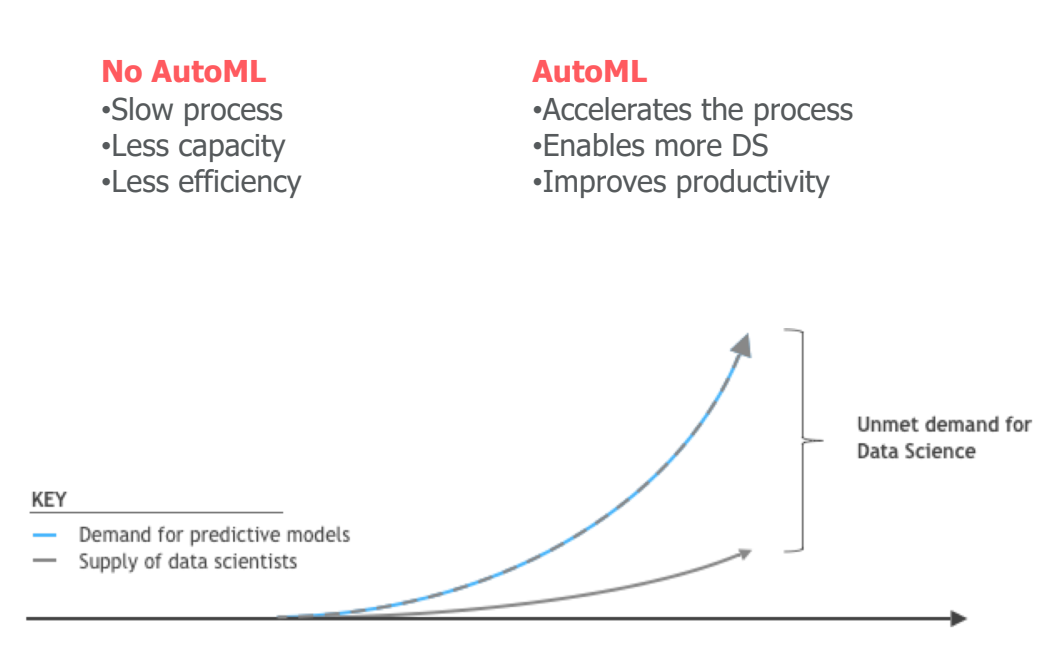
Those benefits quickly lent themselves to a long list of machine learning projects and initiatives across Airbnb, spearheaded by Yashar and his team. Yashar encouraged different departments to pursue machine learning projects that could deliver substantial ROI, effectively democratizing data science across the organization. At Airbnb, DataRobot is used for projects ranging from pricing adjustments and sales forecasting to merchandising operations and customer personalization.
For his presentation, Yashar took a deep dive into one use case: segmentation and routing optimization at Airbnb’s customer support team. Customer support is a massively important function at Airbnb, receiving a great deal of attention… and investment. Any initiatives that help the Customer Support team save money or improve efficiency are critical, and segmentation and routing optimization is one such project that has delivered huge value.
Customer support at Airbnb is split up into two groups: trip agents and non-trip agents. Customers that are presently on a trip have problems that are much more urgent and complex, and need to be dealt with as a matter of top priority. Support tickets for non-trip customers are of a less critical nature. When customers call or file a support ticket, the tickets gets routed into the appropriate group Occasionally, tickets will get escalated from non-trip to trip, and on average, each escalation costs 50% more agent time. Being able to reduce unnecessary escalation whenever possible— by making sure the initial routing is accurate— can save Airbnb a few million dollars each year.
After identifying the most accurate model and tweaking and tuning within DataRobot, Yashar and team decided to do an experiment on 5% of live tickets, and the team saw significant improvement over the old model.
To solve this issue, Yashar and team decided to migrate from a rigid rules-based routing model to a more sophisticated and contextual machine learning model. The team collected historical data and created a dataset from tickets created and closed in both groups, including features like caller user features, reservation counterpart characteristics, historical cancellation, and more.
After bringing the data into DataRobot, and choosing escalation as predictor, the platform quickly tested the data against dozens of appropriate models to see how well they would predict if a call should have been escalated or not. After identifying the most accurate model and tweaking and tuning within DataRobot, Yashar and team decided to do an experiment on 5% of live tickets, and the team saw significant improvement over the old model. So, they decided to roll it out across all 100% of the support tickets.
The initial launch of the new model led to what Yashar described as a month of firefighting, with his team combing through the model and the data. The mass launch did not perform as well as the sample-set experiment; part of the problem was that they were missing some valuable contextual data in the dataset. Yashar and his team sifted through a lot of noise in the data to clean it up and find the signal, before going back to tweak the model several more times. When it was finally sent to production, their new and improved model greatly improved segmentation and routing of escalated tickets.
Yashar learned several lessons in working through this project, including the importance of:
- Educating yourself on important metrics — It’s extremely important for data scientists to work closely with business experts who are more familiar with the intricacies of a particular problem.
- Data quality— If you put garbage in, you’ll get garbage out. Know your data, and have an understanding of what is signal and what is noise.
- Being open-minded — It’s not always what you have in mind initially. It’s ok to formulate hypotheses, but don’t go into a project with rigid, preconceived notions. Accept the fact that you don’t know everything.
- Understanding that modeling is only a part of your job as a data scientist — Yashar stressed this as his most critical lesson learned. Many data scientists are so focused on building one model and moving on to the next that they miss the forest for the trees. It’s important for them to spend time understanding the data they’re putting into the model.
Most importantly, it is critical for data scientists to understand the business value of the projects they work on. An automated machine learning platform like DataRobot is a great tool, but data scientists have to go above and beyond the tool. As Yashar put it, they have to be better than a machine. What value does a human add to this model created by a machine? Can you communicate that business value and predictive findings clearly and impactfully to the rest of your organization?
Speaker 3: Rob Liebscher, Senior Data Scientist at Adobe
For Rob and his team at Adobe, their work with DataRobot was based on addressing one of the most famous quotes in marketing:
“Half the money I spend on advertising is wasted. The trouble is, I don’t know which half.” — John Wanamaker
An age-old problem that every marketing department faces is that of attribution: determining where you’re spending your marketing dollars and which channels are returning the most on your investment. There are a variety of multi-touch marketing attribution models — for each customer, every conversion event and touchpoint along the journey to a sale is considered — as shown in this table:
Paid Search |
Display Ad |
Email click |
Trade Show |
Web Visit |
|
| Last Touch | 0% | 0% | 0% | 0% | 100% |
| First Touch | 100% | 0% | 0% | 0% | 0% |
| Linear | 20% | 20% | 20% | 20% | 20% |
| Positional | 35% | 10% | 10% | 10% | 35% |
| Time Decay | 14% | 17% | 20% | 23% | 26% |
| Algorithmic | 23% | 13% | 11% | 45% | 9% |
All the models are imperfect and subjective, each incomplete in painting the overall marketing attribution picture. The most accurate type of model is algorithmic, and to get there, Adobe leaned on DataRobot.
Rob and team set out to build a model for conversion based on marketing touches. Focusing primarily at the top of Adobe’s enterprise funnel, the model would consider all of the marketing touches that create leads and convert those leads to Marketing Qualified Leads, before they are accepted by an Account Development Manager in Sales. After collecting their dataset and building the model, Rob found that the initial baseline model was just ok in terms of accuracy. However, when they added contextual information to the dataset — variables such as job title, functional area, vertical, company size and location — the models’ accuracy improved substantially.
Rob then applied his model to the Shapley Value method, an approach to marketing attribution derived from a concept of cooperative game theory. The general purpose of the Shapley Value method is to fairly distribute credit or value across different individuals or, in the case of marketing, different channels. This methodology is valued because it’s much better and more accurate at measuring actual contributions than Last Touch, Linear, or the other attribution methods above. It’s also model-agnostic, working equally well with a variety of different types of predictive models.
When comparing the percentage attribution breakdown with the actual dollar spend for each channel, Rob’s team now had a clear picture of what was working, and where Adobe should focus their marketing efforts going forward.
For most marketers attempting to implement the Shapley Value method, there’s a great deal of manual calculation required to determine baselines for marginal contributions. However, according to Rob, with tools like DataRobot, it becomes very simple to implement. After setting a baseline, simulating scenarios (starting with two-touchpoint attribution), computing the average scenario, and then computing contributions across a variety of different channels, Rob’s team was able to deliver a full and accurate attribution breakdown of marketing efficacy at Adobe. When comparing the percentage attribution breakdown with the actual dollar spend for each channel, Rob’s team now had a clear picture of what was working, and where Adobe should focus their marketing efforts going forward.
A Common Theme
At the AI Experience, all three speakers discussed the importance of data scientists to the process, and each of them ended their presentation by announcing that their respective companies were hiring data scientists. While DataRobot has done wonders in democratizing data science across these organizations and addressing the lack of available data science resources — allowing them to continue working machine learning projects efficiently and effectively — data scientists remain critical… and rare. With previously manual processes now automated, data scientists at Farmers Insurance, Airbnb, and Adobe were now freed up to do more creative and challenging data science projects, befitting their skills and expertise.
The next stop for AI Experience is in New York City on June 20th. We hope to see you there!

Gareth Goh is the Customer Marketing Manager at DataRobot. He was previously the Web Director at DataRobot, and has also worked at several different tech startups in the Boston area in various marketing roles. Gareth has an M.S. in International Relations and a B.S. in Journalism from Boston University.
-
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read
Latest posts
